| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
Caching the stable hash of Ty within itself
Instead of computing stable hashes on types as needed, we compute it during interning.
This way we can, when a hash is requested, just hash that hash, which is significantly faster than traversing the type itself.
We only do this for incremental for now, as incremental is the only frequent user of stable hashing.
As a next step we can try out
* moving the hash and TypeFlags to Interner, so projections and regions get the same benefit (tho regions are not nested, so maybe that's not a good idea? Would be nice for dedup tho)
* start comparing types via their stable hash instead of their address?
|
|
Apply noundef attribute to all scalar types which do not permit raw init
Beyond `&`/`&mut`/`Box`, this covers `char`, enum discriminants, `NonZero*`, etc.
All such types currently cause a Miri error if left uninitialized,
and an `invalid_value` lint in cases like `mem::uninitialized::<char>()`.
Note that this _does not_ change whether or not it is UB for `u64` (or
other integer types with no invalid values) to be undef.
Fixes (partially) #74378.
r? `@ghost` (blocked on #94127)
`@rustbot` label S-blocked
|
|
Avoid query cache sharding code in single-threaded mode
In non-parallel compilers, this is just adding needless overhead at compilation time (since there is only one shard statically anyway). This amounts to roughly ~10 seconds reduction in bootstrap time, with overall neutral (some wins, some losses) performance results.
Parallel compiler performance should be largely unaffected by this PR; sharding is kept there.
|
|
Beyond `&`/`&mut`/`Box`, this covers `char`, discriminants, `NonZero*`, etc.
All such types currently cause a Miri error if left uninitialized,
and an `invalid_value` lint in cases like `mem::uninitialized::<char>()`
Note that this _does not_ change whether or not it is UB for `u64` (or
other integer types with no invalid values) to be undef.
|
|
Bump bootstrap to 1.60
This bumps the bootstrap compiler to 1.60 and cleans up cfgs and Span's rustc_pass_by_value (enabled by the bootstrap bump).
|
|
|
|
Print `ParamTy` and `ParamConst` instead of displaying them
Display for `ParamTy` and `ParamConst` is implemented in terms of print.
Using print avoids creating a new `FmtPrinter` just to display the
parameter name.
r? `@Mark-Simulacrum`
|
|
|
|
rustc_errors: let `DiagnosticBuilder::emit` return a "guarantee of emission".
That is, `DiagnosticBuilder` is now generic over the return type of `.emit()`, so we'll now have:
* `DiagnosticBuilder<ErrorReported>` for error (incl. fatal/bug) diagnostics
* can only be created via a `const L: Level`-generic constructor, that limits allowed variants via a `where` clause, so not even `rustc_errors` can accidentally bypass this limitation
* asserts `diagnostic.is_error()` on emission, just in case the construction restriction was bypassed (e.g. by replacing the whole `Diagnostic` inside `DiagnosticBuilder`)
* `.emit()` returns `ErrorReported`, as a "proof" token that `.emit()` was called
(though note that this isn't a real guarantee until after completing the work on
#69426)
* `DiagnosticBuilder<()>` for everything else (warnings, notes, etc.)
* can also be obtained from other `DiagnosticBuilder`s by calling `.forget_guarantee()`
This PR is a companion to other ongoing work, namely:
* #69426
and it's ongoing implementation:
#93222
the API changes in this PR are needed to get statically-checked "only errors produce `ErrorReported` from `.emit()`", but doesn't itself provide any really strong guarantees without those other `ErrorReported` changes
* #93244
would make the choices of API changes (esp. naming) in this PR fit better overall
In order to be able to let `.emit()` return anything trustable, several changes had to be made:
* `Diagnostic`'s `level` field is now private to `rustc_errors`, to disallow arbitrary "downgrade"s from "some kind of error" to "warning" (or anything else that doesn't cause compilation to fail)
* it's still possible to replace the whole `Diagnostic` inside the `DiagnosticBuilder`, sadly, that's harder to fix, but it's unlikely enough that we can paper over it with asserts on `.emit()`
* `.cancel()` now consumes `DiagnosticBuilder`, preventing `.emit()` calls on a cancelled diagnostic
* it's also now done internally, through `DiagnosticBuilder`-private state, instead of having a `Level::Cancelled` variant that can be read (or worse, written) by the user
* this removes a hazard of calling `.cancel()` on an error then continuing to attach details to it, and even expect to be able to `.emit()` it
* warnings were switched to *only* `can_emit_warnings` on emission (instead of pre-cancelling early)
* `struct_dummy` was removed (as it relied on a pre-`Cancelled` `Diagnostic`)
* since `.emit()` doesn't consume the `DiagnosticBuilder` <sub>(I tried and gave up, it's much more work than this PR)</sub>,
we have to make `.emit()` idempotent wrt the guarantees it returns
* thankfully, `err.emit(); err.emit();` can return `ErrorReported` both times, as the second `.emit()` call has no side-effects *only* because the first one did do the appropriate emission
* `&mut Diagnostic` is now used in a lot of function signatures, which used to take `&mut DiagnosticBuilder` (in the interest of not having to make those functions generic)
* the APIs were already mostly identical, allowing for low-effort porting to this new setup
* only some of the suggestion methods needed some rework, to have the extra `DiagnosticBuilder` functionality on the `Diagnostic` methods themselves (that change is also present in #93259)
* `.emit()`/`.cancel()` aren't available, but IMO calling them from an "error decorator/annotator" function isn't a good practice, and can lead to strange behavior (from the caller's perspective)
* `.downgrade_to_delayed_bug()` was added, letting you convert any `.is_error()` diagnostic into a `delay_span_bug` one (which works because in both cases the guarantees available are the same)
This PR should ideally be reviewed commit-by-commit, since there is a lot of fallout in each.
r? `@estebank` cc `@Manishearth` `@nikomatsakis` `@mark-i-m`
|
|
Always format to internal String in FmtPrinter
This avoids monomorphizing for different parameters, decreasing generic code
instantiated downstream from rustc_middle -- locally seeing 7% unoptimized LLVM IR
line wins on rustc_borrowck, for example.
We likely can't/shouldn't get rid of the Result-ness on most functions, though some
further cleanup avoiding fmt::Error where we now know it won't occur may be possible,
though somewhat painful -- fmt::Write is a pretty annoying API to work with in practice
when you're trying to use it infallibly.
|
|
|
|
|
|
|
|
Back more metadata using per-query tables
r? `@ghost`
|
|
Cleanup a few Decoder methods
This is just some simple follow up to #93839.
r? `@nnethercote`
|
|
Remove unused ordering derivations and bounds for `SimplifiedTypeGen`
This is another small PR clearing the way for work on #90317.
|
|
to avoid double negation
|
|
Display for `ParamTy` and `ParamConst` is implemented in terms of print.
Using print avoids creating a new `FmtPrinter` just to display the
parameter name.
|
|
|
|
|
|
|
|
|
|
Rollup of 10 pull requests
Successful merges:
- #91192 (Some improvements to the async docs)
- #94143 (rustc_const_eval: adopt let else in more places)
- #94156 (Gracefully handle non-UTF-8 string slices when pretty printing)
- #94186 (Update pin_static_ref stabilization version.)
- #94189 (Implement LowerHex on Scalar to clean up their display in rustdoc)
- #94190 (Use Metadata::modified instead of FileTime::from_last_modification_ti…)
- #94203 (CTFE engine: Scalar: expose size-generic to_(u)int methods)
- #94211 (Better error if the user tries to do assignment ... else)
- #94215 (trait system: comments and small nonfunctional changes)
- #94220 (Correctly handle miniz_oxide extern crate declaration)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
Gracefully handle non-UTF-8 string slices when pretty printing
Fixes #78520.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
This avoids monomorphizing for different parameters, decreasing generic code
instantiated downstream from rustc_middle.
|
|
Move ty::print methods to Drop-based scope guards
Primary goal is reducing codegen of the TLS access for each closure, which shaves ~3 seconds of bootstrap time over rustc as a whole.
|
|
This was largely just caching the shard value at this point, which is not
particularly useful -- in the use sites the key was being hashed nearby anyway.
|
|
|
|
|
|
Adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This is the biggest of these PRs and handles the changes outside of rustdoc, rustc_typeck, rustc_const_eval, rustc_trait_selection, which were handled in PRs #94139, #94142, #94143, #94144.
|
|
Fix rustdoc const computed value
Fixes #85088.
It looks like this now (instead of hexadecimal):
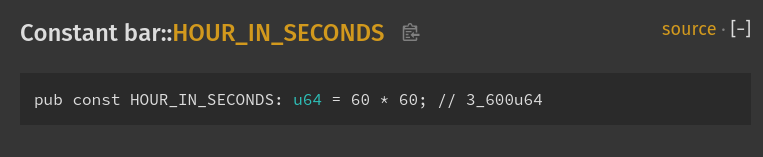
r? ````@oli-obk````
|
|
|
|
|
|
|
|
Fix ScalarInt to char conversion
to avoid panic for invalid Unicode scalar values
|
|
pre #89862 cleanup
changes used in #89862 which can be landed without the rest of this PR being finished.
r? `@estebank`
|
|
Suggest `impl Trait` return type when incorrectly using a generic return type
Address #85991
When there is a type mismatch error and the return type is generic, and that generic parameter is not used in the function parameters, suggest replacing that generic with the `impl Trait` syntax.
r? `@estebank`
|
|
Address #85991
Suggest the `impl Trait` return type syntax if the user tried to return a generic parameter and we get a type mismatch
The suggestion is not emitted if the param appears in the function parameters, and only get the bounds that actually involve `T: ` directly
It also checks whether the generic param is contained in any where bound (where it isn't the self type), and if one is found (like `Option<T>: Send`), it is not suggested.
This also adds `TyS::contains`, which recursively vistits the type and looks if the other type is contained anywhere
|
|
compiler: clippy::complexity fixes
useless_format
map_flatten
useless_conversion
needless_bool
filter_next
clone_on_copy
needless_option_as_deref
|
|
Improve comments about type folding/visiting.
I have found this code confusing for years. I've always roughly
understood it, but never exactly. I just made my fourth(?) attempt and
finally cracked it.
This commit improves the comments. In particular, it explicitly
describes how you can't do a custom fold/visit of any type; there are
actually a handful of "types of interest" (e.g. `Ty`, `Predicate`,
`Region`, `Const`) that can be custom folded/visted, and all other types
just get a generic traversal. I think this was the part that eluded me
on all my prior attempts at understanding.
The commit also updates comments to account for some newer changes such
as the fallible/infallible folding distinction, does some minor
reorderings, and moves one `impl` to a better place.
r? `@BoxyUwU`
|
|
to avoid panic for invalid Unicode scalar values
|
|
I have found this code confusing for years. I've always roughly
understood it, but never exactly. I just made my fourth(?) attempt and
finally cracked it.
This commit improves the comments. In particular, it explicitly
describes how you can't do a custom fold/visit of any type; there are
actually a handful of "types of interest" (e.g. `Ty`, `Predicate`,
`Region`, `Const`) that can be custom folded/visted, and all other types
just get a generic traversal. I think this was the part that eluded me
on all my prior attempts at understanding.
The commit also updates comments to account for some newer changes such
as the fallible/infallible folding distinction, does some minor
reorderings, and moves one `impl` to a better place.
|
|
|
