| Age | Commit message (Collapse) | Author | Lines |
|---|
|
Set ninja=true by default
Ninja substantially improves LLVM build time. On a 96-way system, using
Make took 248s, and using Ninja took 161s, a 35% improvement.
We already require a variety of tools to build Rust. If someone wants to
build without Ninja (for instance, to minimize the set of packages
required to bootstrap a new target), they can easily set `ninja=false`
in `config.toml`. Our defaults should help people build Rust (and LLVM)
faster, to speed up development.
|
|
|
|
Bump version to 1.48 and update cfg(bootstrap)s
r? @Mark-Simulacrum
|
|
Fixes for VxWorks
r? @alexcrichton
|
|
Let people know that they can set ninja=false if they don't want to
install ninja.
|
|
Ninja substantially improves LLVM build time. On a 96-way system, using
Make took 248s, and using Ninja took 161s, a 35% improvement.
We already require a variety of tools to build Rust. If someone wants to
build without Ninja (for instance, to minimize the set of packages
required to bootstrap a new target), they can easily set `ninja=false`
in `config.toml`. Our defaults should help people build Rust (and LLVM)
faster, to speed up development.
|
|
|
|
fix building errors
use wr-c++ as linker
|
|
Introduce expect snapshot testing library into rustc
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:
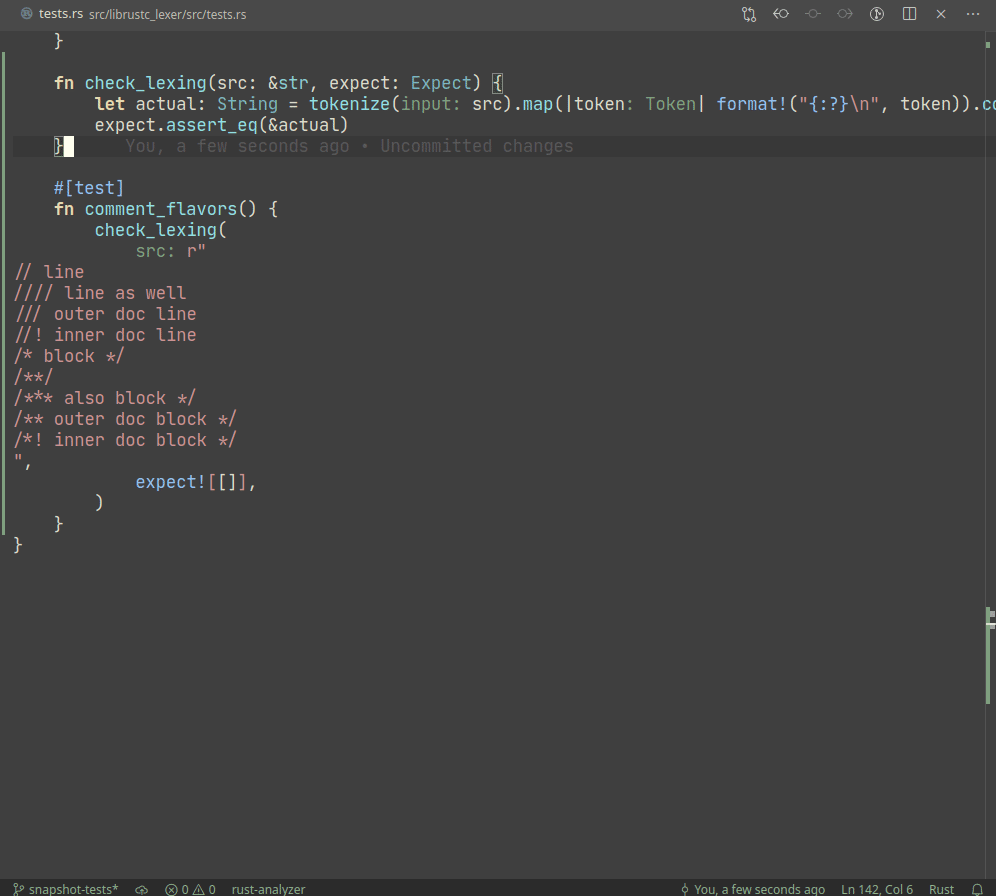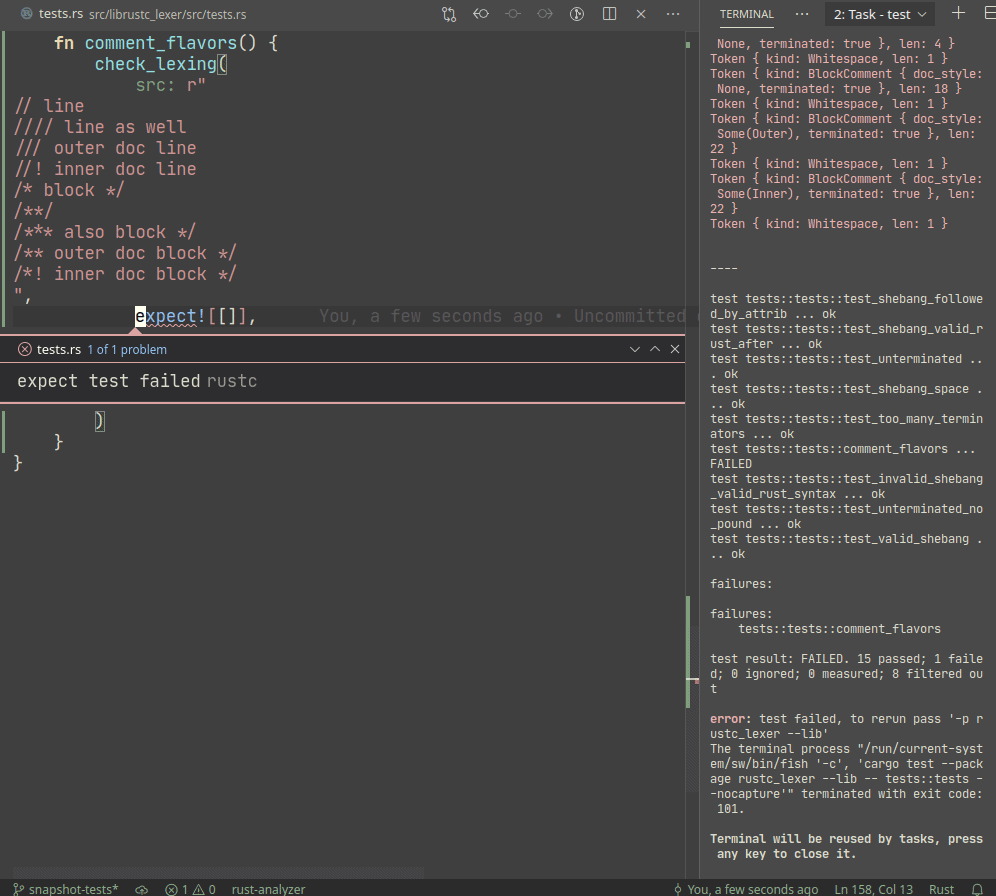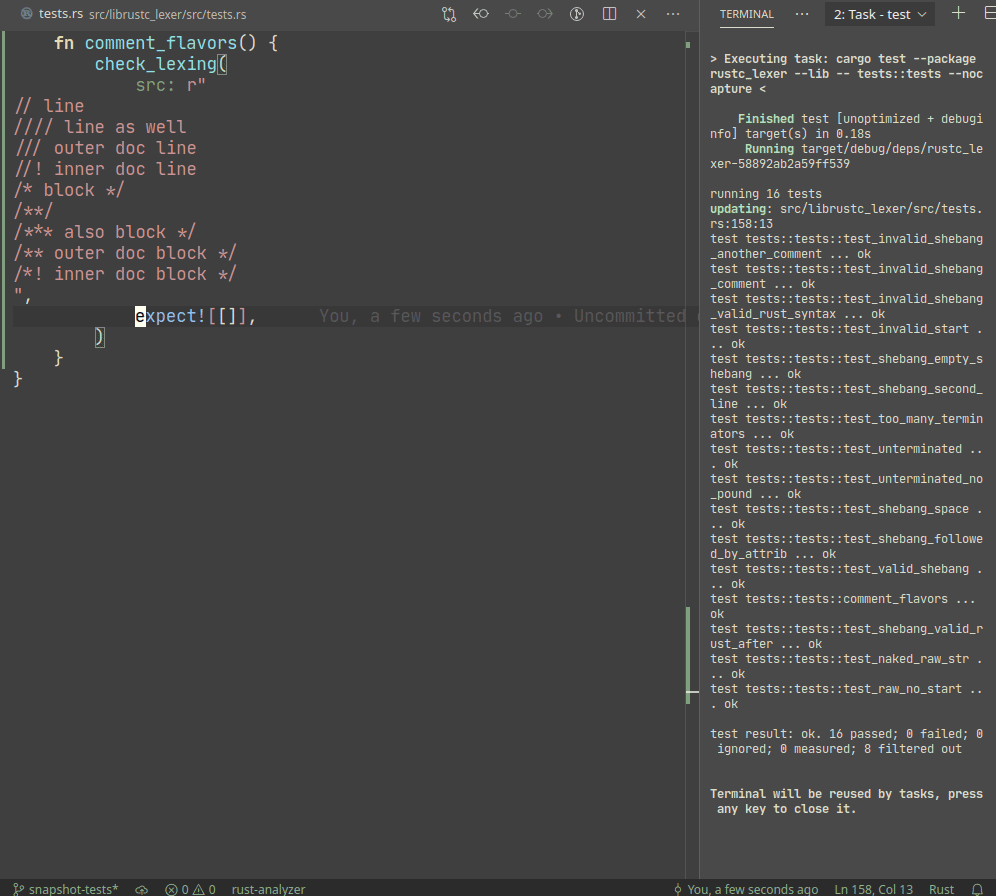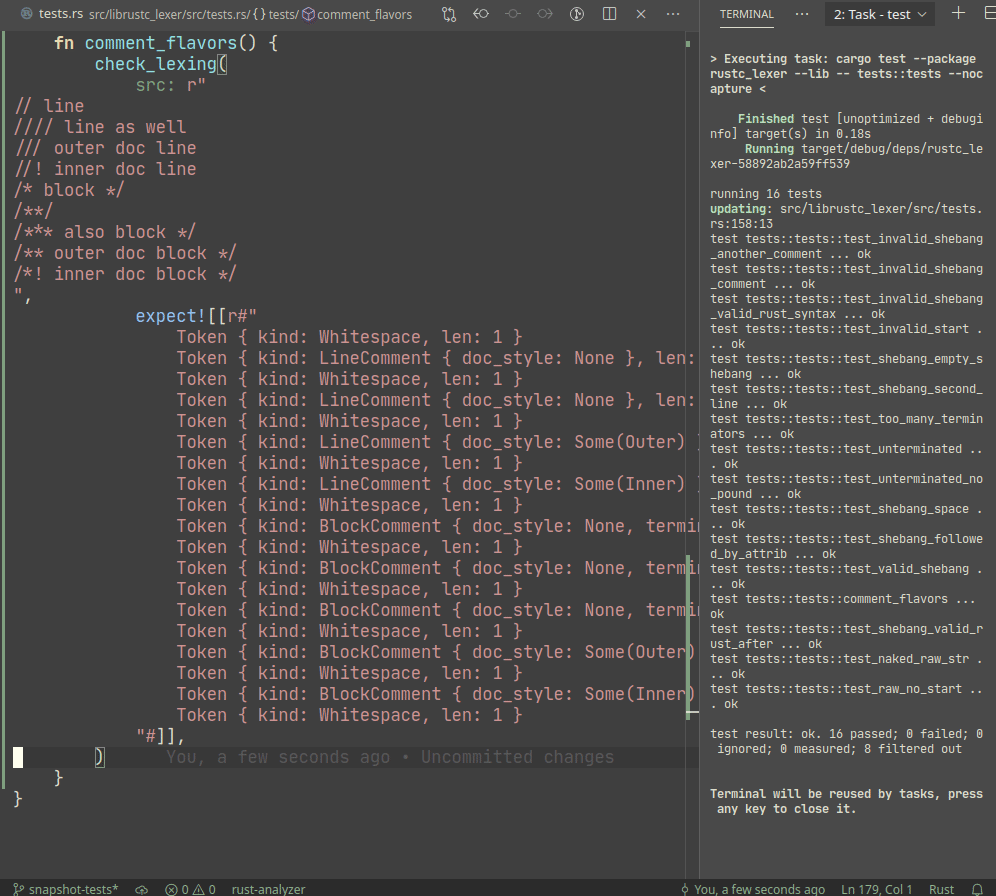
A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See rust-analyzer/rust-analyzer#5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
|
|
Fix windows-gnu host cross-compilation
Fixes https://github.com/rust-lang/rust/issues/64218
Also turns out it's faster to run Linux virtual machine on Windows and cross-compile `./x.py dist` than doing it on Windows directly...
|
|
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:

A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See https://github.com/rust-analyzer/rust-analyzer/pull/5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
|
|
clippy::print_literal
clippy::clone_on_copy
clippy::single_char_pattern
clippy::into_iter_on_ref
clippy::match_like_matches_macro
|
|
r=pietroalbini
Adjust installation place for compiler docs
This avoids conflicts when installing with rustup; rustup does not currently
support overlapping installations.
r? @matthiaskrgr
|
|
|
|
cmake-rs@8141f0e changed the logic for handling asm compiler flags.
This change was pulled in with the cmake 0.1.42 -> 0.1.44 update.
This introduced two new flags to the LLVM build, breaking it:
"-DCMAKE_ASM_FLAGS= -ffunction-sections -fdata-sections -fPIC -m64"
"-DCMAKE_ASM_COMPILER=/usr/bin/cc"
This patch should resolve the breakage by handling it in bootstrap.
|
|
Add option to use the new symbol mangling in rustc/std
I don't know if this causes problems in some cases -- maybe it should be on by default for at least rustc. I've never encountered problems with it other than tools not supporting it, though.
cc @nnethercote
r? @eddyb
|
|
This avoids conflicts when installing with rustup; rustup does not currently
support overlapping installations.
|
|
Add sanitizer support on FreeBSD
Restarting #47337. Everything is better now, no more weird llvm problems, well not everything:
Unfortunately, the sanitizers don't have proper support for versioned symbols (https://github.com/google/sanitizers/issues/628), so `libc`'s usage of `stat@FBSD_1.0` and so on explodes, e.g. in calling `std::fs::metadata`.
Building std (now easy thanks to cargo `-Zbuild-std`) and libc with `freebsd12/13` config via the `LIBC_CI=1` env variable is a good workaround…
```
LIBC_CI=1 RUSTFLAGS="-Z sanitizer=address" cargo +san-test -Zbuild-std run --target x86_64-unknown-freebsd --verbose
```
…*except* std won't build because there's no `st_lspare` in the ino64 version of the struct, so an std patch is required:
```diff
--- i/src/libstd/os/freebsd/fs.rs
+++ w/src/libstd/os/freebsd/fs.rs
@@ -66,8 +66,6 @@ pub trait MetadataExt {
fn st_flags(&self) -> u32;
#[stable(feature = "metadata_ext2", since = "1.8.0")]
fn st_gen(&self) -> u32;
- #[stable(feature = "metadata_ext2", since = "1.8.0")]
- fn st_lspare(&self) -> u32;
}
#[stable(feature = "metadata_ext", since = "1.1.0")]
@@ -136,7 +134,4 @@ impl MetadataExt for Metadata {
fn st_flags(&self) -> u32 {
self.as_inner().as_inner().st_flags as u32
}
- fn st_lspare(&self) -> u32 {
- self.as_inner().as_inner().st_lspare as u32
- }
}
```
I guess std could like.. detect that `libc` isn't built for the old ABI, and replace the implementation of `st_lspare` with a panic?
|
|
r=Mark-Simulacrum
Fix crate-version with rustdoc in bootstrap.
Cargo will now automatically use the `--crate-version` flag (see https://github.com/rust-lang/cargo/pull/8509). Cargo has special handling to avoid passing the flag if it is passed in via RUSTDOCFLAGS, but the `rustdoc` wrapper circumvents that check. This causes a problem because rustdoc will fail if the flag is passed in twice. Fix this by using RUSTDOCFLAGS.
This will be necessary when 1.47 is promoted to beta, but should be safe to do now.
|
|
|
|
Set CMAKE_SYSTEM_NAME when cross-compiling
Configure CMAKE_SYSTEM_NAME when cross-compiling in `configure_cmake`,
to tell CMake about target system. Previously this was done only for
LLVM step and now applies more generally to steps using cmake.
Helps with #74576.
|
|
|
|
|
|
Configure CMAKE_SYSTEM_NAME when cross-compiling in `configure_cmake`,
to tell CMake about target system. Previously this was done only for
LLVM step and now applies more generally to steps using cmake.
|
|
|
|
|
|
|
|
Make rust.use-lld config option work with non MSVC targets
Builds fine and passes tests on Linux.
Not overriding `use-lld` by `linker` makes sense on those platforms since very old GCC versions don't understand `-fuse-ld=lld`. This allows pointing to newer GCC or Clang that will know how to call LLD.
|
|
|
|
riscv64 has an LLVM bug that makes rust-analyzer not build.
|
|
compiletest: Support ignoring tests requiring missing LLVM components
This PR implements a more principled solution to the problem described in https://github.com/rust-lang/rust/pull/66084.
Builds of LLVM backends take a lot of time and disk space.
So it usually makes sense to build rustc with
```toml
[llvm]
targets = "X86"
experimental-targets = ""
```
unless you are working on some target-specific tasks.
A few tests, however, require non-x86 backends to be built.
A new test directive `// needs-llvm-components: component1 component2 component3` makes such tests to be automatically ignored if one of the listed components is missing in the provided LLVM (this is determined through `llvm-config --components`).
As a result, the test suite now fully passes with LLVM built only with the x86 backend. The component list in this case is
```
aggressiveinstcombine all all-targets analysis asmparser asmprinter binaryformat bitreader bitstreamreader bitwriter cfguard codegen core coroutines coverage debuginfocodeview debuginfodwarf debuginfogsym debuginfomsf debuginfopdb demangle dlltooldriver dwarflinker engine executionengine frontendopenmp fuzzmutate globalisel instcombine instrumentation interpreter ipo irreader jitlink libdriver lineeditor linker lto mc mca mcdisassembler mcjit mcparser mirparser native nativecodegen objcarcopts object objectyaml option orcerror orcjit passes profiledata remarks runtimedyld scalaropts selectiondag support symbolize tablegen target textapi transformutils vectorize windowsmanifest x86 x86asmparser x86codegen x86desc x86disassembler x86info x86utils xray
```
(With the default target list it's much larger.)
```
aarch64 aarch64asmparser aarch64codegen aarch64desc aarch64disassembler aarch64info aarch64utils aggressiveinstcombine all all-targets analysis arm armasmparser armcodegen armdesc armdisassembler arminfo armutils asmparser asmprinter avr avrasmparser avrcodegen avrdesc avrdisassembler avrinfo binaryformat bitreader bitstreamreader bitwriter cfguard codegen core coroutines coverage debuginfocodeview debuginfodwarf debuginfogsym debuginfomsf debuginfopdb demangle dlltooldriver dwarflinker engine executionengine frontendopenmp fuzzmutate globalisel hexagon hexagonasmparser hexagoncodegen hexagondesc hexagondisassembler hexagoninfo instcombine instrumentation interpreter ipo irreader jitlink libdriver lineeditor linker lto mc mca mcdisassembler mcjit mcparser mips mipsasmparser mipscodegen mipsdesc mipsdisassembler mipsinfo mirparser msp430 msp430asmparser msp430codegen msp430desc msp430disassembler msp430info native nativecodegen nvptx nvptxcodegen nvptxdesc nvptxinfo objcarcopts object objectyaml option orcerror orcjit passes powerpc powerpcasmparser powerpccodegen powerpcdesc powerpcdisassembler powerpcinfo profiledata remarks riscv riscvasmparser riscvcodegen riscvdesc riscvdisassembler riscvinfo riscvutils runtimedyld scalaropts selectiondag sparc sparcasmparser sparccodegen sparcdesc sparcdisassembler sparcinfo support symbolize systemz systemzasmparser systemzcodegen systemzdesc systemzdisassembler systemzinfo tablegen target textapi transformutils vectorize webassembly webassemblyasmparser webassemblycodegen webassemblydesc webassemblydisassembler webassemblyinfo windowsmanifest x86 x86asmparser x86codegen x86desc x86disassembler x86info x86utils xray
```
https://github.com/rust-lang/rust/pull/66084 is also reverted now.
r? @Mark-Simulacrum
|
|
|
|
These are quite long, usually, and in most cases not interesting. On smaller
terminals they can take up more than a full page of output, hiding the error
diagnostics emitted.
|
|
std: Switch from libbacktrace to gimli (take 2)
This is the second attempt to land https://github.com/rust-lang/rust/pull/73441 after being reverted in https://github.com/rust-lang/rust/pull/74613. Will be gathering precise perf numbers here in this take.
Closes #71060
|
|
update Miri
Fixes https://github.com/rust-lang/rust/issues/74580
Cc @rust-lang/miri r? @ghost
|
|
|
|
The directories for core, alloc, std, proc_macro, and test crates now
correspond directly to the crate name and stripping the "lib" prefix is
no longer necessary.
|
|
This commit is a proof-of-concept for switching the standard library's
backtrace symbolication mechanism on most platforms from libbacktrace to
gimli. The standard library's support for `RUST_BACKTRACE=1` requires
in-process parsing of object files and DWARF debug information to
interpret it and print the filename/line number of stack frames as part
of a backtrace.
Historically this support in the standard library has come from a
library called "libbacktrace". The libbacktrace library seems to have
been extracted from gcc at some point and is written in C. We've had a
lot of issues with libbacktrace over time, unfortunately, though. The
library does not appear to be actively maintained since we've had
patches sit for months-to-years without comments. We have discovered a
good number of soundness issues with the library itself, both when
parsing valid DWARF as well as invalid DWARF. This is enough of an issue
that the libs team has previously decided that we cannot feed untrusted
inputs to libbacktrace. This also doesn't take into account the
portability of libbacktrace which has been difficult to manage and
maintain over time. While possible there are lots of exceptions and it's
the main C dependency of the standard library right now.
For years it's been the desire to switch over to a Rust-based solution
for symbolicating backtraces. It's been assumed that we'll be using the
Gimli family of crates for this purpose, which are targeted at safely
and efficiently parsing DWARF debug information. I've been working
recently to shore up the Gimli support in the `backtrace` crate. As of a
few weeks ago the `backtrace` crate, by default, uses Gimli when loaded
from crates.io. This transition has gone well enough that I figured it
was time to start talking seriously about this change to the standard
library.
This commit is a preview of what's probably the best way to integrate
the `backtrace` crate into the standard library with the Gimli feature
turned on. While today it's used as a crates.io dependency, this commit
switches the `backtrace` crate to a submodule of this repository which
will need to be updated manually. This is not done lightly, but is
thought to be the best solution. The primary reason for this is that the
`backtrace` crate needs to do some pretty nontrivial filesystem
interactions to locate debug information. Working without `std::fs` is
not an option, and while it might be possible to do some sort of
trait-based solution when prototyped it was found to be too unergonomic.
Using a submodule allows the `backtrace` crate to build as a submodule
of the `std` crate itself, enabling it to use `std::fs` and such.
Otherwise this adds new dependencies to the standard library. This step
requires extra attention because this means that these crates are now
going to be included with all Rust programs by default. It's important
to note, however, that we're already shipping libbacktrace with all Rust
programs by default and it has a bunch of C code implementing all of
this internally anyway, so we're basically already switching
already-shipping functionality to Rust from C.
* `object` - this crate is used to parse object file headers and
contents. Very low-level support is used from this crate and almost
all of it is disabled. Largely we're just using struct definitions as
well as convenience methods internally to read bytes and such.
* `addr2line` - this is the main meat of the implementation for
symbolication. This crate depends on `gimli` for DWARF parsing and
then provides interfaces needed by the `backtrace` crate to turn an
address into a filename / line number. This crate is actually pretty
small (fits in a single file almost!) and mirrors most of what
`dwarf.c` does for libbacktrace.
* `miniz_oxide` - the libbacktrace crate transparently handles
compressed debug information which is compressed with zlib. This crate
is used to decompress compressed debug sections.
* `gimli` - not actually used directly, but a dependency of `addr2line`.
* `adler32`- not used directly either, but a dependency of
`miniz_oxide`.
The goal of this change is to improve the safety of backtrace
symbolication in the standard library, especially in the face of
possibly malformed DWARF debug information. Even to this day we're still
seeing segfaults in libbacktrace which could possibly become security
vulnerabilities. This change should almost entirely eliminate this
possibility whilc also paving the way forward to adding more features
like split debug information.
Some references for those interested are:
* Original addition of libbacktrace - #12602
* OOM with libbacktrace - #24231
* Backtrace failure due to use of uninitialized value - #28447
* Possibility to feed untrusted data to libbacktrace - #21889
* Soundness fix for libbacktrace - #33729
* Crash in libbacktrace - #39468
* Support for macOS, never merged - ianlancetaylor/libbacktrace#2
* Performance issues with libbacktrace - #29293, #37477
* Update procedure is quite complicated due to how many patches we
need to carry - #50955
* Libbacktrace doesn't work on MinGW with dynamic libs - #71060
* Segfault in libbacktrace on macOS - #71397
Switching to Rust will not make us immune to all of these issues. The
crashes are expected to go away, but correctness and performance may
still have bugs arise. The gimli and `backtrace` crates, however, are
actively maintained unlike libbacktrace, so this should enable us to at
least efficiently apply fixes as situations come up.
|
|
|
|
|
|
Improve defaults in x.py
- Make the default stage dependent on the subcommand
- Don't build stage1 rustc artifacts with x.py build --stage 1. If this is what you want, use x.py build --stage 2 instead, which gives you a working libstd.
- Change default debuginfo when debug = true from 2 to 1
I tried to fix CI to use `--stage 2` everywhere it currently has no stage, but I might have missed a spot.
This does not update much of the documentation - most of it is in https://github.com/rust-lang/rustc-dev-guide/ or https://github.com/rust-lang/rust-forge and will need a separate PR.
See individual commits for a detailed rationale of each change.
See also the MCP: https://github.com/rust-lang/compiler-team/issues/326
r? @Mark-Simulacrum , but anyone is free to give an opinion.
|
|
- Remove useless --stage 2 argument to checktools.sh
- Fix help text for expand-yaml-anchors (it had a typo)
|
|
|
|
rustbuild: use Display for exit status instead of Debug, see #74832 for justification
|
|
|
|
- Use stage 2 for makefile
- Move assert to builder
- Don't add an assert for --help
- Allow --stage 0 if passed explicitly
- Don't assert defaults during tests
Otherwise it's impossible to test the defaults!
|
|
- Only set stage 2 in dist tests
- Add test for `x.py doc` without args
- Add test for `x.py build` without args
- Add test for `x.py build --stage 0`
|
|
|
|
Uses --stage 2 for all the existing tests
|
|
From [a conversation in discord](https://discordapp.com/channels/442252698964721669/443151243398086667/719200989269327882):
> Linking seems to consume all available RAM, leading to the OS to swap memory to disk and slowing down everything in the process
Compiling itself doesn't seem to take up as much RAM, and I'm only looking to check whether a minimal testcase can be compiled by rustc, where the runtime performance isn't much of an issue
> do you have debug = true or debuginfo-level = 2 in config.toml?
> if so I think that results in over 2GB of debuginfo nowadays and is likely the culprit
> which might mean we're giving out bad advice :(
Anecdotally, this sped up my stage 1 build from 15 to 10 minutes.
This still adds line numbers, it only removes variable and type information.
- Improve wording for debuginfo description
Co-authored-by: Teymour Aldridge <42674621+teymour-aldridge@users.noreply.github.com>
|
