| Age | Commit message (Collapse) | Author | Lines |
|---|
|
add more niches to rawvec
Previously RawVec only had a single niche in its `NonNull` pointer. With this change it now has `isize::MAX` niches since half the value-space of the capacity field is never needed, we can't have a capacity larger than isize::MAX.
|
|
|
|
|
|
|
|
remove redundant imports
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and removing redundant imports code into two PR.
r? `@petrochenkov`
|
|
Stablize arc_unwrap_or_clone
Fixes: #93610
This likely needs FCP. I created this PR as it's stabilization is trivial and FCP can be just conducted here. Not sure how to ping the libs API team (last attempt didn't work apparently according to GH UI)
|
|
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and
removing redundant imports code into two PR.
|
|
add LinkedList::{retain,retain_mut}
Implement #114135
The API is consistent with other collections.
|
|
chore: avoid duplicate code in `Weak::inner`
|
|
docs: clarify explicitly freeing heap allocated memory
The documentation for `Box::into_raw` didn't mention `drop` and wondered if I was doing something wrong. Based off [this](https://stackoverflow.com/questions/75441199/rust-how-do-i-correctly-free-heap-allocated-memory), I think it's helpful to include the more concise yet explicit way to free heap allocated memory. This is my first rust PR and I went through https://std-dev-guide.rust-lang.org/development/, but let me know if I missed something :)
|
|
Fix in-place collect not reallocating when necessary
Regression introduced in https://github.com/rust-lang/rust/pull/110353.
This was [caught by miri](https://rust-lang.zulipchat.com/#narrow/stream/269128-miri/topic/Cron.20Job.20Failure.20.28miri-test-libstd.2C.202023-11.29/near/404764617)
r? `@saethlin`
|
|
|
|
r=the8472
Split `Vec::dedup_by` into 2 cycles
First cycle runs until we found 2 same elements, second runs after if there any found in the first one. This allows to avoid any memory writes until we found an item which we want to remove.
This leads to significant performance gains if all `Vec` items are kept: -40% on my benchmark with unique integers.
Results of benchmarks before implementation (including new benchmark where nothing needs to be removed):
* vec::bench_dedup_all_100 74.00ns/iter +/- 13.00ns
* vec::bench_dedup_all_1000 572.00ns/iter +/- 272.00ns
* vec::bench_dedup_all_100000 64.42µs/iter +/- 19.47µs
* __vec::bench_dedup_none_100 67.00ns/iter +/- 17.00ns__
* __vec::bench_dedup_none_1000 662.00ns/iter +/- 86.00ns__
* __vec::bench_dedup_none_10000 9.16µs/iter +/- 2.71µs__
* __vec::bench_dedup_none_100000 91.25µs/iter +/- 1.82µs__
* vec::bench_dedup_random_100 105.00ns/iter +/- 11.00ns
* vec::bench_dedup_random_1000 781.00ns/iter +/- 10.00ns
* vec::bench_dedup_random_10000 9.00µs/iter +/- 5.62µs
* vec::bench_dedup_random_100000 449.81µs/iter +/- 74.99µs
* vec::bench_dedup_slice_truncate_100 105.00ns/iter +/- 16.00ns
* vec::bench_dedup_slice_truncate_1000 2.65µs/iter +/- 481.00ns
* vec::bench_dedup_slice_truncate_10000 18.33µs/iter +/- 5.23µs
* vec::bench_dedup_slice_truncate_100000 501.12µs/iter +/- 46.97µs
Results after implementation:
* vec::bench_dedup_all_100 75.00ns/iter +/- 9.00ns
* vec::bench_dedup_all_1000 494.00ns/iter +/- 117.00ns
* vec::bench_dedup_all_100000 58.13µs/iter +/- 8.78µs
* __vec::bench_dedup_none_100 52.00ns/iter +/- 22.00ns__
* __vec::bench_dedup_none_1000 417.00ns/iter +/- 116.00ns__
* __vec::bench_dedup_none_10000 4.11µs/iter +/- 546.00ns__
* __vec::bench_dedup_none_100000 40.47µs/iter +/- 5.36µs__
* vec::bench_dedup_random_100 77.00ns/iter +/- 15.00ns
* vec::bench_dedup_random_1000 681.00ns/iter +/- 86.00ns
* vec::bench_dedup_random_10000 11.66µs/iter +/- 2.22µs
* vec::bench_dedup_random_100000 469.35µs/iter +/- 20.53µs
* vec::bench_dedup_slice_truncate_100 100.00ns/iter +/- 5.00ns
* vec::bench_dedup_slice_truncate_1000 2.55µs/iter +/- 224.00ns
* vec::bench_dedup_slice_truncate_10000 18.95µs/iter +/- 2.59µs
* vec::bench_dedup_slice_truncate_100000 492.85µs/iter +/- 72.84µs
Resolves #77772
P.S. Note that this is same PR as #92104 I just missed review then forgot about it.
Also, I cannot reopen that pull request so I am creating a new one.
I responded to remaining questions directly by adding commentaries to my code.
|
|
First cycle runs until we found 2 same elements, second runs after if there any found in the first one. This allows to avoid any memory writes until we found an item which we want to remove.
This leads to significant performance gains if all `Vec` items are kept: -40% on my benchmark with unique integers.
Results of benchmarks before implementation (including new benchmark where nothing needs to be removed):
* vec::bench_dedup_all_100 74.00ns/iter +/- 13.00ns
* vec::bench_dedup_all_1000 572.00ns/iter +/- 272.00ns
* vec::bench_dedup_all_100000 64.42µs/iter +/- 19.47µs
* __vec::bench_dedup_none_100 67.00ns/iter +/- 17.00ns__
* __vec::bench_dedup_none_1000 662.00ns/iter +/- 86.00ns__
* __vec::bench_dedup_none_10000 9.16µs/iter +/- 2.71µs__
* __vec::bench_dedup_none_100000 91.25µs/iter +/- 1.82µs__
* vec::bench_dedup_random_100 105.00ns/iter +/- 11.00ns
* vec::bench_dedup_random_1000 781.00ns/iter +/- 10.00ns
* vec::bench_dedup_random_10000 9.00µs/iter +/- 5.62µs
* vec::bench_dedup_random_100000 449.81µs/iter +/- 74.99µs
* vec::bench_dedup_slice_truncate_100 105.00ns/iter +/- 16.00ns
* vec::bench_dedup_slice_truncate_1000 2.65µs/iter +/- 481.00ns
* vec::bench_dedup_slice_truncate_10000 18.33µs/iter +/- 5.23µs
* vec::bench_dedup_slice_truncate_100000 501.12µs/iter +/- 46.97µs
Results after implementation:
* vec::bench_dedup_all_100 75.00ns/iter +/- 9.00ns
* vec::bench_dedup_all_1000 494.00ns/iter +/- 117.00ns
* vec::bench_dedup_all_100000 58.13µs/iter +/- 8.78µs
* __vec::bench_dedup_none_100 52.00ns/iter +/- 22.00ns__
* __vec::bench_dedup_none_1000 417.00ns/iter +/- 116.00ns__
* __vec::bench_dedup_none_10000 4.11µs/iter +/- 546.00ns__
* __vec::bench_dedup_none_100000 40.47µs/iter +/- 5.36µs__
* vec::bench_dedup_random_100 77.00ns/iter +/- 15.00ns
* vec::bench_dedup_random_1000 681.00ns/iter +/- 86.00ns
* vec::bench_dedup_random_10000 11.66µs/iter +/- 2.22µs
* vec::bench_dedup_random_100000 469.35µs/iter +/- 20.53µs
* vec::bench_dedup_slice_truncate_100 100.00ns/iter +/- 5.00ns
* vec::bench_dedup_slice_truncate_1000 2.55µs/iter +/- 224.00ns
* vec::bench_dedup_slice_truncate_10000 18.95µs/iter +/- 2.59µs
* vec::bench_dedup_slice_truncate_100000 492.85µs/iter +/- 72.84µs
Resolves #77772
|
|
|
|
Rollup of 7 pull requests
Successful merges:
- #116839 (Implement thread parking for xous)
- #118265 (remove the memcpy-on-equal-ptrs assumption)
- #118269 (Unify `TraitRefs` and `PolyTraitRefs` in `ValuePairs`)
- #118394 (Remove HIR opkinds)
- #118398 (Add proper cfgs in std)
- #118419 (Eagerly return `ExprKind::Err` on `yield`/`await` in wrong coroutine context)
- #118422 (Fix coroutine validation for mixed panic strategy)
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
shepmaster:unused-tuple-struct-field-cleanup-stdlib, r=m-ou-se
Address unused tuple struct fields in the standard library
|
|
Add proper cfgs in std
Detected by #118257
|
|
|
|
Expand in-place iteration specialization to Flatten, FlatMap and ArrayChunks
This enables the following cases to collect in-place:
```rust
let v = vec![[0u8; 4]; 1024]
let v: Vec<_> = v.into_iter().flatten().collect();
let v: Vec<Option<NonZeroUsize>> = vec![NonZeroUsize::new(0); 1024];
let v: Vec<_> = v.into_iter().flatten().collect();
let v = vec![u8; 4096];
let v: Vec<_> = v.into_iter().array_chunks::<4>().collect();
```
Especially the nicheful-option-flattening should be useful in real code.
|
|
|
|
Stabilize `ptr::addr_eq`
This PR stabilize the `ptr_addr_eq` library feature, representing:
```rust
// core::ptr
pub fn addr_eq<T: ?Sized, U: ?Sized>(p: *const T, q: *const U) -> bool;
```
FCP has already started [on the tracking issue](https://github.com/rust-lang/rust/issues/116324#issuecomment-1813008697) and is waiting on the final period comment.
Note: stabilizing this feature is somewhat of requirement for a new T-lang lint, cf. https://github.com/rust-lang/rust/pull/117758#issuecomment-1813183686.
|
|
Signed-off-by: Petr Portnov <me@progrm-jarvis.ru>
|
|
Signed-off-by: Petr Portnov <me@progrm-jarvis.ru>
|
|
While a better approach would be to implement it for all ZSTs
which are `Copy` and have trivial `Clone`,
the last property cannot be detected for now.
Signed-off-by: Petr Portnov <me@progrm-jarvis.ru>
|
|
|
|
|
|
|
|
Add `std::hash::{DefaultHasher, RandomState}` exports (needs FCP)
This implements rust-lang/libs-team#267 to move the libstd hasher types to `std::hash` where they belong, instead of `std::collections::hash_map`.
<details><summary>The below no longer applies, but is kept for clarity.</summary>
This is a small refactor for #27242, which moves the definitions of `RandomState` and `DefaultHasher` into `std::hash`, but in a way that won't be noticed in the public API.
I've opened rust-lang/libs-team#267 as a formal ACP to move these directly into the root of `std::hash`, but for now, they're at least separated out from the collections code in a way that will make moving that around easier.
I decided to simply copy the rustdoc for `std::hash` from `core::hash` since I think it would be ideal for the two to diverge longer-term, especially if the ACP is accepted. However, I would be willing to factor them out into a common markdown document if that's preferred.
</details>
|
|
|
|
Stabilize `const_maybe_uninit_zeroed` and `const_mem_zeroed`
Make `MaybeUninit::zeroed` and `mem::zeroed` const stable. Newly stable API:
```rust
// core::mem
pub const unsafe fn zeroed<T>() ->;
impl<T> MaybeUninit<T> {
pub const fn zeroed() -> MaybeUninit<T>;
}
```
This relies on features based around `const_mut_refs`. Per `@RalfJung,` this should be OK since we do not leak any `&mut` to the user.
For this to be possible, intrinsics `assert_zero_valid` and `assert_mem_uninitialized_valid` were made const stable.
Tracking issue: #91850
Zulip discussion: https://rust-lang.zulipchat.com/#narrow/stream/146212-t-compiler.2Fconst-eval/topic/.60const_mut_refs.60.20dependents
r? libs-api
`@rustbot` label -T-libs +T-libs-api +A-const-eval
cc `@RalfJung` `@oli-obk` `@rust-lang/wg-const-eval`
|
|
Hint optimizer about try-reserved capacity
This is #116568, but limited only to the less-common `try_reserve` functions to reduce bloat in debug binaries from debug info, while still addressing the main use-case #116570
|
|
Make `MaybeUninit::zeroed` const stable. Newly stable API:
// core::mem
impl<T> MaybeUninit<T> {
pub const fn zeroed() -> MaybeUninit<T>;
}
Use of `const_mut_refs` should be acceptable since we do not leak the
mutability.
Tracking issue: #91850
|
|
|
|
|
|
|
|
Signed-off-by: Bugen Zhao <i@bugenzhao.com>
|
|
Increase the reach of panic_immediate_abort
I wanted to use/abuse this recently as part of another project, and I was surprised how many panic-related things were left in my binaries if I built a large crate with the feature enabled along with LTO. These changes get all the panic-related symbols that I could find out of my set of locally installed Rust utilities.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Fixes: https://github.com/rust-lang/rust/issues/114334
|
|
Bump bootstrap compiler to just-released beta
https://forge.rust-lang.org/release/process.html#master-bootstrap-update-t-2-day-tuesday
|
|
rustdoc: show crate name beside smaller logo
*Blocked on https://github.com/rust-lang/cargo/pull/12800*
## Summary
In this PR, the crate name and version are always shown in the sidebar, even in subpages, and the lateral navigation is always shown in the sidebar, even in modules.
Clicking the crate name does the same thing clicking the logo always did: take you to the crate root (the crate's home page, at least within Rustdoc).
The Rust logo is also no longer shown by default for non-Rust docs.
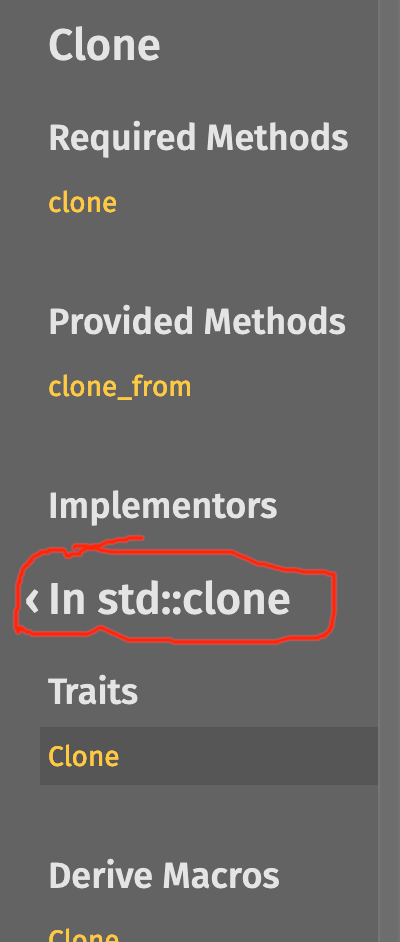
### Screenshots
<details><summary>Before</summary>
| | Macro | Module |
|--|-------|--------|
| In crate | 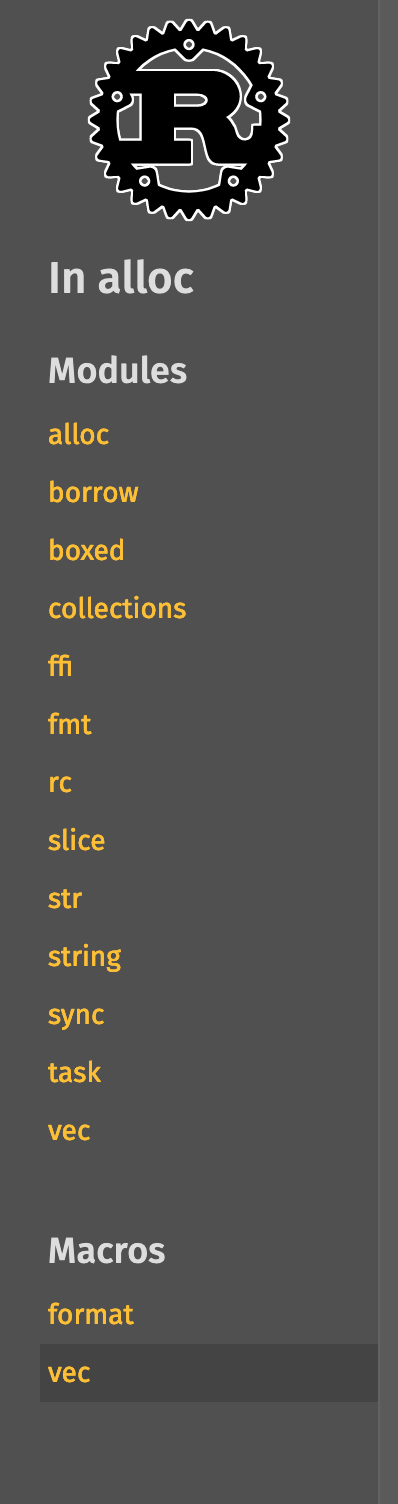 |
| In module[^1] | 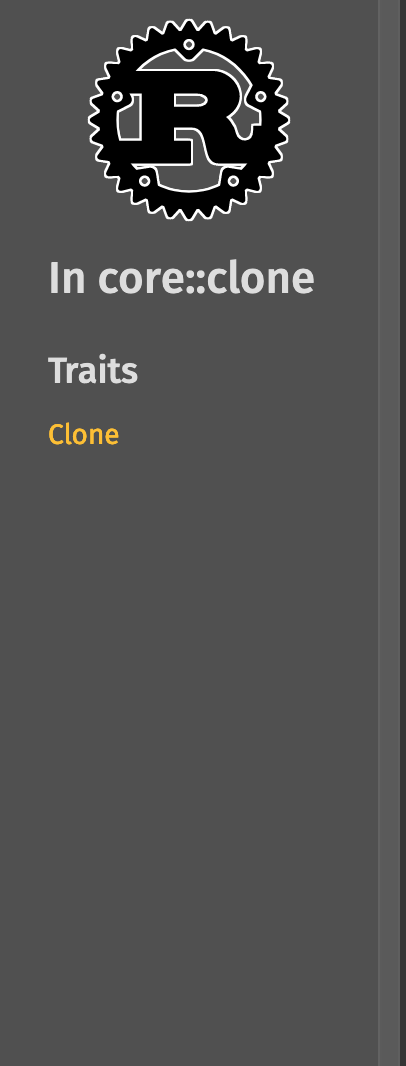 | 
[^1]: This PR also includes a bug fix for derive macros not showing up in the lateral navigation part of the sidebar
</details>
#### Whole sidebar screenshots
| | Macro | Module |
|--|-------|--------|
| In crate | 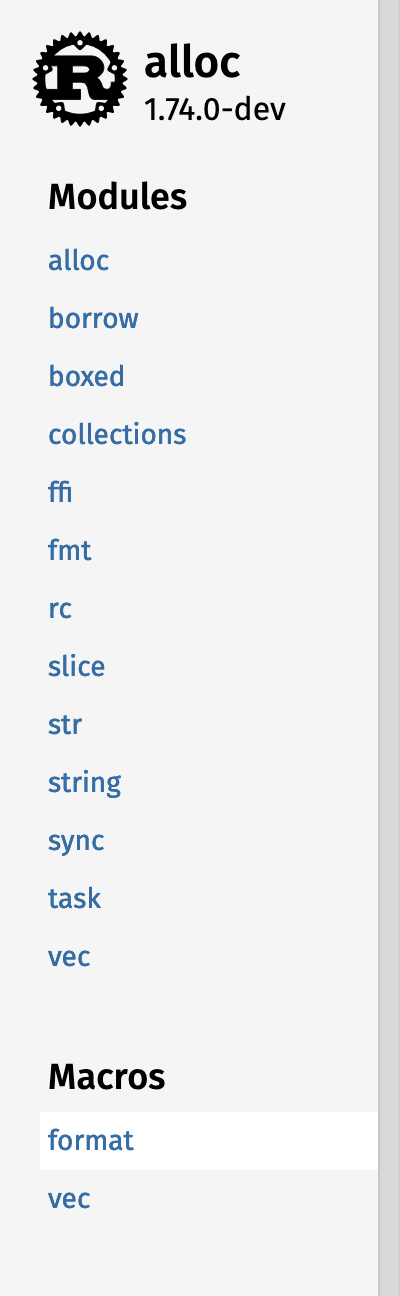 | 
| In module | 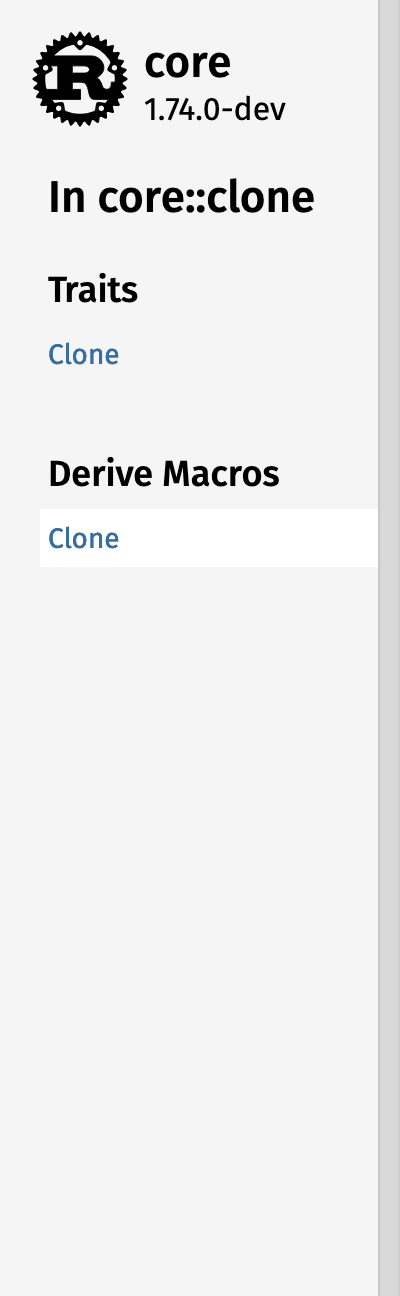 | 
#### Different logo configurations
| | Short crate name | Long crate name |
|---------|------------------|-----------------|
| Root | ![short-root] | ![long-root]
| Subpage | ![short-subpage] | ![long-subpage]
[short-root]: https://github.com/rust-lang/rust/assets/1593513/9e2b4fa8-f581-4106-b562-1e0372c13f79
[short-subpage]: https://github.com/rust-lang/rust/assets/1593513/8331cdb8-fa13-4671-a1e2-dcc1cdca7451
[long-root]: https://github.com/rust-lang/rust/assets/1593513/7d377fec-0f1d-4343-9f82-0e35a8f58056
[long-subpage]: https://github.com/rust-lang/rust/assets/1593513/3b3094a4-63c9-477c-8c15-b6075837df30
##### Without a logo

### Preview pages
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rocket/rocket/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rocket/rocket_sync_db_pools/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rust-compiler/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rust/std/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rocket/tokio/index.html
## Motivation
This improves visual information density (the construct with the logo and crate name is *shorter* than the logo on its own, because it's not square) and navigation clarity (we can now see what clicking the Rust logo does, specifically).
Compare this with the layout at [Phoenix's Hexdocs] (which is what this proposal is closely based on), the old proposal on [Internals Discourse] (which always says "Rust standard library" in the sidebar, but doesn't do the side-by-side layout).
[Phoenix's Hexdocs]: https://hexdocs.pm/phoenix/1.7.7/overview.html
[Internals Discourse]: https://internals.rust-lang.org/t/poc-of-a-new-design-for-the-generated-rustdoc/11018
## Guide-level explanation
This PR cleans up some of the sidebar navigation.
It makes the logo in the desktop sidebar a bit smaller, and puts the crate name and version next to it (either beside it, or below it, depending on if there's space), making it clearer what clicking on it does: click the crate name to open the crate's home page. It also removes the Rust logo from non-official-Rust crates, again to make the navigation and supply chain clearer (since the crate name has been added, the logo is no longer necessary for navigation).
It adds a bit more clarifying information for lateral navigation. On items that don't add their own sidebar items, it just shows its siblings directly below the crate name and logo, but for other items, it shows "In crate alloc" instead of just "In alloc". It also shows the lateral navigation tools on module pages, making modules consistent with every other item.
## Drawbacks
While this actually takes up less screen real estate than the old layout on desktop, it takes up more HTML. It's also a bit more visually complex.
## Rationale and alternatives
I could do what the Internals POC did and keep the vertically stacked layout all the time, instead of doing a horizontal stack where possible. It would take up more screen real estate, though.
## Prior art
This design is lifted almost verbatim from Hexdocs. It seems to work for them. [`opentelemetry_process_propagator`], for example, has a long application name.
[`opentelemetry_process_propagator`]: https://hexdocs.pm/opentelemetry_process_propagator/OpentelemetryProcessPropagator.html
## Unresolved questions
Maybe we should encourage crate authors to include their own logo more often? It certainly helps give people a better sense of "place." This seems to be blocked on coming up with an API to do it without requiring them to host the file somewhere.
## Future possibilities
Beyond this, plenty of other changes could be made to improve the layout, like
* Fix things so that clicking an item in the sidebar doesn't cause it to scroll back to the top.
* The [Internals demo](https://utherii.github.io/new.html) does this right: clicking an item in the sidebar changes the content area, but the sidebar itself does not change. This is nice, because clicking is cheap and I can skim the opening few paragraphs while browsing.
* The layout of the docs sidebar causes trouble to implement this, because it's different on different pages, but at least fix this on the file browser.
* Come up with a less cluttered way to do disclosure. There's a lot of `[-]` on the page.
* We don't lack ideas to fix this one. We have *too many*.
* Do a better job of separating local navigation (vec::Vec links to vec::IntoIter) and the table of contents (vec::Vec links to vec::Vec::new).
* A possibility: add a Back arrow next to the "In [module]" header?
* Give readers more control of how much rustdoc shows them, and giving doc authors more control of how much it generates. Basically, https://github.com/rust-lang/rust/pull/115660 is great, let's do it too.
But those are mostly orthogonal, not future possibilities unlocked by this change.
|
|
Add explicit-endian String::from_utf16 variants
This adds the following APIs under `feature(str_from_utf16_endian)`:
```rust
impl String {
pub fn from_utf16le(v: &[u8]) -> Result<String, FromUtf16Error>;
pub fn from_utf16le_lossy(v: &[u8]) -> String;
pub fn from_utf16be(v: &[u8]) -> Result<String, FromUtf16Error>;
pub fn from_utf16be_lossy(v: &[u8]) -> String;
}
```
These are versions of `String::from_utf16` that explicitly take [UTF-16LE and UTF-16BE](https://unicode.org/faq/utf_bom.html#gen7). Notably, we can do better than just the obvious `decode_utf16(v.array_chunks::<2>().copied().map(u16::from_le_bytes)).collect()` in that:
- We handle the case where the byte slice is not an even number of bytes, and
- In the case that the UTF-16 is native endian and the slice is aligned, we can forward to `String::from_utf16`.
If the Unicode Consortium actively defines how to handle character replacement when decoding a UTF-16 bytestream with a trailing odd byte, I was unable to find reference. However, the behavior implemented here is fairly self-evidently correct: replace the single errant byte with the replacement character.
|
