| Age | Commit message (Collapse) | Author | Lines |
|---|
|
Improve `AdtDef` interning.
This commit makes `AdtDef` use `Interned`. Much of the commit is tedious
changes to introduce getter functions. The interesting changes are in
`compiler/rustc_middle/src/ty/adt.rs`.
r? `@fee1-dead`
|
|
This commit makes `AdtDef` use `Interned`. Much the commit is tedious
changes to introduce getter functions. The interesting changes are in
`compiler/rustc_middle/src/ty/adt.rs`.
|
|
r=michaelwoerister
Only emit pointer-like metadata for `Box<T, A>` when `A` is ZST
Basically copy the change in #94043, but for debuginfo.
r? ``@michaelwoerister``
Fixes #94725
|
|
Update LLVM submodule
This merges upstream changes from the 14.x release branch.
Fixes #89609.
Fixes #93923.
Fixes #94032.
|
|
The problematic compile-time issue should be resolved with this
version.
|
|
|
|
|
|
Clarify `Layout` interning.
`Layout` is another type that is sometimes interned, sometimes not, and
we always use references to refer to it so we can't take any advantage
of the uniqueness properties for hashing or equality checks.
This commit renames `Layout` as `LayoutS`, and then introduces a new
`Layout` that is a newtype around an `Interned<LayoutS>`. It also
interns more layouts than before. Previously layouts within layouts
(via the `variants` field) were never interned, but now they are. Hence
the lifetime on the new `Layout` type.
Unlike other interned types, these ones are in `rustc_target` instead of
`rustc_middle`. This reflects the existing structure of the code, which
does layout-specific stuff in `rustc_target` while `TyAndLayout` is
generic over the `Ty`, allowing the type-specific stuff to occur in
`rustc_middle`.
The commit also adds a `HashStable` impl for `Interned`, which was
needed. It hashes the contents, unlike the `Hash` impl which hashes the
pointer.
r? `@fee1-dead`
|
|
`Layout` is another type that is sometimes interned, sometimes not, and
we always use references to refer to it so we can't take any advantage
of the uniqueness properties for hashing or equality checks.
This commit renames `Layout` as `LayoutS`, and then introduces a new
`Layout` that is a newtype around an `Interned<LayoutS>`. It also
interns more layouts than before. Previously layouts within layouts
(via the `variants` field) were never interned, but now they are. Hence
the lifetime on the new `Layout` type.
Unlike other interned types, these ones are in `rustc_target` instead of
`rustc_middle`. This reflects the existing structure of the code, which
does layout-specific stuff in `rustc_target` while `TyAndLayout` is
generic over the `Ty`, allowing the type-specific stuff to occur in
`rustc_middle`.
The commit also adds a `HashStable` impl for `Interned`, which was
needed. It hashes the contents, unlike the `Hash` impl which hashes the
pointer.
|
|
cleanup: remove unused ability to have LLVM null-terminate const strings
(and the copied function in rustc_codegen_gcc)
Noticed this while writing https://github.com/rust-lang/rust/pull/94450#issuecomment-1059687348.
r? `@nagisa`
|
|
Introduce `ConstAllocation`.
Currently some `Allocation`s are interned, some are not, and it's very
hard to tell at a use point which is which.
This commit introduces `ConstAllocation` for the known-interned ones,
which makes the division much clearer. `ConstAllocation::inner()` is
used to get the underlying `Allocation`.
In some places it's natural to use an `Allocation`, in some it's natural
to use a `ConstAllocation`, and in some places there's no clear choice.
I've tried to make things look as nice as possible, while generally
favouring `ConstAllocation`, which is the type that embodies more
information. This does require quite a few calls to `inner()`.
The commit also tweaks how `PartialOrd` works for `Interned`. The
previous code was too clever by half, building on `T: Ord` to make the
code shorter. That caused problems with deriving `PartialOrd` and `Ord`
for `ConstAllocation`, so I changed it to build on `T: PartialOrd`,
which is slightly more verbose but much more standard and avoided the
problems.
r? `@fee1-dead`
|
|
Currently some `Allocation`s are interned, some are not, and it's very
hard to tell at a use point which is which.
This commit introduces `ConstAllocation` for the known-interned ones,
which makes the division much clearer. `ConstAllocation::inner()` is
used to get the underlying `Allocation`.
In some places it's natural to use an `Allocation`, in some it's natural
to use a `ConstAllocation`, and in some places there's no clear choice.
I've tried to make things look as nice as possible, while generally
favouring `ConstAllocation`, which is the type that embodies more
information. This does require quite a few calls to `inner()`.
The commit also tweaks how `PartialOrd` works for `Interned`. The
previous code was too clever by half, building on `T: Ord` to make the
code shorter. That caused problems with deriving `PartialOrd` and `Ord`
for `ConstAllocation`, so I changed it to build on `T: PartialOrd`,
which is slightly more verbose but much more standard and avoided the
problems.
|
|
Rollup of 3 pull requests
Successful merges:
- #94659 (explain why shift with signed offset works the way it does)
- #94671 (fix pin doc typo)
- #94672 (Improved error message for failed bitcode load)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
|
|
"bc" is an unnecessary shorthand that obfuscates the compilation error
|
|
This ensures that information about target features configured with
`-C target-feature=...` or detected with `-C target-cpu=native` is
retained for subsequent consumers of LLVM bitcode.
This is crucial for linker plugin LTO, since this information is not
conveyed to the plugin otherwise.
|
|
|
|
Pass LLVM string attributes as string slices
|
|
Add !align metadata on loads of &/&mut/Box
Note that this refers to the alignment of what the loaded value points
to, _not_ the alignment of the loaded value itself.
r? `@ghost` (blocked on #94158)
|
|
Signed-off-by: cuishuang <imcusg@gmail.com>
|
|
Unused doc comments blocks
Fixes #77030.
|
|
|
|
|
|
|
|
Remove LLVM attribute removal
This was necessary before, because `declare_raw_fn` would always apply
the default optimization attributes to every declared function.
Then `attributes::from_fn_attrs` would have to remove the default
attributes in the case of, e.g. `#[optimize(speed)]` in a `-Os` build.
(see [`src/test/codegen/optimize-attr-1.rs`](https://github.com/rust-lang/rust/blob/03a8cc7df1d65554a4d40825b0490c93ac0f0236/src/test/codegen/optimize-attr-1.rs#L33))
However, every relevant callsite of `declare_raw_fn` (i.e. where we
actually generate code for the function, and not e.g. a call to an
intrinsic, where optimization attributes don't [?] matter)
calls `from_fn_attrs`, so we can remove the attribute setting
from `declare_raw_fn`, and rely on `from_fn_attrs` to apply the correct
attributes all at once.
r? `@ghost` (blocked on #94221)
`@rustbot` label S-blocked
|
|
r=estebank
Direct users towards using Rust target feature names in CLI
This PR consists of a couple of changes on how we handle target features.
In particular there is a bug-fix wherein we avoid passing through features that aren't prefixed by `+` or `-` to LLVM. These appear to be causing LLVM to assert, which is pretty poor a behaviour (and also makes it pretty clear we expect feature names to be prefixed).
The other commit, I anticipate to be somewhat more controversial is outputting a warning when users specify a LLVM-specific, or otherwise unknown, feature name on the CLI. In those situations we request users to either replace it with a known Rust feature name (e.g. `bmi` -> `bmi1`) or file a feature request. I've a couple motivations for this: first of all, if users are specifying these features on the command line, I'm pretty confident there is also a need for these features to be usable via `#[cfg(target_feature)]` machinery. And second, we're growing a fair number of backends recently and having ability to provide some sort of unified-ish interface in this place seems pretty useful to me.
Sponsored by: standard.ai
|
|
Revert "Auto merge of #92419 - erikdesjardins:coldland, r=nagisa"
Should fix (untested) #94390
Reopens #46515, #87055
r? `@ehuss`
|
|
Note that this refers to the alignment of what the loaded value points
to, _not_ the alignment of the loaded value itself.
|
|
At the very least this serves to deduplicate the diagnostics that are
output about unknown target features provided via CLI.
|
|
If they are trying to use features rustc doesn't yet know about,
request a feature request.
Additionally, also warn against using feature names without leading `+`
or `-` signs.
|
|
r=michaelwoerister
Fix MinGW target detection in raw-dylib
LLVM target doesn't have to be the same as Rust target so relying on it is wrong.
It was one of concerns in https://github.com/rust-lang/rust/pull/88801 that was not fixed in https://github.com/rust-lang/rust/pull/90782.
|
|
This was necessary before, because `declare_raw_fn` would always apply
the default optimization attributes to every declared function,
and then `attributes::from_fn_attrs` would have to remove the default
attributes in the case of, e.g. `#[optimize(speed)]` in a `-Os` build.
However, every relevant callsite of `declare_raw_fn` (i.e. where we
actually generate code for the function, and not e.g. a call to an
intrinsic, where optimization attributes don't [?] matter)
calls `from_fn_attrs`, so we can simply remove the attribute setting
from `declare_raw_fn`, and rely on `from_fn_attrs` to apply the correct
attributes all at once.
|
|
This reverts commit 4f49627c6fe2a32d1fed6310466bb0e1c535c0c0, reversing
changes made to 028c6f1454787c068ff5117e9000a1de4fd98374.
|
|
LLVM really dislikes this and will assert, saying something along the
lines of:
```
rustc: llvm/lib/MC/MCSubtargetInfo.cpp:60: void ApplyFeatureFlag(
llvm::FeatureBitset&, llvm::StringRef, llvm::ArrayRef<llvm::SubtargetFeatureKV>
): Assertion
`SubtargetFeatures::hasFlag(Feature) && "Feature flags should start with '+' or '-'"`
failed.
```
|
|
This matches the noundef attributes we apply on arguments/return types.
|
|
Add LLVM attributes in batches instead of individually
This should improve performance.
~r? `@ghost` (blocked on #94127)~
|
|
|
|
No branch protection metadata unless enabled
Even if we emit metadata disabling branch protection, this metadata may
conflict with other modules (e.g. during LTO) that have different branch
protection metadata set.
This is an unstable flag and feature, so ideally the flag not being
specified should act as if the feature wasn't implemented in the first
place.
Additionally this PR also ensures we emit an error if
`-Zbranch-protection` is set on targets other than the supported
aarch64. For now the error is being output from codegen, but ideally it
should be moved to earlier in the pipeline before stabilization.
|
|
This should improve performance.
|
|
At opt-level=0, apply only ABI-affecting attributes to functions
This should provide a small perf improvement for debug builds,
and should more than cancel out the perf regression from adding noundef (https://github.com/rust-lang/rust/pull/93670#issuecomment-1038347581, #94106).
r? `@nikic`
|
|
Bump bootstrap to 1.60
This bumps the bootstrap compiler to 1.60 and cleans up cfgs and Span's rustc_pass_by_value (enabled by the bootstrap bump).
|
|
LLVM target doesn't have to be the same as Rust target so relying on it is wrong.
|
|
|
|
debuginfo: Simplify TypeMap used during LLVM debuginfo generation.
This PR simplifies the TypeMap that is used in `rustc_codegen_llvm::debuginfo::metadata`. It was unnecessarily complicated because it was originally implemented when types were not yet normalized before codegen. So it did it's own normalization and kept track of multiple unnormalized types being mapped to a single unique id.
This PR is based on https://github.com/rust-lang/rust/pull/93503, which is not merged yet.
The PR also removes the arena used for allocating string ids and instead uses `InlinableString` from the [inlinable_string](https://crates.io/crates/inlinable_string) crate. That might not be the best choice, since that crate does not seem to be very actively maintained. The [flexible-string](https://crates.io/crates/flexible-string) crate would be an alternative.
r? `@ghost`
|
|
review comments.
|
|
Use undef for (some) partially-uninit constants
There needs to be some limit to avoid perf regressions on large arrays
with undef in each element (see comment in the code).
Fixes: #84565
Original PR: #83698
Depends on LLVM 14: #93577
|
|
r=michaelwoerister
properly handle fat pointers to uninhabitable types
Calculate the pointee metadata size by using `tcx.struct_tail_erasing_lifetimes` instead of duplicating the logic in `fat_pointer_kind`. Open to alternatively suggestions on how to fix this.
Fixes #94149
r? ````@michaelwoerister```` since you touched this code last, I think!
|
|
Partially move cg_ssa towards using a single builder
Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.)
`@antoyo` please review the cg_gcc changes.
|
|
|
|
Change `char` type in debuginfo to DW_ATE_UTF
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`.
Clang also uses the DW_ATE_UTF for `char32_t` in C++.
This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window.
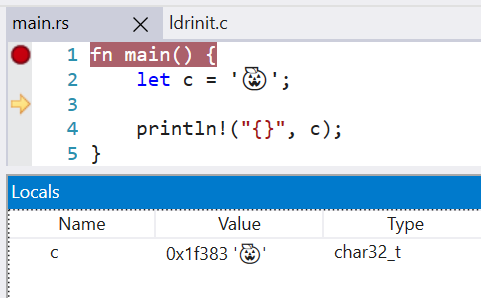
LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32`
r? `@wesleywiser`
|
