| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
|
|
This change uses the same "exact" paths as trait implementors
and type alias inlining to track items with multiple
reachable paths. This way, if you search for `vec`, you get
only the `std` exports of it, and not the one from `alloc`.
It still includes all the items in the search index so that
you can search for them by all available paths. For example,
try `core::option` and `std::option`, and notice that the
results page doesn't show duplicates, but still shows all
the items in their respective crates.
|
|
|
|
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
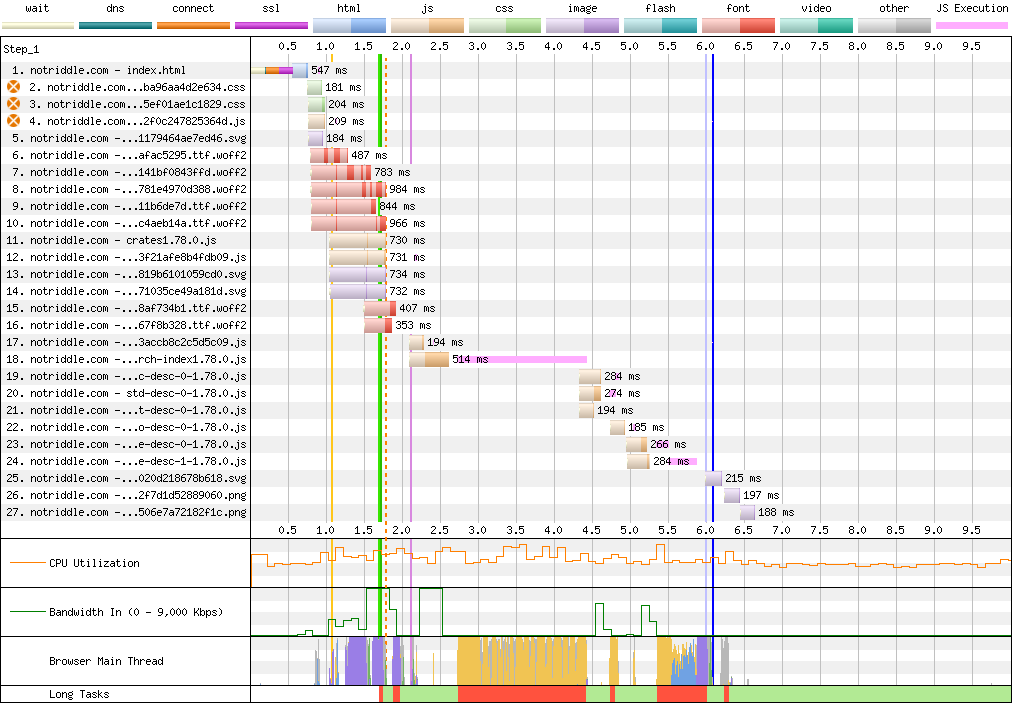
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
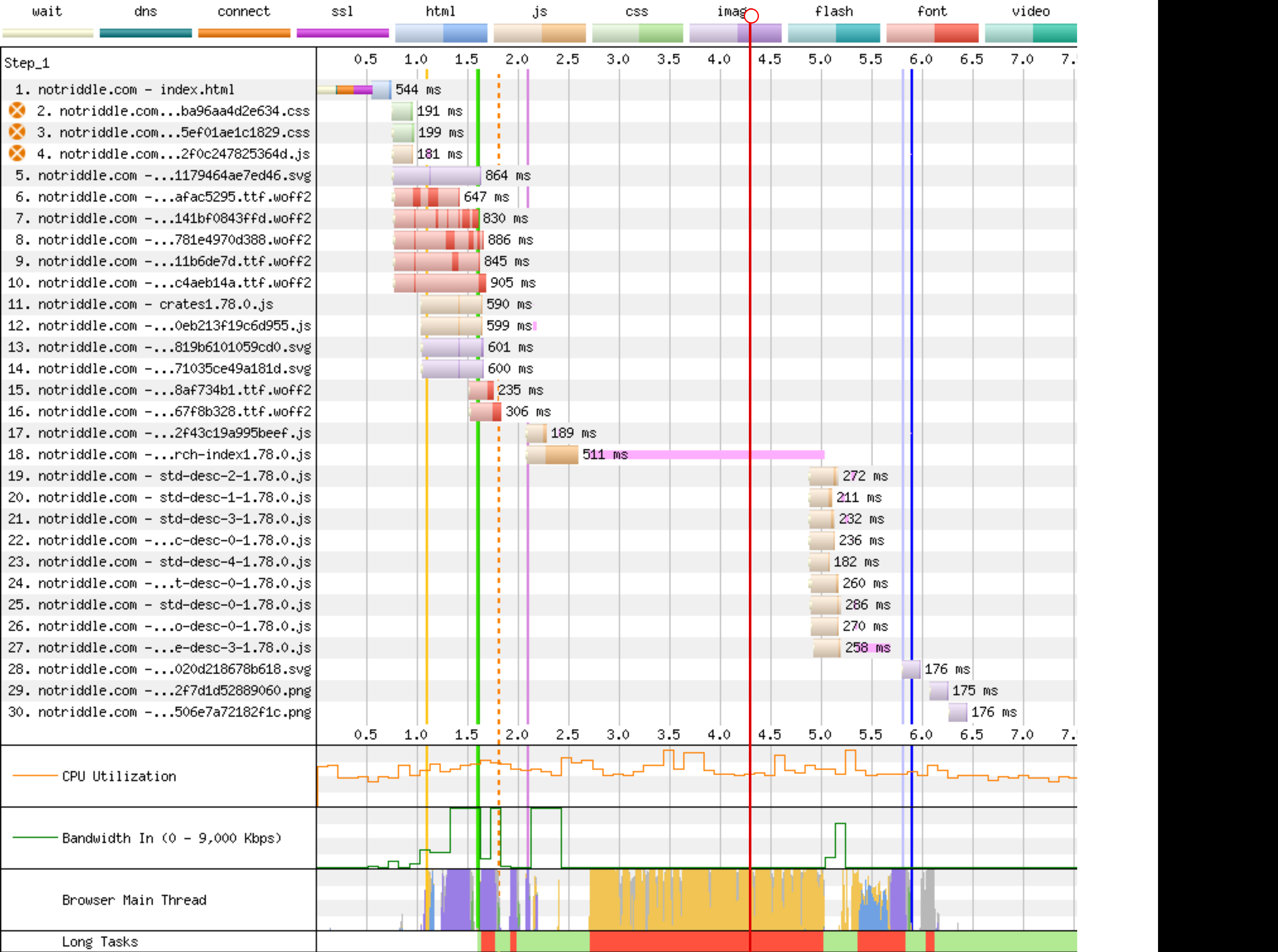
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
|
|
|
|
|
|
|
|
This adds a bit more data than "pure sharding" by
including information about which items have no description
at all. This way, it can sort the results, then truncate,
then finally download the description.
With the "e" bitmap: 2380KiB
Without the "e" bitmap: 2364KiB
|
|
The descriptions are, on almost all crates[^1], the majority
of the size of the search index, even though they aren't really
used for searching. This makes it relatively easy to separate
them into their own files.
This commit also bumps us to ES8. Out of the browsers we support,
all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted.
|
|
Option::map, for example, looks like this:
option<t>, (t -> u) -> option<u>
This syntax searches all of the HOFs in Rust: traits Fn, FnOnce,
and FnMut, and bare fn primitives.
|
|
rustdoc: search for tuples and unit by type with `()`
This feature extends rustdoc to support the syntax that most users will naturally attempt to use to search for tuples. Part of https://github.com/rust-lang/rust/issues/60485
Function signature searches already support tuples and unit. The explicit name `primitive:tuple` and `primitive:unit` can be used to match a tuple or unit, while `()` will match either one. It also follows the direction set by the actual language for parens as a group, so `(u8,)` will only match a tuple, while `(u8)` will match a plain, unwrapped byte—thanks to loose search semantics, it will also match the tuple.
## Preview
* [`option<t>, option<u> -> (t, u)`](<https://notriddle.com/rustdoc-html-demo-5/tuple-unit/std/index.html?search=option%3Ct%3E%2C option%3Cu%3E -%3E (t%2C u)>)
* [`[t] -> (t,)`](<https://notriddle.com/rustdoc-html-demo-5/tuple-unit/std/index.html?search=[t] -%3E (t%2C)>)
* [`(ipaddr,) -> socketaddr`](<https://notriddle.com/rustdoc-html-demo-5/tuple-unit/std/index.html?search=(ipaddr%2C) -%3E socketaddr>)
## Motivation
When type-based search was first landed, it was directly [described as incomplete][a comment].
[a comment]: https://github.com/rust-lang/rust/pull/23289#issuecomment-79437386
Filling out the missing functionality is going to mean adding support for more of Rust's [type expression] syntax, such as tuples (in this PR), references, raw pointers, function pointers, and closures.
[type expression]: https://doc.rust-lang.org/reference/types.html#type-expressions
There does seem to be demand for this sort of thing, such as [this Discord message](https://discord.com/channels/442252698964721669/443150878111694848/1042145740065099796) expressing regret at rustdoc not supporting tuples in search queries.
## Reference description (from the Rustdoc book)
<table>
<thead>
<tr>
<th>Shorthand</th>
<th>Explicit names</th>
</tr>
</thead>
<tbody>
<tr><td colspan="2">Before this PR</td></tr>
<tr>
<td><code>[]</code></td>
<td><code>primitive:slice</code> and/or <code>primitive:array</code></td>
</tr>
<tr>
<td><code>[T]</code></td>
<td><code>primitive:slice<T></code> and/or <code>primitive:array<T></code></td>
</tr>
<tr>
<td><code>!</code></td>
<td><code>primitive:never</code></td>
</tr>
<tr><td colspan="2">After this PR</td></tr>
<tr>
<td><code>()</code></td>
<td><code>primitive:unit</code> and/or <code>primitive:tuple</code></td>
</tr>
<tr>
<td><code>(T)</code></td>
<td><code>T</code></td>
</tr>
<tr>
<td><code>(T,)</code></td>
<td><code>primitive:tuple<T></code></td>
</tr>
</tbody>
</table>
A single type expression wrapped in parens is the same as that type expression, since parens act as the grouping operator. If they're empty, though, they will match both `unit` and `tuple`, and if there's more than one type (or a trailing or leading comma) it is the same as `primitive:tuple<...>`.
However, since items can be left out of the query, `(T)` will still return results for types that match tuples, even though it also matches the type on its own. That is, `(u32)` matches `(u32,)` for the exact same reason that it also matches `Result<u32, Error>`.
## Future direction
The [type expression grammar](https://doc.rust-lang.org/reference/types.html#type-expressions) from the Reference is given below:
<pre><code>Syntax
Type :
TypeNoBounds
| <a href="https://doc.rust-lang.org/reference/types/impl-trait.html">ImplTraitType</a>
| <a href="https://doc.rust-lang.org/reference/types/trait-object.html">TraitObjectType</a>
<br>
TypeNoBounds :
<a href="https://doc.rust-lang.org/reference/types.html#parenthesized-types">ParenthesizedType</a>
| <a href="https://doc.rust-lang.org/reference/types/impl-trait.html">ImplTraitTypeOneBound</a>
| <a href="https://doc.rust-lang.org/reference/types/trait-object.html">TraitObjectTypeOneBound</a>
| <a href="https://doc.rust-lang.org/reference/paths.html#paths-in-types">TypePath</a>
| <a href="https://doc.rust-lang.org/reference/types/tuple.html#tuple-types">TupleType</a>
| <a href="https://doc.rust-lang.org/reference/types/never.html">NeverType</a>
| <a href="https://doc.rust-lang.org/reference/types/pointer.html#raw-pointers-const-and-mut">RawPointerType</a>
| <a href="https://doc.rust-lang.org/reference/types/pointer.html#shared-references-">ReferenceType</a>
| <a href="https://doc.rust-lang.org/reference/types/array.html">ArrayType</a>
| <a href="https://doc.rust-lang.org/reference/types/slice.html">SliceType</a>
| <a href="https://doc.rust-lang.org/reference/types/inferred.html">InferredType</a>
| <a href="https://doc.rust-lang.org/reference/paths.html#qualified-paths">QualifiedPathInType</a>
| <a href="https://doc.rust-lang.org/reference/types/function-pointer.html">BareFunctionType</a>
| <a href="https://doc.rust-lang.org/reference/macros.html#macro-invocation">MacroInvocation</a>
</code></pre>
ImplTraitType and TraitObjectType (and ImplTraitTypeOneBound and TraitObjectTypeOneBound) are not yet implemented. They would mostly desugar to `trait:`, similarly to how `!` desugars to `primitive:never`.
ParenthesizedType and TuplePath are added in this PR.
TypePath is already implemented (except const generics, which is not planned, and function-like trait syntax, which is planned as part of closure support).
NeverType is already implemented.
RawPointerType and ReferenceType require parsing and fixes to the search index to store this information, but otherwise their behavior seems simple enough. Just like tuples and slices, `&T` would be equivalent to `primitive:reference<T>`, `&mut T` would be equivalent to `primitive:reference<keyword:mut, T>`, `*T` would be equivalent to `primitive:pointer<T>`, `*mut T` would be equivalent to `primitive:pointer<keyword:mut, T>`, and `*const T` would be equivalent to `primitive:pointer<keyword:const, T>`. Lifetime generics support is not planned, because lifetime subtyping seems too complicated.
ArrayType is subsumed by SliceType right now. Implementing const generics is not planned, because it seems like it would require a lot of implementation complexity for not much gain.
InferredType isn't really covered right now. Its semantics in a search context are not obvious.
QualifiedPathInType is not implemented, and it is not planned. I would need a use case to justify it, and act as a guide for what the exact semantics should be.
BareFunctionType is not implemented. Along with function-like trait syntax, which is formally considered a TypePath, it's the biggest missing feature to be able to do structured searches over generic APIs like `Option`.
MacroInvocation is not parsed (macro names are, but they don't mean the same thing here at all). Those are gone by the time Rustdoc sees the source code.
|
|
Two optimizations for the function signature search:
* Instead of using JSON arrays, like `[1,20]`, it uses VLQ
hex with no commas, like `[aAd]`.
* This also adds backrefs: if you have more than one function
with exactly the same signature, it'll not only store it once,
it'll *decode* it once, and store in the typeIdMap only once.
Size change
-----------
standard library
```console
$ du -bs search-index-old.js search-index-new.js
4976370 search-index-old.js
4404391 search-index-new.js
```
((4976370-4404391)/4404391)*100% = 12.9%
Benchmarks are similarly shrunk:
```console
$ du -hs tmp/{arti,cortex-m,sqlx,stm32f4,ripgrep}/toolchain_{old,new}/doc/search-index.js
10555067 tmp/arti/toolchain_old/doc/search-index.js
8921236 tmp/arti/toolchain_new/doc/search-index.js
77018 tmp/cortex-m/toolchain_old/doc/search-index.js
66676 tmp/cortex-m/toolchain_new/doc/search-index.js
2876330 tmp/sqlx/toolchain_old/doc/search-index.js
2436812 tmp/sqlx/toolchain_new/doc/search-index.js
63632890 tmp/stm32f4/toolchain_old/doc/search-index.js
52337438 tmp/stm32f4/toolchain_new/doc/search-index.js
631150 tmp/ripgrep/toolchain_old/doc/search-index.js
541646 tmp/ripgrep/toolchain_new/doc/search-index.js
```
|
|
|
|
|
|
|
|
|
|
Helps with #90929
This changes the search results, specifically, when there's more than
one impl with an associated item with the same name. For example,
the search queries `simd<i8> -> simd<i8>` and `simd<i64> -> simd<i64>`
don't link to the same function, but most of the functions have the
same names.
This change should probably be FCP-ed, especially since it adds a new
anchor link format for `main.js` to handle, so that URLs like
`struct.Vec.html#impl-AsMut<[T]>-for-Vec<T,+A>/method.as_mut` redirect
to `struct.Vec.html#method.as_mut-2`. It's a strange design, but there
are a few reasons for it:
* I'd like to avoid making the HTML bigger. Obviously, fixing this bug
is going to add at least a little more data to the search index, but
adding more HTML penalises viewers for the benefit of searchers.
* Breaking `struct.Vec.html#method.len` would also be a disappointment.
On the other hand:
* The path-style anchors might be less prone to link rot than the numbered
anchors. It's definitely less likely to have URLs that appear to "work",
but silently point at the wrong thing.
* This commit arranges the path-style anchor to redirect to the numbered
anchor. Nothing stops rustdoc from doing the opposite, making path-style
anchors the default and redirecting the "legacy" numbered ones.
|
|
When writing a type-driven search query in rustdoc, specifically one
with more than one query element, non-existent types become generic
parameters instead of auto-correcting (which is currently only done
for single-element queries) or giving no result. You can also force a
generic type parameter by writing `generic:T` (and can force it to not
use a generic type parameter with something like `struct:T` or whatever,
though if this happens it means the thing you're looking for doesn't
exist and will give you no results).
There is no syntax provided for specifying type constraints
for generic type parameters.
When you have a generic type parameter in a search query, it will only
match up with generic type parameters in the actual function, not
concrete types that match, not concrete types that implement a trait.
It also strictly matches based on when they're the same or different,
so `option<T>, option<U> -> option<U>` matches `Option::and`, but not
`Option::or`. Similarly, `option<T>, option<T> -> option<T>`` matches
`Option::or`, but not `Option::and`.
|
|
|
|
|
|
|
|
The default fn ret ty is always unit. Just use that.
Looking back at the time when `FnRetTy` (then called
`FunctionRetTy`) was first added to rustdoc, it seems to originally
be there because `-> !` was a special form: the never type didn't
exist back then.
https://github.com/rust-lang/rust/commit/eb01b17b06eb35542bb80ff7456043b0ed5572ba#diff-384affc1b4190940f114f3fcebbf969e7e18657a71ef9001da6b223a036687d9L921-L924
|
|
|
|
This indexes them as primitives with generics, so `slice<u32>` is
how you search for `[u32]`, and `array<u32>` for `[u32; 1]`.
A future commit will desugar the square bracket syntax to search
both arrays and slices at once.
|
|
|
|
rustdoc: fix type search for `Option` combinators
|
|
rustdoc: sort deprecated items lower in search
closes #98759
### Screenshots
`i32::MAX` show sup above `std::i32::MAX` and `core::i32::MAX`

If just searching for `min`, the deprecated results show up far below other things:

one page later

~~And, as you can see, the "Deprecation planned" message shows up in the search results. The same is true for fully-deprecated items like `mem::uninitialized`:
~~
Edit: the deprecation message change was removed from this PR. Only the sorting is changed.
|
|
serialize `q` (`itemPaths`) sparsely
overall 4% reduction in search index size
|
|
|
|
|
|
|
|
$ wc -c search-index.old.js search-index.new.js
3940530 search-index.old.js
3843222 search-index.new.js
((3940530-3843222)/3940530)*100 = 2.47%
$ wc -c search-index.old.js.gz search-index.new.js.gz
380251 search-index.old.js.gz
379434 search-index.new.js.gz
((380251-379434)/380251)*100 = 0.214%
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
This reduces the size of the function signature index, because
it's common to have many functions that operate on the same types.
$ wc -c search-index-old.js search-index-new.js
5224374 search-index-old.js
3932314 search-index-new.js
By my math, this reduces the uncompressed size of the search index by 32%.
On compressed signatures, the wins are less drastic, a mere 8%:
$ wc -c search-index-old.js.gz search-index-new.js.gz
404532 search-index-old.js.gz
371635 search-index-new.js.gz
|
|
Co-authored-by: Noah Lev <camelidcamel@gmail.com>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
