| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
|
|
Part of #87059
Preview it at: https://notriddle.com/notriddle-rustdoc-test/rustdoc-sidebar-header/std/index.html
|
|
CTFE/Miri engine Pointer type overhaul
This fixes the long-standing problem that we are using `Scalar` as a type to represent pointers that might be integer values (since they point to a ZST). The main problem is that with int-to-ptr casts, there are multiple ways to represent the same pointer as a `Scalar` and it is unclear if "normalization" (i.e., the cast) already happened or not. This leads to ugly methods like `force_mplace_ptr` and `force_op_ptr`.
Another problem this solves is that in Miri, it would make a lot more sense to have the `Pointer::offset` field represent the full absolute address (instead of being relative to the `AllocId`). This means we can do ptr-to-int casts without access to any machine state, and it means that the overflow checks on pointer arithmetic are (finally!) accurate.
To solve this, the `Pointer` type is made entirely parametric over the provenance, so that we can use `Pointer<AllocId>` inside `Scalar` but use `Pointer<Option<AllocId>>` when accessing memory (where `None` represents the case that we could not figure out an `AllocId`; in that case the `offset` is an absolute address). Moreover, the `Provenance` trait determines if a pointer with a given provenance can be cast to an integer by simply dropping the provenance.
I hope this can be read commit-by-commit, but the first commit does the bulk of the work. It introduces some FIXMEs that are resolved later.
Fixes https://github.com/rust-lang/miri/issues/841
Miri PR: https://github.com/rust-lang/miri/pull/1851
r? `@oli-obk`
|
|
Update Rust Float-Parsing Algorithms to use the Eisel-Lemire algorithm.
# Summary
Rust, although it implements a correct float parser, has major performance issues in float parsing. Even for common floats, the performance can be 3-10x [slower](https://arxiv.org/pdf/2101.11408.pdf) than external libraries such as [lexical](https://github.com/Alexhuszagh/rust-lexical) and [fast-float-rust](https://github.com/aldanor/fast-float-rust).
Recently, major advances in float-parsing algorithms have been developed by Daniel Lemire, along with others, and implement a fast, performant, and correct float parser, with speeds up to 1200 MiB/s on Apple's M1 architecture for the [canada](https://github.com/lemire/simple_fastfloat_benchmark/blob/0e2b5d163d4074cc0bde2acdaae78546d6e5c5f1/data/canada.txt) dataset, 10x faster than Rust's 130 MiB/s.
In addition, [edge-cases](https://github.com/rust-lang/rust/issues/85234) in Rust's [dec2flt](https://github.com/rust-lang/rust/tree/868c702d0c9a471a28fb55f0148eb1e3e8b1dcc5/library/core/src/num/dec2flt) algorithm can lead to over a 1600x slowdown relative to efficient algorithms. This is due to the use of Clinger's correct, but slow [AlgorithmM and Bellepheron](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.45.4152&rep=rep1&type=pdf), which have been improved by faster big-integer algorithms and the Eisel-Lemire algorithm, respectively.
Finally, this algorithm provides substantial improvements in the number of floats the Rust core library can parse. Denormal floats with a large number of digits cannot be parsed, due to use of the `Big32x40`, which simply does not have enough digits to round a float correctly. Using a custom decimal class, with much simpler logic, we can parse all valid decimal strings of any digit count.
```rust
// Issue in Rust's dec2fly.
"2.47032822920623272088284396434110686182e-324".parse::<f64>(); // Err(ParseFloatError { kind: Invalid })
```
# Solution
This pull request implements the Eisel-Lemire algorithm, modified from [fast-float-rust](https://github.com/aldanor/fast-float-rust) (which is licensed under Apache 2.0/MIT), along with numerous modifications to make it more amenable to inclusion in the Rust core library. The following describes both features in fast-float-rust and improvements in fast-float-rust for inclusion in core.
**Documentation**
Extensive documentation has been added to ensure the code base may be maintained by others, which explains the algorithms as well as various associated constants and routines. For example, two seemingly magical constants include documentation to describe how they were derived as follows:
```rust
// Round-to-even only happens for negative values of q
// when q ≥ −4 in the 64-bit case and when q ≥ −17 in
// the 32-bitcase.
//
// When q ≥ 0,we have that 5^q ≤ 2m+1. In the 64-bit case,we
// have 5^q ≤ 2m+1 ≤ 2^54 or q ≤ 23. In the 32-bit case,we have
// 5^q ≤ 2m+1 ≤ 2^25 or q ≤ 10.
//
// When q < 0, we have w ≥ (2m+1)×5^−q. We must have that w < 2^64
// so (2m+1)×5^−q < 2^64. We have that 2m+1 > 2^53 (64-bit case)
// or 2m+1 > 2^24 (32-bit case). Hence,we must have 2^53×5^−q < 2^64
// (64-bit) and 2^24×5^−q < 2^64 (32-bit). Hence we have 5^−q < 2^11
// or q ≥ −4 (64-bit case) and 5^−q < 2^40 or q ≥ −17 (32-bitcase).
//
// Thus we have that we only need to round ties to even when
// we have that q ∈ [−4,23](in the 64-bit case) or q∈[−17,10]
// (in the 32-bit case). In both cases,the power of five(5^|q|)
// fits in a 64-bit word.
const MIN_EXPONENT_ROUND_TO_EVEN: i32;
const MAX_EXPONENT_ROUND_TO_EVEN: i32;
```
This ensures maintainability of the code base.
**Improvements for Disguised Fast-Path Cases**
The fast path in float parsing algorithms attempts to use native, machine floats to represent both the significant digits and the exponent, which is only possible if both can be exactly represented without rounding. In practice, this means that the significant digits must be 53-bits or less and the then exponent must be in the range `[-22, 22]` (for an f64). This is similar to the existing dec2flt implementation.
However, disguised fast-path cases exist, where there are few significant digits and an exponent above the valid range, such as `1.23e25`. In this case, powers-of-10 may be shifted from the exponent to the significant digits, discussed at length in https://github.com/rust-lang/rust/issues/85198.
**Digit Parsing Improvements**
Typically, integers are parsed from string 1-at-a-time, requiring unnecessary multiplications which can slow down parsing. An approach to parse 8 digits at a time using only 3 multiplications is described in length [here](https://johnnylee-sde.github.io/Fast-numeric-string-to-int/). This leads to significant performance improvements, and is implemented for both big and little-endian systems.
**Unsafe Changes**
Relative to fast-float-rust, this library makes less use of unsafe functionality and clearly documents it. This includes the refactoring and documentation of numerous unsafe methods undesirably marked as safe. The original code would look something like this, which is deceptively marked as safe for unsafe functionality.
```rust
impl AsciiStr {
#[inline]
pub fn step_by(&mut self, n: usize) -> &mut Self {
unsafe { self.ptr = self.ptr.add(n) };
self
}
}
...
#[inline]
fn parse_scientific(s: &mut AsciiStr<'_>) -> i64 {
// the first character is 'e'/'E' and scientific mode is enabled
let start = *s;
s.step();
...
}
```
The new code clearly documents safety concerns, and does not mark unsafe functionality as safe, leading to better safety guarantees.
```rust
impl AsciiStr {
/// Advance the view by n, advancing it in-place to (n..).
pub unsafe fn step_by(&mut self, n: usize) -> &mut Self {
// SAFETY: same as step_by, safe as long n is less than the buffer length
self.ptr = unsafe { self.ptr.add(n) };
self
}
}
...
/// Parse the scientific notation component of a float.
fn parse_scientific(s: &mut AsciiStr<'_>) -> i64 {
let start = *s;
// SAFETY: the first character is 'e'/'E' and scientific mode is enabled
unsafe {
s.step();
}
...
}
```
This allows us to trivially demonstrate the new implementation of dec2flt is safe.
**Inline Annotations Have Been Removed**
In the previous implementation of dec2flt, inline annotations exist practically nowhere in the entire module. Therefore, these annotations have been removed, which mostly does not impact [performance](https://github.com/aldanor/fast-float-rust/issues/15#issuecomment-864485157).
**Fixed Correctness Tests**
Numerous compile errors in `src/etc/test-float-parse` were present, due to deprecation of `time.clock()`, as well as the crate dependencies with `rand`. The tests have therefore been reworked as a [crate](https://github.com/Alexhuszagh/rust/tree/master/src/etc/test-float-parse), and any errors in `runtests.py` have been patched.
**Undefined Behavior**
An implementation of `check_len` which relied on undefined behavior (in fast-float-rust) has been refactored, to ensure that the behavior is well-defined. The original code is as follows:
```rust
#[inline]
pub fn check_len(&self, n: usize) -> bool {
unsafe { self.ptr.add(n) <= self.end }
}
```
And the new implementation is as follows:
```rust
/// Check if the slice at least `n` length.
fn check_len(&self, n: usize) -> bool {
n <= self.as_ref().len()
}
```
Note that this has since been fixed in [fast-float-rust](https://github.com/aldanor/fast-float-rust/pull/29).
**Inferring Binary Exponents**
Rather than explicitly store binary exponents, this new implementation infers them from the decimal exponent, reducing the amount of static storage required. This removes the requirement to store [611 i16s](https://github.com/rust-lang/rust/blob/868c702d0c9a471a28fb55f0148eb1e3e8b1dcc5/library/core/src/num/dec2flt/table.rs#L8).
# Code Size
The code size, for all optimizations, does not considerably change relative to before for stripped builds, however it is **significantly** smaller prior to stripping the resulting binaries. These binary sizes were calculated on x86_64-unknown-linux-gnu.
**new**
Using rustc version 1.55.0-dev.
opt-level|size|size(stripped)
|:-:|:-:|:-:|
0|400k|300K
1|396k|292K
2|392k|292K
3|392k|296K
s|396k|292K
z|396k|292K
**old**
Using rustc version 1.53.0-nightly.
opt-level|size|size(stripped)
|:-:|:-:|:-:|
0|3.2M|304K
1|3.2M|292K
2|3.1M|284K
3|3.1M|284K
s|3.1M|284K
z|3.1M|284K
# Correctness
The dec2flt implementation passes all of Rust's unittests and comprehensive float parsing tests, along with numerous other tests such as Nigel Toa's comprehensive float [tests](https://github.com/nigeltao/parse-number-fxx-test-data) and Hrvoje Abraham [strtod_tests](https://github.com/ahrvoje/numerics/blob/master/strtod/strtod_tests.toml). Therefore, it is unlikely that this algorithm will incorrectly round parsed floats.
# Issues Addressed
This will fix and close the following issues:
- resolves #85198
- resolves #85214
- resolves #85234
- fixes #31407
- fixes #31109
- fixes #53015
- resolves #68396
- closes https://github.com/aldanor/fast-float-rust/issues/15
|
|
r=petrochenkov
Use small code model for UEFI targets
* Since the code model only applies to the code and not the data and the code model
only applies to functions you call through using `call`, `jmp` and data with `lea`, etc…
If you are calling functions using the function pointers from the UEFI structures the code
model does not apply in that case. It’s just related to the address space size of your own binary.
Since UEFI (uefi is all relocatable) uses relocatable PEs (relocatable code does not care about the
code model) so, we use the small code model here.
* Since applications don't usually take gigabytes of memory, setting the
target to use the small code model should result in better codegen (comparable
with majority of other targets).
Large code models are also known for generating horrible code, for
example 16 bytes of code to load a single 8-byte value.
Signed-off-by: Andy-Python-Programmer <andypythonappdeveloper@gmail.com>
|
|
Do not allow JSON targets to set is-builtin: true
Note that this will affect (and make builds fail for) all of the projects out there that have target files invalid in this way. Crater, however, does not really cover these kinds of the codebases, so it is quite difficult to measure the impact. That said, the target files invalid in this way can start causing build failures each time LLVM is upgraded, anyway, so it is probably a good opportunity to disallow this property, entirely.
Another approach considered was to simply not parse this field anymore, which would avoid making the builds explicitly fail, but it wasn't clear to me if `is-builtin` was always set unintentionally… In case this was the case, I'd expect people to file a feature request stating specifically for what purpose they were using `is-builtin`.
Fixes #86017
|
|
Implementation is based off fast-float-rust, with a few notable changes.
- Some unsafe methods have been removed.
- Safe methods with inherently unsafe functionality have been removed.
- All unsafe functionality is documented and provably safe.
- Extensive documentation has been added for simpler maintenance.
- Inline annotations on internal routines has been removed.
- Fixed Python errors in src/etc/test-float-parse/runtests.py.
- Updated test-float-parse to be a library, to avoid missing rand dependency.
- Added regression tests for #31109 and #31407 in core tests.
- Added regression tests for #31109 and #31407 in ui tests.
- Use the existing slice primitive to simplify shared dec2flt methods
- Remove Miri ignores from dec2flt, due to faster parsing times.
- resolves #85198
- resolves #85214
- resolves #85234
- fixes #31407
- fixes #31109
- fixes #53015
- resolves #68396
- closes https://github.com/aldanor/fast-float-rust/issues/15
|
|
* Since the code model only applies to the code and not the data and the code model
only applies to functions you call through using `call`, `jmp` and data with `lea`, etc…
If you are calling functions using the function pointers from the UEFI structures the code
model does not apply in that case. It’s just related to the address space size of your own binary.
Since UEFI (uefi is all relocatable) uses relocatable PEs (relocatable code does not care about the
code model) so, we use the small code model here.
* Since applications don't usually take gigabytes of memory, setting the
target to use the small code model should result in better codegen (comparable
with majority of other targets).
Large code models are also known for generating horrible code, for
example 16 bytes of code to load a single 8-byte value.
* Use the LLVM default code model for the architecture for the
x86_64-unknown-uefi targets. For reference small is the default
code model on x86 in LLVM: <https://github.com/llvm/llvm-project/blob/7de2173c2a4c45711831cfee3ccf53690c76ff07/llvm/lib/Target/X86/X86TargetMachine.cpp#L204>
* Remove the comments too as they are not UEFI-specific and applies
to pretty much any target. I added them before as I was explicitily
setting the code model to small.
Signed-off-by: Andy-Python-Programmer <andypythonappdeveloper@gmail.com>
|
|
rename assert_matches module
Fixes nightly breakage introduced in https://github.com/rust-lang/rust/pull/86947
|
|
Add initial implementation of HIR-based WF checking for diagnostics
During well-formed checking, we walk through all types 'nested' in
generic arguments. For example, WF-checking `Option<MyStruct<u8>>`
will cause us to check `MyStruct<u8>` and `u8`. However, this is done
on a `rustc_middle::ty::Ty`, which has no span information. As a result,
any errors that occur will have a very general span (e.g. the
definintion of an associated item).
This becomes a problem when macros are involved. In general, an
associated type like `type MyType = Option<MyStruct<u8>>;` may
have completely different spans for each nested type in the HIR. Using
the span of the entire associated item might end up pointing to a macro
invocation, even though a user-provided span is available in one of the
nested types.
This PR adds a framework for HIR-based well formed checking. This check
is only run during error reporting, and is used to obtain a more precise
span for an existing error. This is accomplished by individually
checking each 'nested' type in the HIR for the type, allowing us to
find the most-specific type (and span) that produces a given error.
The majority of the changes are to the error-reporting code. However,
some of the general trait code is modified to pass through more
information.
Since this has no soundness implications, I've implemented a minimal
version to begin with, which can be extended over time. In particular,
this only works for HIR items with a corresponding `DefId` (e.g. it will
not work for WF-checking performed within function bodies).
|
|
During well-formed checking, we walk through all types 'nested' in
generic arguments. For example, WF-checking `Option<MyStruct<u8>>`
will cause us to check `MyStruct<u8>` and `u8`. However, this is done
on a `rustc_middle::ty::Ty`, which has no span information. As a result,
any errors that occur will have a very general span (e.g. the
definintion of an associated item).
This becomes a problem when macros are involved. In general, an
associated type like `type MyType = Option<MyStruct<u8>>;` may
have completely different spans for each nested type in the HIR. Using
the span of the entire associated item might end up pointing to a macro
invocation, even though a user-provided span is available in one of the
nested types.
This PR adds a framework for HIR-based well formed checking. This check
is only run during error reporting, and is used to obtain a more precise
span for an existing error. This is accomplished by individually
checking each 'nested' type in the HIR for the type, allowing us to
find the most-specific type (and span) that produces a given error.
The majority of the changes are to the error-reporting code. However,
some of the general trait code is modified to pass through more
information.
Since this has no soundness implications, I've implemented a minimal
version to begin with, which can be extended over time. In particular,
this only works for HIR items with a corresponding `DefId` (e.g. it will
not work for WF-checking performed within function bodies).
|
|
|
|
|
|
Rollup of 7 pull requests
Successful merges:
- #87107 (Loop over all opaque types instead of looking at just the first one with the same DefId)
- #87158 (Suggest full enum variant for local modules)
- #87174 (Stabilize `[T; N]::map()`)
- #87179 (Mark `const_trait_impl` as active)
- #87180 (feat(rustdoc): open sidebar menu when links inside it are focused)
- #87188 (Add GUI test for auto-hide-trait-implementations setting)
- #87200 (TAIT: Infer all inference variables in opaque type substitutions via InferCx)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
|
|
I wish the derive macro would support adding extra where clauses...
|
|
TAIT: Infer all inference variables in opaque type substitutions via InferCx
The previous algorithm was correct for the example given in its
documentation, but when the TAIT was declared as a free item
instead of an associated item, the generic parameters were the
wrong ones.
cc `@spastorino`
r? `@nikomatsakis`
|
|
r=notriddle
Add GUI test for auto-hide-trait-implementations setting
Fixes #85592.
r? ``@notriddle``
|
|
r=GuillaumeGomez
feat(rustdoc): open sidebar menu when links inside it are focused
Fixes #87172
Based on #87167 (which should be merged first)
r? ``@GuillaumeGomez``
Preview it at https://notriddle.com/notriddle-rustdoc-test/std/index.html
|
|
Mark `const_trait_impl` as active
See [this zulip thread](https://rust-lang.zulipchat.com/#narrow/stream/146212-t-compiler.2Fconst-eval/topic/implementation.20path.20for.20const.20trait.20impls).
r? ``@oli-obk``
|
|
Stabilize `[T; N]::map()`
This stabilizes the `[T; N]::map()` function, gated by the `array_map` feature. The FCP has [already completed.](https://github.com/rust-lang/rust/issues/75243#issuecomment-878448138)
Closes #75243.
|
|
r=estebank
Suggest full enum variant for local modules
|
|
Loop over all opaque types instead of looking at just the first one with the same DefId
This exposed a bug in VecMap and is needed for https://github.com/rust-lang/rust/pull/86410 anyway
r? ``@spastorino``
cc ``@nikomatsakis``
|
|
The previous algorithm was correct for the example given in its
documentation, but when the TAIT was declared as a free item
instead of an associated item, the generic parameters were the
wrong ones.
|
|
|
|
Make GATs no longer an incomplete feature
Blocked on ~#84622~, ~#82272~, ~#76826~
r? `@nikomatsakis`
|
|
|
|
Fixes #87172
Based on #87167 (which should be merged first)
Preview it at https://notriddle.com/notriddle-rustdoc-test/std/index.html
Co-authored-by: Guillaume Gomez <guillaume.gomez@huawei.com>
|
|
Remove refs from Pat slices
Changes `PatKind::Or(&'hir [&'hir Pat<'hir>])` to `PatKind::Or(&'hir [Pat<'hir>])` and others. This is more consistent with `ExprKind`, saves a little memory, and is a little easier to use.
|
|
|
|
|
|
Rollup of 7 pull requests
Successful merges:
- #86983 (Add or improve natvis definitions for common standard library types)
- #87069 (ExprUseVisitor: Treat ByValue use of Copy types as ImmBorrow)
- #87138 (Correct invariant documentation for `steps_between`)
- #87145 (Make --cap-lints and related options leave crate hash alone)
- #87161 (RFC2229: Use the correct place type)
- #87162 (Fix type decl layout "overflow")
- #87167 (Fix sidebar display on small devices)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
|
|
Fix sidebar display on small devices
Part of #87059.
Instead of hiding the sidebar on small devices, we instead move it out of the viewport so that it remains "visible" to our text only users.
Could you confirm it works for you `@ahicks92` and `@DataTriny` please? You can give it a try at [this URL](https://guillaume-gomez.fr/rustdoc-test/test_docs/index.html).
r? `@notriddle`
|
|
Fix type decl layout "overflow"
Before:
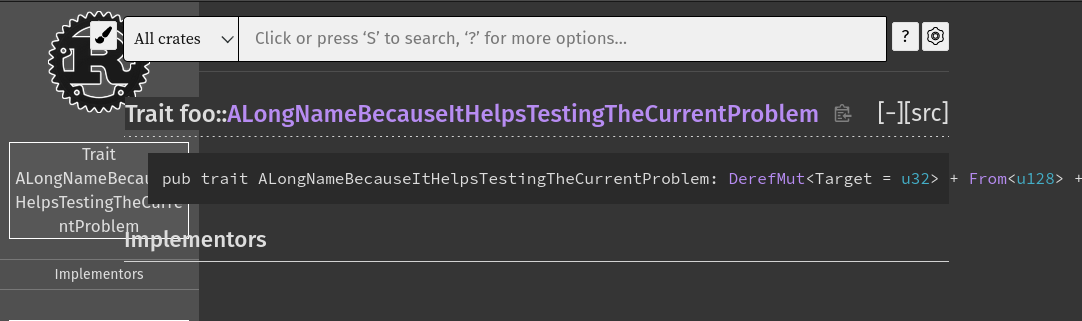
After:
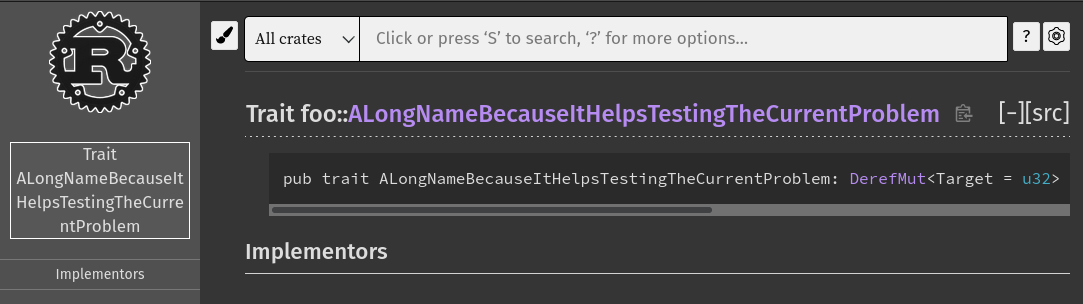
cc ```@SergioBenitez```
r? ```@notriddle```
|
|
RFC2229: Use the correct place type
Closes https://github.com/rust-lang/rust/issues/87097
The ICE occurred because instead of looking at the type of the place after all the projections are applied, we instead looked at the `base_ty` of the Place to decide whether a discriminant should be read of not. This lead to two issues:
1. the kind of the type is not necessarily `Adt` since we only look at the `base_ty`, it could be instead `Ref` for example
2. if the kind of the type is `Adt` you could still be looking at the wrong variant to make a decision on whether the discriminant should be read or not
r? `@nikomatsakis`
|
|
Make --cap-lints and related options leave crate hash alone
Closes: #87144
|
|
Correct invariant documentation for `steps_between`
Given that the previous example involves stepping forward from A to B, the equivalent example on this line would make most sense as stepping backward from B to A.
I should probably add a caveat here that I’m fairly new to Rust, and this is my first contribution to this repo, so it’s very possible that I’ve misunderstood how this is supposed to work (either on a technical level or a social one). If this is the case, please do let me know.
|
|
ExprUseVisitor: Treat ByValue use of Copy types as ImmBorrow
r? ```@nikomatsakis```
|
|
Add or improve natvis definitions for common standard library types
Natvis definitions are used by Windows debuggers to provide a better experience when inspecting a value for types with natvis definitions. Many of our standard library types and intrinsic Rust types like slices and `str` already have natvis definitions.
This PR adds natvis definitions for missing types (like all of the `Atomic*` types) and improves some of the existing ones (such as showing the ref count on `Arc<T>` and `Rc<T>` and showing the borrow state of `RefCell<T>`). I've also added cdb tests to cover these definitions and updated existing tests with the new visualizations.
With this PR, the following types now visualize in a much more intuitive way:
### Type: `NonZero{I,U}{8,16,32,64,128,size}`, `Atomic{I,U}{8,16,32,64,size}`, `AtomicBool` and `Wrapping<T>`
<details><summary>Example:</summary>
```rust
let a_u32 = AtomicU32::new(32i32);
```
```
0:000> dx a_u32
a_u32 : 32 [Type: core::sync::atomic::AtomicU32]
[<Raw View>] [Type: core::sync::atomic::AtomicU32]
```
</details>
### Type: `Cell<T>` and `UnsafeCell<T>`
<details><summary>Example:</summary>
```rust
let cell = Cell::new(123u8);
let unsafecell = UnsafeCell::new((42u16, 30u16));
```
```
0:000> dx cell
cell : 123 [Type: core::cell::Cell<u8>]
[<Raw View>] [Type: core::cell::Cell<u8>]
0:000> dx unsafecell
unsafecell : (42, 30) [Type: core::cell::UnsafeCell<tuple<u16, u16>>]
[<Raw View>] [Type: core::cell::UnsafeCell<tuple<u16, u16>>]
[0] : 42 [Type: unsigned short]
[1] : 30 [Type: unsigned short]
```
</details>
### Type: `RefCell<T>`
<details><summary>Example:</summary>
```rust
let refcell = RefCell::new((123u16, 456u32));
```
```
0:000> dx refcell
refcell : (123, 456) [Type: core::cell::RefCell<tuple<u16, u32>>]
[<Raw View>] [Type: core::cell::RefCell<tuple<u16, u32>>]
[Borrow state] : Unborrowed
[0] : 123 [Type: unsigned short]
[1] : 456 [Type: unsigned int]
```
</details>
### Type: `NonNull<T>` and `Unique<T>`
<details><summary>Example:</summary>
```rust
let nonnull: NonNull<_> = (&(10, 20)).into();
```
```
0:000> dx nonnull
nonnull : NonNull(0x7ff6a5d9c390: (10, 20)) [Type: core::ptr::non_null::NonNull<tuple<i32, i32>>]
[<Raw View>] [Type: core::ptr::non_null::NonNull<tuple<i32, i32>>]
[0] : 10 [Type: int]
[1] : 20 [Type: int]
```
</details>
### Type: `Range<T>`, `RangeFrom<T>`, `RangeInclusive<T>`, `RangeTo<T>` and `RangeToInclusive<T>`
<details><summary>Example:</summary>
```rust
let range = (1..12);
let rangefrom = (9..);
let rangeinclusive = (32..=80);
let rangeto = (..42);
let rangetoinclusive = (..=120);
```
```
0:000> dx range
range : (1..12) [Type: core::ops::range::Range<i32>]
[<Raw View>] [Type: core::ops::range::Range<i32>]
0:000> dx rangefrom
rangefrom : (9..) [Type: core::ops::range::RangeFrom<i32>]
[<Raw View>] [Type: core::ops::range::RangeFrom<i32>]
0:000> dx rangeinclusive
rangeinclusive : (32..=80) [Type: core::ops::range::RangeInclusive<i32>]
[<Raw View>] [Type: core::ops::range::RangeInclusive<i32>]
0:000> dx rangeto
rangeto : (..42) [Type: core::ops::range::RangeTo<i32>]
[<Raw View>] [Type: core::ops::range::RangeTo<i32>]
0:000> dx rangetoinclusive
rangetoinclusive : (..=120) [Type: core::ops::range::RangeToInclusive<i32>]
[<Raw View>] [Type: core::ops::range::RangeToInclusive<i32>]
```
</details>
### Type: `Duration`
<details><summary>Example:</summary>
```rust
let duration = Duration::new(5, 12);
```
```
0:000> dx duration
duration : 5s 12ns [Type: core::time::Duration]
[<Raw View>] [Type: core::time::Duration]
seconds : 5 [Type: unsigned __int64]
nanoseconds : 12 [Type: unsigned int]
```
</details>
### Type: `ManuallyDrop<T>`
<details><summary>Example:</summary>
```rust
let manuallydrop = ManuallyDrop::new((123, 456));
```
```
0:000> dx manuallydrop
manuallydrop : (123, 456) [Type: core::mem::manually_drop::ManuallyDrop<tuple<i32, i32>>]
[<Raw View>] [Type: core::mem::manually_drop::ManuallyDrop<tuple<i32, i32>>]
[0] : 123 [Type: int]
[1] : 456 [Type: int]
```
</details>
### Type: `Pin<T>`
<details><summary>Example:</summary>
```rust
let mut s = "this".to_string();
let pin = Pin::new(&mut s);
```
```
0:000> dx pin
pin : Pin(0x11a0ff6f0: "this") [Type: core::pin::Pin<mut alloc::string::String*>]
[<Raw View>] [Type: core::pin::Pin<mut alloc::string::String*>]
[len] : 4 [Type: unsigned __int64]
[capacity] : 4 [Type: unsigned __int64]
[chars]
```
</details>
### Type: `Rc<T>` and `Arc<T>`
<details><summary>Example:</summary>
```rust
let rc = Rc::new(42i8);
let rc_weak = Rc::downgrade(&rc);
```
```
0:000> dx rc
rc : 42 [Type: alloc::rc::Rc<i8>]
[<Raw View>] [Type: alloc::rc::Rc<i8>]
[Reference count] : 1 [Type: core::cell::Cell<usize>]
0:000> dx rc_weak
rc_weak : 42 [Type: alloc::rc::Weak<i8>]
[<Raw View>] [Type: alloc::rc::Weak<i8>]
```
</details>
r? ```@michaelwoerister```
cc ```@nanguye2496```
|
|
fix dead link for method in trait of blanket impl from third party crate
fix #86620
* changes `href` method to raise the actual error it had instead of an `Option`
* set the href link correctly in case of an error
I did not manage to make a small reproducer, I think it happens in a situation where
* crate A expose a trait with a blanket impl
* crate B use the trait from crate A
* crate C use types from crate B
* building docs for crate C without dependencies
r? `@jyn514`
|
|
|
|
Update cargo
6 commits in 66a6737a0c9f3a974af2dd032a65d3e409c77aac..27277d966b3cfa454d6dea7f724cb961c036251c
2021-07-14 20:54:28 +0000 to 2021-07-16 00:50:39 +0000
- Flag another curl error as possibly spurious (rust-lang/cargo#9695)
- Add `d` as an alias for `doc` (rust-lang/cargo#9680)
- `cargo fix --edition`: extend warning when on latest edition (rust-lang/cargo#9694)
- Update env_logger requirement from 0.8.1 to 0.9.0 (rust-lang/cargo#9688)
- Document cargo limitation w/ workspaces & configs (rust-lang/cargo#9674)
- Change some warnings to errors (rust-lang/cargo#9689)
|
|
|
|
|
|
Replace associated item bound vars with placeholders when projecting
Fixes #76407
Fixes #76826
Similar, but more limited, to #85499. This allows us to handle things like `for<'a> <T as Trait>::Assoc<'a>` but not `for<'a> <T as Trait<'a>>::Assoc`, unblocking GATs.
r? `@nikomatsakis`
|
|
|
|
|
|
|
