| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
Stabilize `atomic_from_ptr`
This stabilizes `atomic_from_ptr` and moves the const gate to `const_atomic_from_ptr`. Const stability is blocked on `const_mut_refs`.
Tracking issue: #108652
Newly stable API:
```rust
// core::atomic
impl AtomicBool { pub unsafe fn from_ptr<'a>(ptr: *mut bool) -> &'a AtomicBool; }
impl<T> AtomicPtr<T> { pub unsafe fn from_ptr<'a>(ptr: *mut *mut T) -> &'a AtomicPtr<T>; }
impl AtomicU8 { pub unsafe fn from_ptr<'a>(ptr: *mut u8) -> &'a AtomicU8; }
impl AtomicU16 { pub unsafe fn from_ptr<'a>(ptr: *mut u16) -> &'a AtomicU16; }
impl AtomicU32 { pub unsafe fn from_ptr<'a>(ptr: *mut u32) -> &'a AtomicU32; }
impl AtomicU64 { pub unsafe fn from_ptr<'a>(ptr: *mut u64) -> &'a AtomicU64; }
impl AtomicUsize { pub unsafe fn from_ptr<'a>(ptr: *mut usize) -> &'a AtomicUsize; }
impl AtomicI8 { pub unsafe fn from_ptr<'a>(ptr: *mut i8) -> &'a AtomicI8; }
impl AtomicI16 { pub unsafe fn from_ptr<'a>(ptr: *mut i16) -> &'a AtomicI16; }
impl AtomicI32 { pub unsafe fn from_ptr<'a>(ptr: *mut i32) -> &'a AtomicI32; }
impl AtomicI64 { pub unsafe fn from_ptr<'a>(ptr: *mut i64) -> &'a AtomicI64; }
impl AtomicIsize { pub unsafe fn from_ptr<'a>(ptr: *mut isize) -> &'a AtomicIsize; }
```
|
|
...instead of hand rolling impls, since
1. It's nicer
2. It fixes a buggy `Ord` impl of `SocketAddrV6`, which ignored half of the fields
|
|
|
|
* Remove duplicate alignment note that mentioned `AtomicBool` with other
types
* Update safety requirements about when non-atomic operations are
allowed
|
|
This reverts commit 93677276bc495e78f74536385a16201d465fd523
because it caused issues for projects building the standard
library with non-cargo build systems.
|
|
DaniPopes:stabilize-const_maybe_uninit_assume_init_read, r=dtolnay
Stabilize `const_maybe_uninit_assume_init_read`
AFAICT the only reason this was not included in the `maybe_uninit_extra` stabilization was because `ptr::read` was unstable (https://github.com/rust-lang/rust/pull/92768#issuecomment-1011101383), which has since been stabilized in 1.71.
Needs a separate FCP from the [original `maybe_uninit_extra` one](https://github.com/rust-lang/rust/issues/63567#issuecomment-964428807).
Tracking issue: #63567
|
|
Fix exit status / wait status on non-Unix cfg(unix) platforms
Fixes #114593
Needs FCP due to behavioural changes (NB only on non-Unix `#[cfg(unix)]` platforms).
Also, I think this is likely to break in CI. I have not been yet able to compile the new bits of `process_unsupported.rs`, although I have compiled the new module. I'd like some help from people familiar with eg emscripten and fuchsia (which are going to be affected, I think).
|
|
|
|
|
|
According to the POSIX standard, if connect() is interrupted by a
signal that is caught while blocked waiting to establish a connection,
connect() shall fail and set errno to EINTR, but the connection
request shall not be aborted, and the connection shall be established
asynchronously.
If asynchronous connection was successfully established after EINTR
and before the next connection attempt, OS returns EISCONN that was
handled as an error before. This behavior is fixed now and we handle
it as success.
The problem affects MacOS users: Linux doesn't return EISCONN in this
case, Windows connect() can not be interrupted without an old-fashoin
WSACancelBlockingCall function that is not used in the library.
So current solution gives connect() as OS specific implementation.
|
|
|
|
|
|
|
|
|
|
`fs::try_exists` currently fails on Windows if encountering a Unix Domain Socket (UDS). Fix this by checking for an error code that's returned when there's a failure to use a reparse point.
A reparse point is a way to invoke a filesystem filter on a file instead of the file being opened normally. This is used to implement symbolic links (by redirecting to a different path) but also to implement other types of special files such as Unix domain sockets. If the reparse point is not a link type then opening it with `CreateFileW` may fail with `ERROR_CANT_ACCESS_FILE` because the filesystem filter does not implement that operation. This differs from resolving links which may fail with errors such as `ERROR_FILE_NOT_FOUND` or `ERROR_CANT_RESOLVE_FILENAME`.
So `ERROR_CANT_ACCESS_FILE` means that the file exists but that we can't open it normally. Still, the file does exist so `try_exists` should report that as `Ok(true)`.
|
|
Co-authored-by: David Tolnay <dtolnay@gmail.com>
|
|
|
|
Remove unnecessary tmp variable in default_read_exact
This `tmp` variable has existed since the original implementation (added in ff81920f03866674080ac63b565cc9d30f80c450), but it's not necessary (maybe non-lexical lifetimes helped?).
It's common to read std source code to understand how things actually work, and this tripped me up on my first read.
|
|
Implement `slice::split_once` and `slice::rsplit_once`
Feature gate is `slice_split_once` and tracking issue is #112811. These are equivalents to the existing `str::split_once` and `str::rsplit_once` methods.
|
|
rustdoc: show crate name beside smaller logo
*Blocked on https://github.com/rust-lang/cargo/pull/12800*
## Summary
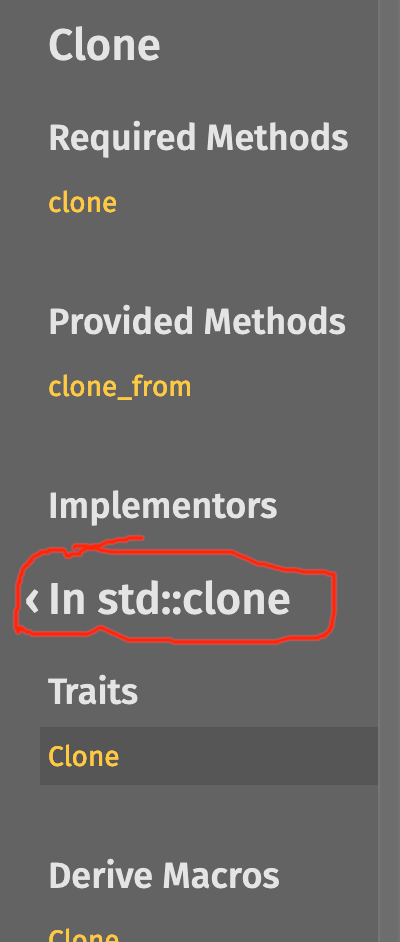
In this PR, the crate name and version are always shown in the sidebar, even in subpages, and the lateral navigation is always shown in the sidebar, even in modules.
Clicking the crate name does the same thing clicking the logo always did: take you to the crate root (the crate's home page, at least within Rustdoc).
The Rust logo is also no longer shown by default for non-Rust docs.
### Screenshots
<details><summary>Before</summary>
| | Macro | Module |
|--|-------|--------|
| In crate | 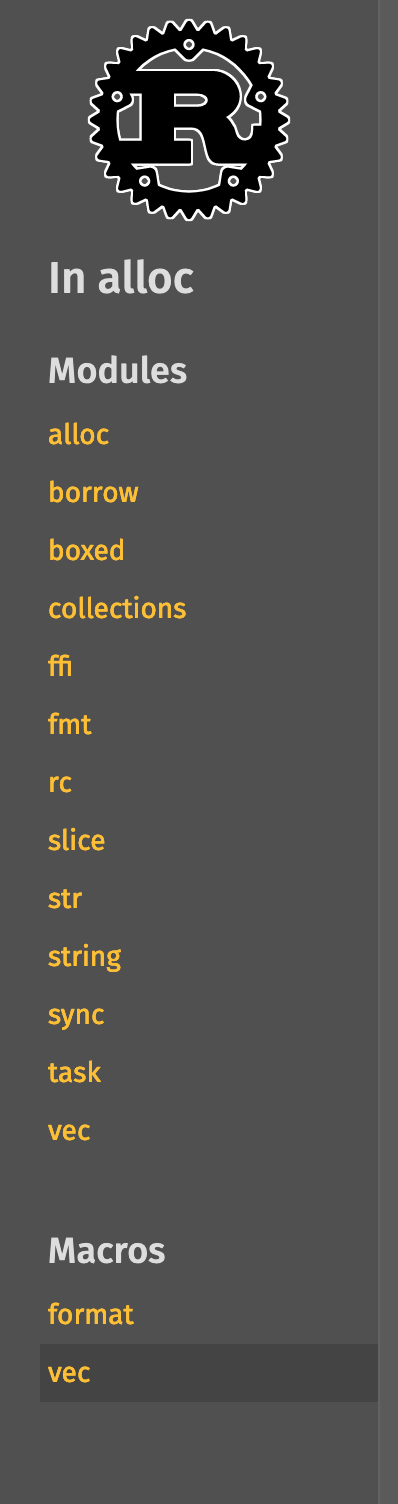 |
| In module[^1] | 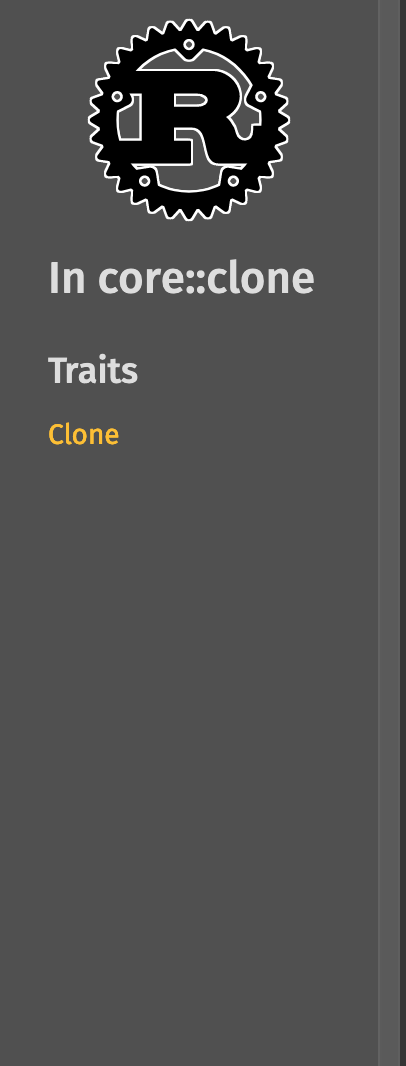 | 
[^1]: This PR also includes a bug fix for derive macros not showing up in the lateral navigation part of the sidebar
</details>
#### Whole sidebar screenshots
| | Macro | Module |
|--|-------|--------|
| In crate | 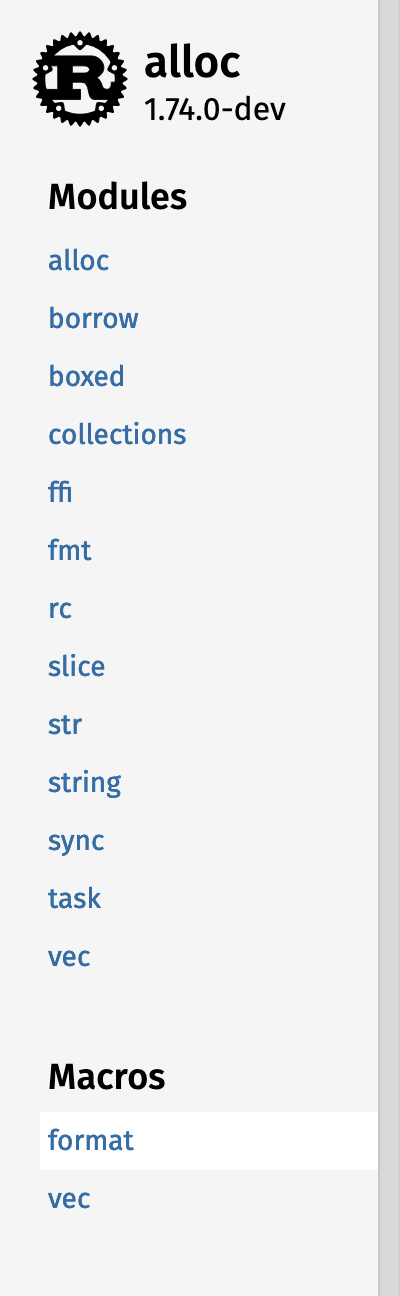 | 
| In module | 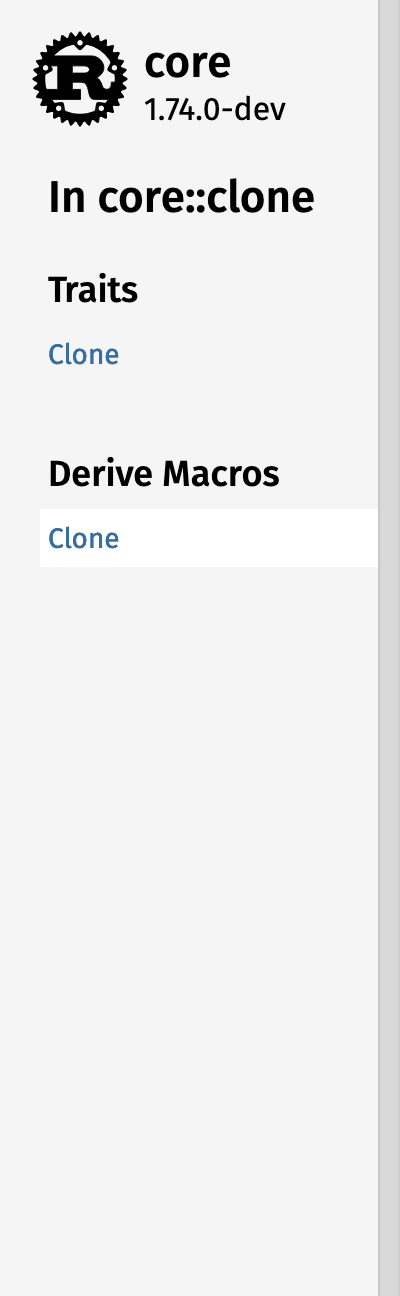 | 
#### Different logo configurations
| | Short crate name | Long crate name |
|---------|------------------|-----------------|
| Root | ![short-root] | ![long-root]
| Subpage | ![short-subpage] | ![long-subpage]
[short-root]: https://github.com/rust-lang/rust/assets/1593513/9e2b4fa8-f581-4106-b562-1e0372c13f79
[short-subpage]: https://github.com/rust-lang/rust/assets/1593513/8331cdb8-fa13-4671-a1e2-dcc1cdca7451
[long-root]: https://github.com/rust-lang/rust/assets/1593513/7d377fec-0f1d-4343-9f82-0e35a8f58056
[long-subpage]: https://github.com/rust-lang/rust/assets/1593513/3b3094a4-63c9-477c-8c15-b6075837df30
##### Without a logo

### Preview pages
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rocket/rocket/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rocket/rocket_sync_db_pools/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rust-compiler/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rust/std/index.html
https://notriddle.com/rustdoc-html-demo-5/sidebar-layout-rocket/tokio/index.html
## Motivation
This improves visual information density (the construct with the logo and crate name is *shorter* than the logo on its own, because it's not square) and navigation clarity (we can now see what clicking the Rust logo does, specifically).
Compare this with the layout at [Phoenix's Hexdocs] (which is what this proposal is closely based on), the old proposal on [Internals Discourse] (which always says "Rust standard library" in the sidebar, but doesn't do the side-by-side layout).
[Phoenix's Hexdocs]: https://hexdocs.pm/phoenix/1.7.7/overview.html
[Internals Discourse]: https://internals.rust-lang.org/t/poc-of-a-new-design-for-the-generated-rustdoc/11018
## Guide-level explanation
This PR cleans up some of the sidebar navigation.
It makes the logo in the desktop sidebar a bit smaller, and puts the crate name and version next to it (either beside it, or below it, depending on if there's space), making it clearer what clicking on it does: click the crate name to open the crate's home page. It also removes the Rust logo from non-official-Rust crates, again to make the navigation and supply chain clearer (since the crate name has been added, the logo is no longer necessary for navigation).
It adds a bit more clarifying information for lateral navigation. On items that don't add their own sidebar items, it just shows its siblings directly below the crate name and logo, but for other items, it shows "In crate alloc" instead of just "In alloc". It also shows the lateral navigation tools on module pages, making modules consistent with every other item.
## Drawbacks
While this actually takes up less screen real estate than the old layout on desktop, it takes up more HTML. It's also a bit more visually complex.
## Rationale and alternatives
I could do what the Internals POC did and keep the vertically stacked layout all the time, instead of doing a horizontal stack where possible. It would take up more screen real estate, though.
## Prior art
This design is lifted almost verbatim from Hexdocs. It seems to work for them. [`opentelemetry_process_propagator`], for example, has a long application name.
[`opentelemetry_process_propagator`]: https://hexdocs.pm/opentelemetry_process_propagator/OpentelemetryProcessPropagator.html
## Unresolved questions
Maybe we should encourage crate authors to include their own logo more often? It certainly helps give people a better sense of "place." This seems to be blocked on coming up with an API to do it without requiring them to host the file somewhere.
## Future possibilities
Beyond this, plenty of other changes could be made to improve the layout, like
* Fix things so that clicking an item in the sidebar doesn't cause it to scroll back to the top.
* The [Internals demo](https://utherii.github.io/new.html) does this right: clicking an item in the sidebar changes the content area, but the sidebar itself does not change. This is nice, because clicking is cheap and I can skim the opening few paragraphs while browsing.
* The layout of the docs sidebar causes trouble to implement this, because it's different on different pages, but at least fix this on the file browser.
* Come up with a less cluttered way to do disclosure. There's a lot of `[-]` on the page.
* We don't lack ideas to fix this one. We have *too many*.
* Do a better job of separating local navigation (vec::Vec links to vec::IntoIter) and the table of contents (vec::Vec links to vec::Vec::new).
* A possibility: add a Back arrow next to the "In [module]" header?
* Give readers more control of how much rustdoc shows them, and giving doc authors more control of how much it generates. Basically, https://github.com/rust-lang/rust/pull/115660 is great, let's do it too.
But those are mostly orthogonal, not future possibilities unlocked by this change.
|
|
Add explicit-endian String::from_utf16 variants
This adds the following APIs under `feature(str_from_utf16_endian)`:
```rust
impl String {
pub fn from_utf16le(v: &[u8]) -> Result<String, FromUtf16Error>;
pub fn from_utf16le_lossy(v: &[u8]) -> String;
pub fn from_utf16be(v: &[u8]) -> Result<String, FromUtf16Error>;
pub fn from_utf16be_lossy(v: &[u8]) -> String;
}
```
These are versions of `String::from_utf16` that explicitly take [UTF-16LE and UTF-16BE](https://unicode.org/faq/utf_bom.html#gen7). Notably, we can do better than just the obvious `decode_utf16(v.array_chunks::<2>().copied().map(u16::from_le_bytes)).collect()` in that:
- We handle the case where the byte slice is not an even number of bytes, and
- In the case that the UTF-16 is native endian and the slice is aligned, we can forward to `String::from_utf16`.
If the Unicode Consortium actively defines how to handle character replacement when decoding a UTF-16 bytestream with a trailing odd byte, I was unable to find reference. However, the behavior implemented here is fairly self-evidently correct: replace the single errant byte with the replacement character.
|
|
|
|
Mark `new_in` as `const` for BTree collections
Discussed in and closes rust-lang/wg-allocators#118
|
|
* Entries in the callsite table now use a dedicated function for reading an offset rather than a pointer
* `read_encoded_pointer` uses that new function for reading offsets when the "application" part of the encoding indicates an offset (relative to some pointer)
* It now errors out on nonsensical "application" and "value encoding" combinations
Inspired by @eddyb's comment on zulip about this:
<https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/strict.20provenance.20in.20dwarf.3A.3Aeh/near/276197290>
|
|
This bring unwind and personality code more in line with strict-provenance
|
|
|
|
|
|
|
|
Closes rust-lang/wg-allocators#118
|
|
|
|
|
|
|
|
To get GNU/Hurd support, so that CI of external repositories (e.g. getrandom)
can build std.
|
|
r=dtolnay
Fix generic bound of `str::SplitInclusive`'s `DoubleEndedIterator` impl
`str::SplitInclusive`'s `DoubleEndedIterator` implementation currently uses a `ReverseSearcher` bound for the corresponding searcher. A `DoubleEndedSearcher` bound should have been used instead.
`DoubleEndedIterator` requires that repeated `next_back` calls produce the same items as repeated `next` calls, in opposite order. `ReverseSearcher` lets you search starting from the back of a string, but it makes no guarantees about how its matches correspond to the matches found by a forward search. `DoubleEndedSearcher` is a subtrait of `ReverseSearcher` and does require that the same matches are found in both directions.
This bug fix is a breaking change. Calling `next_back` on `"a+++b".split_inclusive("++")` is currently accepted with repeated calls producing `"b"` and `"a+++"`, while forward iteration yields `"a++"` and `"+b"`. Also see https://github.com/rust-lang/rust/issues/100756#issuecomment-1221307166 for more details.
I believe that this is the only iterator that uses this bound incorrectly — other related iterators such as `str::Split` do have a `DoubleEndedSearcher` bound for their `DoubleEndedIterator` implementation. And `slice::SplitInclusive` doesn't face this problem at all because it doesn't use patterns, only a predicate.
cc `@SkiFire13`
|
|
Uncomment the assert! line and account and document that the sign
of NaN is not positive, necessarily.
|
|
|
|
r=workingjubilee
Use `HashMap::with_capacity_and_hasher` instead of using base
Cleans up the internal logic for `HashMap::with_capacity` slightly.
|
|
This variable seems to serve no purpose, and it's a little confusing
when reading std source code, so remove it.
|
|
Invoke `backtrace-rs` buildscript in `std` buildscript
Based on #99883 by `@Arc-blroth`
Depends on rust-lang/backtrace-rs#556 and rust-lang/cc-rs#705
|
|
Rollup of 4 pull requests
Successful merges:
- #116277 (dont call mir.post_mono_checks in codegen)
- #116400 (Detect missing `=>` after match guard during parsing)
- #116458 (Properly export function defined in test which uses global_asm!())
- #116500 (Add tvOS to target_os for register_dtor)
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
r=workingjubilee
Add tvOS to target_os for register_dtor
Closes #116491.
|
|
Use `io_error_more` on WASI
#86442 added many variants to [`io::ErrorKind`](https://doc.rust-lang.org/stable/std/io/enum.ErrorKind.html), but `sys::wasi::decode_error_kind()` wasn't modified to use them.
The preview1 `errno` list:
https://github.com/WebAssembly/WASI/blob/4712d490fd7662f689af6faa5d718e042f014931/legacy/preview1/docs.md#-errno-variant
Original implementation: #63814
`@rustbot` label +A-error-handling +C-enhancement +O-wasi
|
|
|
|
Minor doc clarification in Once::call_once
|
|
Reuse existing `Some`s in `Option::(x)or`
LLVM still has trouble re-using discriminants sometimes when rebuilding a two-variant enum, so when we have the correct variant already built, just use it.
That's shorter in the Rust code, as well as simpler in MIR and the optimized LLVM, so might as well: <https://rust.godbolt.org/z/KhdE8eToW>
Thanks to `@veber-alex` for pointing out this opportunity in https://github.com/rust-lang/rust/issues/101210#issuecomment-1732470941
|
|
Attempt to describe the intent behind the `From` trait further
Inspired by the <https://internals.rust-lang.org/t/allow-use-as-and-try-as-for-from-and-tryfrom-traits/19240/26?u=scottmcm> thread.
`@rustbot` label +T-libs-api
|
|
|
|
|
|
Rollup of 6 pull requests
Successful merges:
- #115454 (Clarify example in docs of str::char_slice)
- #115522 (Clarify ManuallyDrop bit validity)
- #115588 (Fix a comment in std::iter::successors)
- #116198 (Add more diagnostic items for clippy)
- #116329 (update some comments around swap())
- #116475 (rustdoc-search: fix bug with multi-item impl trait)
r? `@ghost`
`@rustbot` modify labels: rollup
|
