| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
Don't check the capacity every time (and also for `Extend` for tuples, as this is how `unzip()` is implemented).
I did this with an unsafe method on `Extend` that doesn't check for growth (`extend_one_unchecked()`). I've marked it as perma-unstable currently, although we may want to expose it in the future so collections outside of std can benefit from it. Then specialize `Extend for (A, B)` for `TrustedLen` to call it.
It may seem that an alternative way of implementing this is to have a semi-public trait (`#[doc(hidden)]` public, so collections outside of core can implement it) for `extend()` inside tuples, and specialize it from collections. However, it is impossible due to limitations of `min_specialization`.
A concern that may arise with the current approach is that implementing `extend_one_unchecked()` correctly must also incur implementing `extend_reserve()`, otherwise you can have UB. This is a somewhat non-local safety invariant. However, I believe this is fine, since to have actual UB you must have unsafe code inside your `extend_one_unchecked()` that makes incorrect assumption, *and* not implement `extend_reserve()`. I've also documented this requirement.
|
|
If/when `-Zmiri-disable-leak-check` is able to be used at test-granularity, it should applied to these tests instead of unleaking.
|
|
In 126578 we ended up with more binary size increases than expected.
This change attempts to avoid inlining large things into small things, to avoid that kind of increase, in cases when top-down inlining will still be able to do that inlining later.
|
|
|
|
|
|
|
|
This saves an extra load from memory.
|
|
Document overrides of `clone_from()` in core/std
As mentioned in https://github.com/rust-lang/rust/pull/96979#discussion_r1379502413
Specifically, when an override doesn't just forward to an inner type, document the behavior and that it's preferred over simply assigning a clone of source. Also, change instances where the second parameter is "other" to "source".
I reused some of the wording over and over for similar impls, but I'm not sure that the wording is actually *good*. Would appreciate feedback about that.
Also, now some of these seem to provide pretty specific guarantees about behavior (e.g. will reuse the exact same allocation iff the len is the same), but I was basing it off of the docs for [`Box::clone_from`](https://doc.rust-lang.org/1.75.0/std/boxed/struct.Box.html#method.clone_from-1) - I'm not sure if providing those strong guarantees is actually good or not.
|
|
|
|
|
|
to capacity. Also make Vec::insert use reserve_for_push.
|
|
Implement `Vec::pop_if`
This PR adds `Vec::pop_if` to the public API, behind the `vec_pop_if` feature.
```rust
impl<T> Vec<T> {
pub fn pop_if<F>(&mut self, f: F) -> Option<T>
where F: FnOnce(&mut T) -> bool;
}
```
Tracking issue: #122741
## Open questions
- [ ] Should the first unit test be split up?
- [ ] I don't see any guidance on ordering of methods in impl blocks, should I move the method elsewhere?
|
|
|
|
|
|
Move the length check to before using `index` with `ptr::add` to prevent
an out of bounds pointer from being formed.
Fixes #122760
|
|
|
|
Vec::try_with_capacity
Related to #91913
Implements try_with_capacity for `Vec`, `VecDeque`, and `String`. I can follow it up with more collections if desired.
`Vec::try_with_capacity()` is functionally equivalent to the current stable:
```rust
let mut v = Vec::new();
v.try_reserve_exact(n)?
```
However, `try_reserve` calls non-inlined `finish_grow`, which requires old and new `Layout`, and is designed to reallocate memory. There is benefit to using `try_with_capacity`, besides syntax convenience, because it generates much smaller code at the call site with a direct call to the allocator. There's codegen test included.
It's also a very desirable functionality for users of `no_global_oom_handling` (Rust-for-Linux), since it makes a very commonly used function available in that environment (`with_capacity` is used much more frequently than all `(try_)reserve(_exact)`).
|
|
Specifically, when an override doesn't just forward to an inner type,
document the behavior and that it's preferred over simply assigning
a clone of source. Also, change instances where the second parameter is
"other" to "source".
|
|
Add vector time complexity
Added time complexity for `Vec` methods `push`, `push_within_capacity`, `pop`, and `insert`.
<details>
<summary> Reference images </summary>

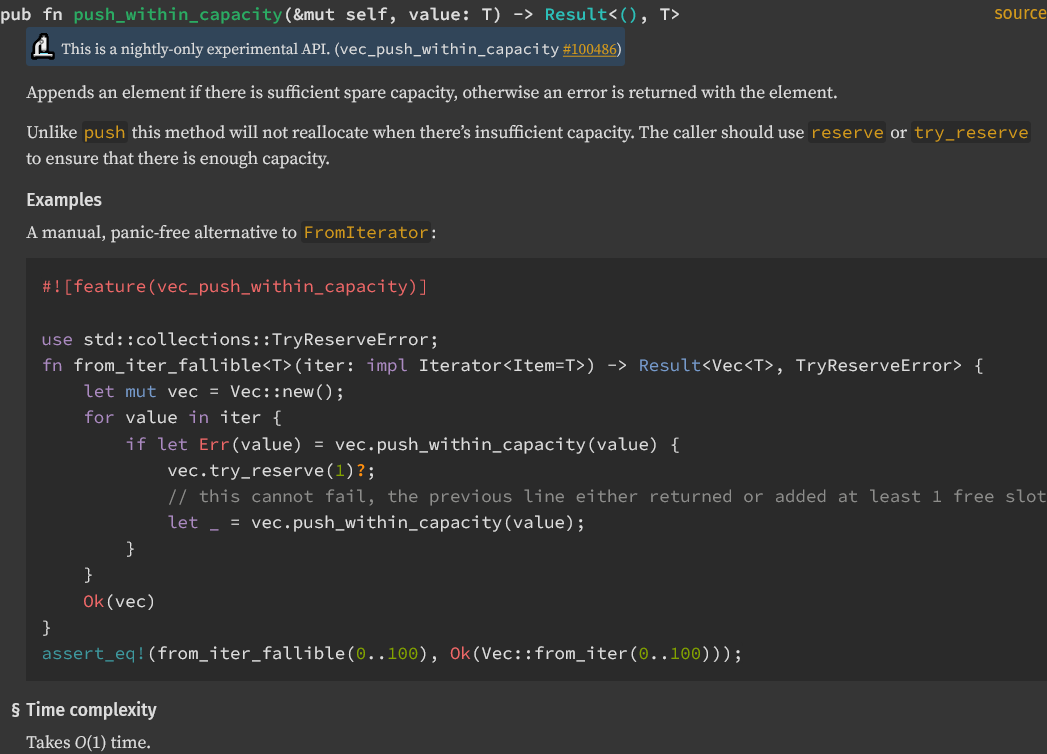
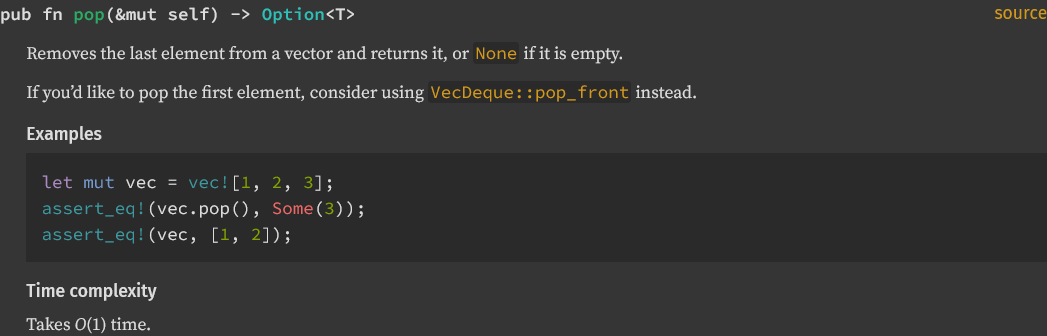
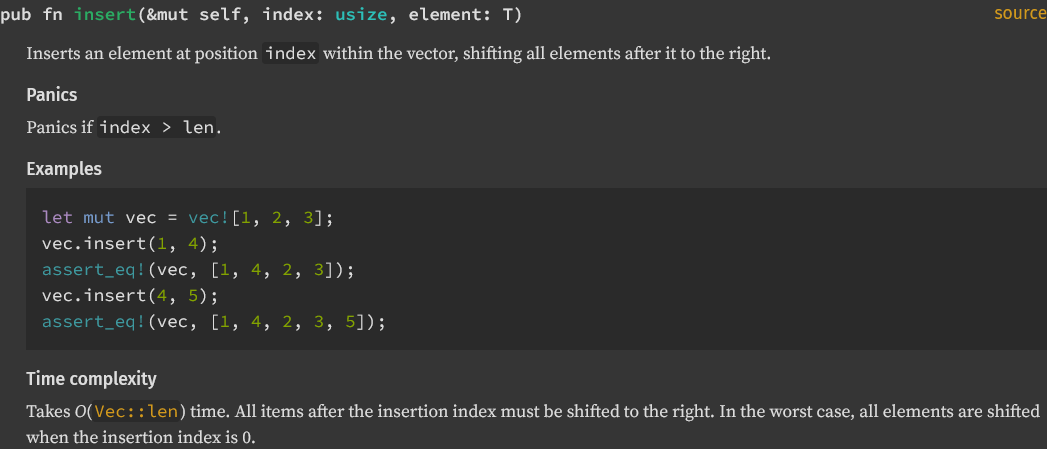
</details>
I followed a convention to use `#Time complexity` that I found in [the `BinaryHeap` documentation](https://doc.rust-lang.org/std/collections/struct.BinaryHeap.html#time-complexity-1). Looking through the rest of standard library collections, there is not a consistent way to handle this.
[`Vec::swap_remove`](https://doc.rust-lang.org/std/vec/struct.Vec.html#method.swap_remove) does not have a dedicated section for time complexity but does list it.
[`VecDeque::rotate_left`](https://doc.rust-lang.org/std/collections/struct.VecDeque.html#complexity) uses a `#complexity` heading.
|
|
#91913
|
|
|
|
argument order
|
|
|
|
Help with common API confusion, like asking for `push` when the data structure really has `append`.
```
error[E0599]: no method named `size` found for struct `Vec<{integer}>` in the current scope
--> $DIR/rustc_confusables_std_cases.rs:17:7
|
LL | x.size();
| ^^^^
|
help: you might have meant to use `len`
|
LL | x.len();
| ~~~
help: there is a method with a similar name
|
LL | x.resize();
| ~~~~~~
```
#59450
|
|
Copying is O(n)—not the memory allocation
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Co-authored-by: Josh Stone <cuviper@gmail.com>
|
|
|
|
Remove special-case handling of `vec.split_off(0)`
#76682 added special handling to `Vec::split_off` for the case where `at == 0`. Instead of copying the vector's contents into a freshly-allocated vector and returning it, the special-case code steals the old vector's allocation, and replaces it with a new (empty) buffer with the same capacity.
That eliminates the need to copy the existing elements, but comes at a surprising cost, as seen in #119913. The returned vector's capacity is no longer determined by the size of its contents (as would be expected for a freshly-allocated vector), and instead uses the full capacity of the old vector.
In cases where the capacity is large but the size is small, that results in a much larger capacity than would be expected from reading the documentation of `split_off`. This is especially bad when `split_off` is called in a loop (to recycle a buffer), and the returned vectors have a wide variety of lengths.
I believe it's better to remove the special-case code, and treat `at == 0` just like any other value:
- The current documentation states that `split_off` returns a “newly allocated vector”, which is not actually true in the current implementation when `at == 0`.
- If the value of `at` could be non-zero at runtime, then the caller has already agreed to the cost of a full memcpy of the taken elements in the general case. Avoiding that copy would be nice if it were close to free, but the different handling of capacity means that it is not.
- If the caller specifically wants to avoid copying in the case where `at == 0`, they can easily implement that behaviour themselves using `mem::replace`.
Fixes #119913.
|
|
Use `assert_unchecked` instead of `assume` intrinsic in the standard library
Now that a public wrapper for the `assume` intrinsic exists, we can use it in the standard library.
CC #119131
|
|
Document some alternatives to `Vec::split_off`
One of the discussion points that came up in #119917 is that some people use `Vec::split_off` in cases where they probably shouldn't, because the alternatives (like `mem::take`) are hard to discover.
This PR adds some suggestions to the documentation of `split_off` that should point people towards alternatives that might be more appropriate for their use-case.
I've deliberately tried to keep these changes as simple and uncontroversial as possible, so that they don't depend on how the team decides to handle the concerns raised in #119917. That's why I haven't touched the existing documentation for `split_off`, and haven't added links to `split_off` to the documentation of other methods.
|
|
|
|
InPlaceDstBufDrop holds onto the allocation before the shrinking happens
which means it must deallocate the destination elements but the source
allocation.
|
|
|
|
|
|
|
|
|
|
because on a cursory read it's easy to miss that the limit is
in terms of bytes not no. of elements. The italics should help
with that.
|
|
r=the8472
Split `Vec::dedup_by` into 2 cycles
First cycle runs until we found 2 same elements, second runs after if there any found in the first one. This allows to avoid any memory writes until we found an item which we want to remove.
This leads to significant performance gains if all `Vec` items are kept: -40% on my benchmark with unique integers.
Results of benchmarks before implementation (including new benchmark where nothing needs to be removed):
* vec::bench_dedup_all_100 74.00ns/iter +/- 13.00ns
* vec::bench_dedup_all_1000 572.00ns/iter +/- 272.00ns
* vec::bench_dedup_all_100000 64.42µs/iter +/- 19.47µs
* __vec::bench_dedup_none_100 67.00ns/iter +/- 17.00ns__
* __vec::bench_dedup_none_1000 662.00ns/iter +/- 86.00ns__
* __vec::bench_dedup_none_10000 9.16µs/iter +/- 2.71µs__
* __vec::bench_dedup_none_100000 91.25µs/iter +/- 1.82µs__
* vec::bench_dedup_random_100 105.00ns/iter +/- 11.00ns
* vec::bench_dedup_random_1000 781.00ns/iter +/- 10.00ns
* vec::bench_dedup_random_10000 9.00µs/iter +/- 5.62µs
* vec::bench_dedup_random_100000 449.81µs/iter +/- 74.99µs
* vec::bench_dedup_slice_truncate_100 105.00ns/iter +/- 16.00ns
* vec::bench_dedup_slice_truncate_1000 2.65µs/iter +/- 481.00ns
* vec::bench_dedup_slice_truncate_10000 18.33µs/iter +/- 5.23µs
* vec::bench_dedup_slice_truncate_100000 501.12µs/iter +/- 46.97µs
Results after implementation:
* vec::bench_dedup_all_100 75.00ns/iter +/- 9.00ns
* vec::bench_dedup_all_1000 494.00ns/iter +/- 117.00ns
* vec::bench_dedup_all_100000 58.13µs/iter +/- 8.78µs
* __vec::bench_dedup_none_100 52.00ns/iter +/- 22.00ns__
* __vec::bench_dedup_none_1000 417.00ns/iter +/- 116.00ns__
* __vec::bench_dedup_none_10000 4.11µs/iter +/- 546.00ns__
* __vec::bench_dedup_none_100000 40.47µs/iter +/- 5.36µs__
* vec::bench_dedup_random_100 77.00ns/iter +/- 15.00ns
* vec::bench_dedup_random_1000 681.00ns/iter +/- 86.00ns
* vec::bench_dedup_random_10000 11.66µs/iter +/- 2.22µs
* vec::bench_dedup_random_100000 469.35µs/iter +/- 20.53µs
* vec::bench_dedup_slice_truncate_100 100.00ns/iter +/- 5.00ns
* vec::bench_dedup_slice_truncate_1000 2.55µs/iter +/- 224.00ns
* vec::bench_dedup_slice_truncate_10000 18.95µs/iter +/- 2.59µs
* vec::bench_dedup_slice_truncate_100000 492.85µs/iter +/- 72.84µs
Resolves #77772
P.S. Note that this is same PR as #92104 I just missed review then forgot about it.
Also, I cannot reopen that pull request so I am creating a new one.
I responded to remaining questions directly by adding commentaries to my code.
|
|
First cycle runs until we found 2 same elements, second runs after if there any found in the first one. This allows to avoid any memory writes until we found an item which we want to remove.
This leads to significant performance gains if all `Vec` items are kept: -40% on my benchmark with unique integers.
Results of benchmarks before implementation (including new benchmark where nothing needs to be removed):
* vec::bench_dedup_all_100 74.00ns/iter +/- 13.00ns
* vec::bench_dedup_all_1000 572.00ns/iter +/- 272.00ns
* vec::bench_dedup_all_100000 64.42µs/iter +/- 19.47µs
* __vec::bench_dedup_none_100 67.00ns/iter +/- 17.00ns__
* __vec::bench_dedup_none_1000 662.00ns/iter +/- 86.00ns__
* __vec::bench_dedup_none_10000 9.16µs/iter +/- 2.71µs__
* __vec::bench_dedup_none_100000 91.25µs/iter +/- 1.82µs__
* vec::bench_dedup_random_100 105.00ns/iter +/- 11.00ns
* vec::bench_dedup_random_1000 781.00ns/iter +/- 10.00ns
* vec::bench_dedup_random_10000 9.00µs/iter +/- 5.62µs
* vec::bench_dedup_random_100000 449.81µs/iter +/- 74.99µs
* vec::bench_dedup_slice_truncate_100 105.00ns/iter +/- 16.00ns
* vec::bench_dedup_slice_truncate_1000 2.65µs/iter +/- 481.00ns
* vec::bench_dedup_slice_truncate_10000 18.33µs/iter +/- 5.23µs
* vec::bench_dedup_slice_truncate_100000 501.12µs/iter +/- 46.97µs
Results after implementation:
* vec::bench_dedup_all_100 75.00ns/iter +/- 9.00ns
* vec::bench_dedup_all_1000 494.00ns/iter +/- 117.00ns
* vec::bench_dedup_all_100000 58.13µs/iter +/- 8.78µs
* __vec::bench_dedup_none_100 52.00ns/iter +/- 22.00ns__
* __vec::bench_dedup_none_1000 417.00ns/iter +/- 116.00ns__
* __vec::bench_dedup_none_10000 4.11µs/iter +/- 546.00ns__
* __vec::bench_dedup_none_100000 40.47µs/iter +/- 5.36µs__
* vec::bench_dedup_random_100 77.00ns/iter +/- 15.00ns
* vec::bench_dedup_random_1000 681.00ns/iter +/- 86.00ns
* vec::bench_dedup_random_10000 11.66µs/iter +/- 2.22µs
* vec::bench_dedup_random_100000 469.35µs/iter +/- 20.53µs
* vec::bench_dedup_slice_truncate_100 100.00ns/iter +/- 5.00ns
* vec::bench_dedup_slice_truncate_1000 2.55µs/iter +/- 224.00ns
* vec::bench_dedup_slice_truncate_10000 18.95µs/iter +/- 2.59µs
* vec::bench_dedup_slice_truncate_100000 492.85µs/iter +/- 72.84µs
Resolves #77772
|
|
|
|
|
|
|
