| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
|
|
It was barely used, and the places that used it are actually clearer
without it since they were often undoing some of its work. This also
avoids an unnecessary clone of the receiver type and removes a layer of
logical indirection in the code.
|
|
`SelfTy` makes it sound like it is literally the `Self` type, whereas in
fact it may be `&Self` or other types. Plus, I want to use the name
`SelfTy` for a new variant of `clean::Type`. Having both causes
resolution conflicts or at least confusion.
|
|
|
|
|
|
This also improves sidebar layout, so instead of
BTreeM
ap
you get this
BTree
Map
|
|
The previous commit updated `rustfmt.toml` appropriately. This commit is
the outcome of running `x fmt --all` with the new formatting options.
|
|
|
|
|
|
|
|
|
|
GuillaumeGomez:stabilize-custom_code_classes_in_docs, r=rustdoc
Stabilize `custom_code_classes_in_docs` feature
Fixes #79483.
This feature has been around for quite some time now, I think it's fine to stabilize it now.
## Summary
## What is the feature about?
In short, this PR changes two things, both related to codeblocks in doc comments in Rust documentation:
* Allow to disable generation of `language-*` CSS classes with the `custom` attribute.
* Add your own CSS classes to a code block so that you can use other tools to highlight them.
#### The `custom` attribute
Let's start with the new `custom` attribute: it will disable the generation of the `language-*` CSS class on the generated HTML code block. For example:
```rust
/// ```custom,c
/// int main(void) {
/// return 0;
/// }
/// ```
```
The generated HTML code block will not have `class="language-c"` because the `custom` attribute has been set. The `custom` attribute becomes especially useful with the other thing added by this feature: adding your own CSS classes.
#### Adding your own CSS classes
The second part of this feature is to allow users to add CSS classes themselves so that they can then add a JS library which will do it (like `highlight.js` or `prism.js`), allowing to support highlighting for other languages than Rust without increasing burden on rustdoc. To disable the automatic `language-*` CSS class generation, you need to use the `custom` attribute as well.
This allow users to write the following:
```rust
/// Some code block with `{class=language-c}` as the language string.
///
/// ```custom,{class=language-c}
/// int main(void) {
/// return 0;
/// }
/// ```
fn main() {}
```
This will notably produce the following HTML:
```html
<pre class="language-c">
int main(void) {
return 0;
}</pre>
```
Instead of:
```html
<pre class="rust rust-example-rendered">
<span class="ident">int</span> <span class="ident">main</span>(<span class="ident">void</span>) {
<span class="kw">return</span> <span class="number">0</span>;
}
</pre>
```
To be noted, we could have written `{.language-c}` to achieve the same result. `.` and `class=` have the same effect.
One last syntax point: content between parens (`(like this)`) is now considered as comment and is not taken into account at all.
In addition to this, I added an `unknown` field into `LangString` (the parsed code block "attribute") because of cases like this:
```rust
/// ```custom,class:language-c
/// main;
/// ```
pub fn foo() {}
```
Without this `unknown` field, it would generate in the DOM: `<pre class="language-class:language-c language-c">`, which is quite bad. So instead, it now stores all unknown tags into the `unknown` field and use the first one as "language". So in this case, since there is no unknown tag, it'll simply generate `<pre class="language-c">`. I added tests to cover this.
EDIT(camelid): This description is out-of-date. Using `custom,class:language-c` will generate the output `<pre class="language-class:language-c">` as would be expected; it treats `class:language-c` as just the name of a language (similar to the langstring `c` or `js` or what have you) since it does not use the designed class syntax.
Finally, I added a parser for the codeblock attributes to make it much easier to maintain. It'll be pretty easy to extend.
As to why this syntax for adding attributes was picked: it's [Pandoc's syntax](https://pandoc.org/MANUAL.html#extension-fenced_code_attributes). Even if it seems clunkier in some cases, it's extensible, and most third-party Markdown renderers are smart enough to ignore Pandoc's brace-delimited attributes (from [this comment](https://github.com/rust-lang/rust/pull/110800#issuecomment-1522044456)).
r? `@notriddle`
|
|
If a const function is unstable overall (and thus, in all circumstances
I know of, also const-unstable), we should show the option to use it as
const. You need to enable a feature to use the function at all anyway.
If the function is stabilized without also being const-stabilized, then
we do not show the const keyword and instead show "const: unstable" in
the version info.
|
|
It's confusing because if a function is unstable overall, there's no
need to highlight the constness is also unstable. Technically, these
attributes (overall stability and const-stability) are separate, but in
practice, we don't even show the const-unstable's feature flag (it's
normally the same as the overall function).
|
|
|
|
|
|
|
|
|
|
|
|
Always display stability version even if it's the same as the containing item
Fixes https://github.com/rust-lang/rust/issues/118439.
Currently, if the containing item's version is the same as the item's version (like a method), we don't display it on the item.
This was something done on purpose as you can see [here](https://github.com/rust-lang/rust/blob/e9b7bf011478aa8c19ac49afc99853a66ba04319/src/librustdoc/html/render/mod.rs#L949-L955). It was implemented in https://github.com/rust-lang/rust/pull/30686.
I think we should change this because on pages with a lot of items, if someone arrives (through the search or a link) to an item far below the page, they won't know the stability version unless they scroll to the top, which isn't great.
You can see the result [here](https://rustdoc.crud.net/imperio/display-stability-version/std/pin/struct.Pin.html#method.new).
r? `@notriddle`
|
|
rustdoc-search: single result for items with multiple paths
Part of #15723
Preview: https://notriddle.com/rustdoc-html-demo-9/reexport-dup/std/index.html?search=hashmap
This change uses the same "exact" paths as trait implementors and type alias inlining to track items with multiple reachable paths. This way, if you search for `vec`, you get only the `std` exports of it, and not the one from `alloc`.
It still includes all the items in the search index so that you can search for them by all available paths. For example, try `core::option` and `std::option`, and notice that the results page doesn't show duplicates, but still shows all the items in their respective crates.
|
|
In some cases `DUMMY_SP` is already imported. In other cases this commit
adds the necessary import, in files where `DUMMY_SP` is used more than
once.
|
|
This change uses the same "exact" paths as trait implementors
and type alias inlining to track items with multiple
reachable paths. This way, if you search for `vec`, you get
only the `std` exports of it, and not the one from `alloc`.
It still includes all the items in the search index so that
you can search for them by all available paths. For example,
try `core::option` and `std::option`, and notice that the
results page doesn't show duplicates, but still shows all
the items in their respective crates.
|
|
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
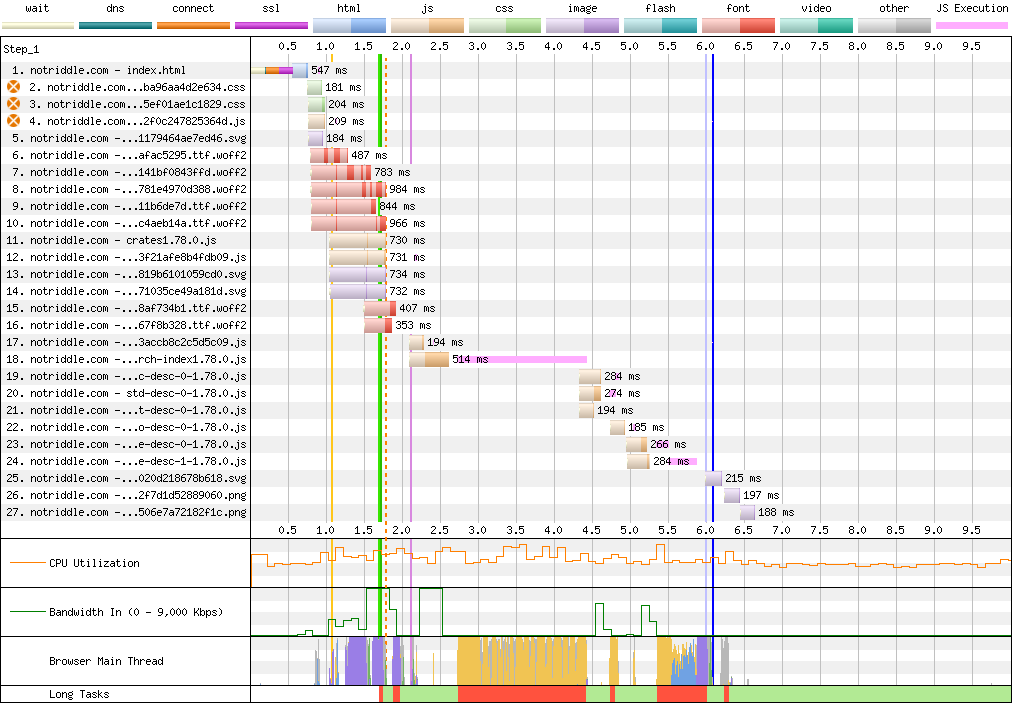
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
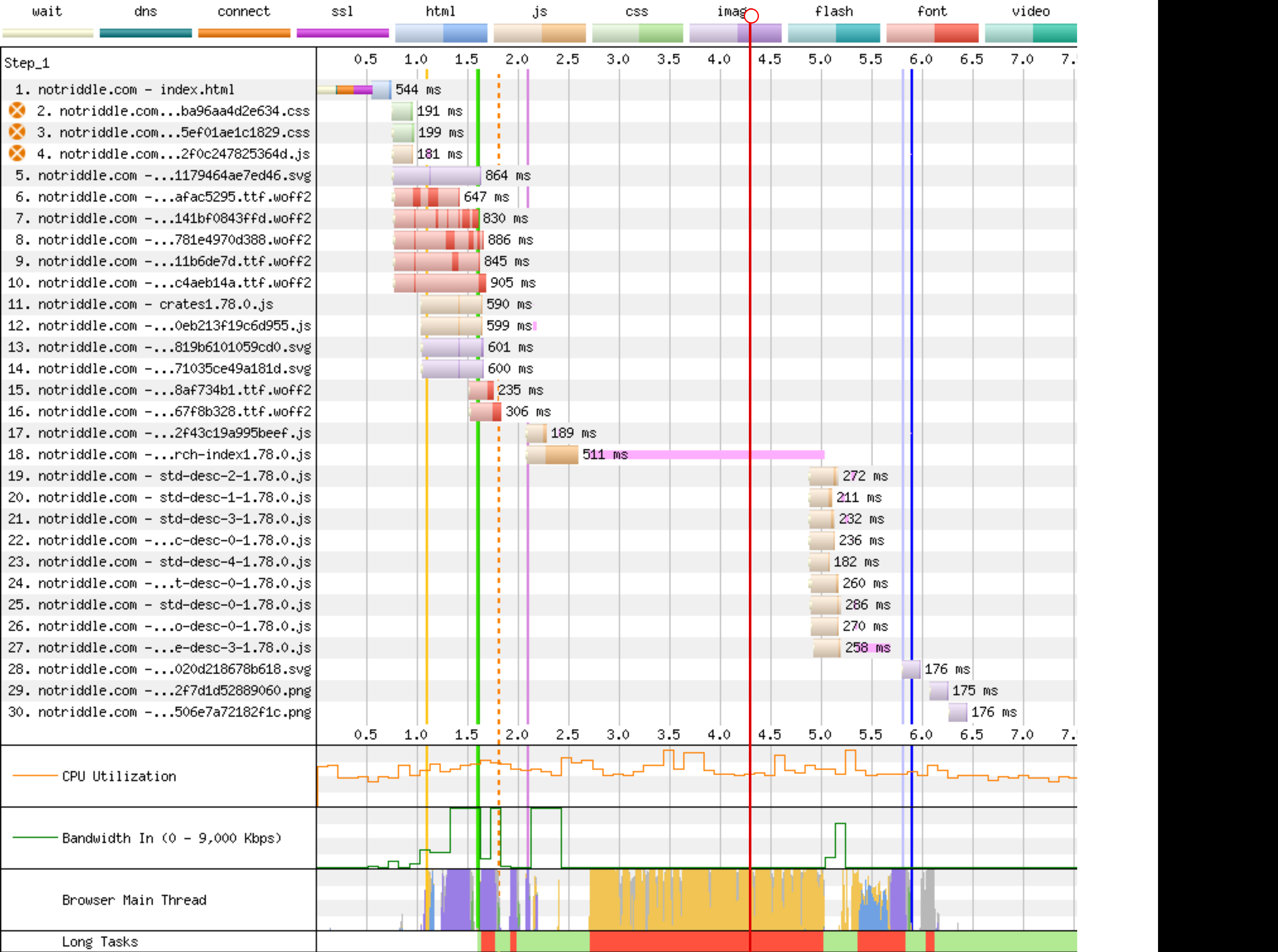
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
|
|
so it can be remapped (or not) by callers
|
|
|
|
|
|
The descriptions are, on almost all crates[^1], the majority
of the size of the search index, even though they aren't really
used for searching. This makes it relatively easy to separate
them into their own files.
This commit also bumps us to ES8. Out of the browsers we support,
all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted.
|
|
Visually mark 👻hidden👻 items with document-hidden-items
Fixes #122485
This adds a 👻 in the item list (much like the :lock: used for private items), and also shows `#[doc(hidden)]` in the code view, where `pub(crate)` etc gets shown for private items.
This does not do anything for enum variants, if people have ideas. I think we can just show the attribute.
|
|
|
|
|
|
|
|
[rustdoc] Allows links in headings
Reopening of https://github.com/rust-lang/rust/pull/94360.
# Explanations
Rustdoc currently doesn't follow the markdown spec on headings: we don't allow links in them. So instead of having headings linking to themselves, this PR generates an anchor on the left side like this:

<details>
<summary>previous version</summary>

</details>
Having the anchor always displayed allows for mobile devices users to be able to have a link to the anchor. The different color used for the anchor itself is the same as links so people notice when looking at it that they can click on it.
You can test it [here](https://rustdoc.crud.net/imperio/links-in-headings/std/index.html).
cc `@camelid`
r? `@notriddle`
|
|
|
|
|
|
Two optimizations for the function signature search:
* Instead of using JSON arrays, like `[1,20]`, it uses VLQ
hex with no commas, like `[aAd]`.
* This also adds backrefs: if you have more than one function
with exactly the same signature, it'll not only store it once,
it'll *decode* it once, and store in the typeIdMap only once.
Size change
-----------
standard library
```console
$ du -bs search-index-old.js search-index-new.js
4976370 search-index-old.js
4404391 search-index-new.js
```
((4976370-4404391)/4404391)*100% = 12.9%
Benchmarks are similarly shrunk:
```console
$ du -hs tmp/{arti,cortex-m,sqlx,stm32f4,ripgrep}/toolchain_{old,new}/doc/search-index.js
10555067 tmp/arti/toolchain_old/doc/search-index.js
8921236 tmp/arti/toolchain_new/doc/search-index.js
77018 tmp/cortex-m/toolchain_old/doc/search-index.js
66676 tmp/cortex-m/toolchain_new/doc/search-index.js
2876330 tmp/sqlx/toolchain_old/doc/search-index.js
2436812 tmp/sqlx/toolchain_new/doc/search-index.js
63632890 tmp/stm32f4/toolchain_old/doc/search-index.js
52337438 tmp/stm32f4/toolchain_new/doc/search-index.js
631150 tmp/ripgrep/toolchain_old/doc/search-index.js
541646 tmp/ripgrep/toolchain_new/doc/search-index.js
```
|
|
Also add some `dcx` methods to types that wrap `TyCtxt`, for easier
access.
|
|
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and
removing redundant imports code into two PR.
|
|
|
|
The deprecation notice is used when in crates as well. This applies to versions Rust or Crates.
Fixes #118148
Signed-off-by: Harold Dost <h.dost@criteo.com>
|
|
This is about equally readable, a lot more terse, and stops
special-casing functions and methods.
```console
$ du -hs doc-old/ doc-new/
671M doc-old/
670M doc-new/
```
|
|
There's no such thing as a big section header, so I don't know why the
name was used.
|
|
|
|
They're only used for HTML, so it makes more sense for them to live
their.
|
|
|
|
|
|
|
|
|
|
|
