| Age | Commit message (Collapse) | Author | Lines |
|---|
|
Always display stability version even if it's the same as the containing item
Fixes https://github.com/rust-lang/rust/issues/118439.
Currently, if the containing item's version is the same as the item's version (like a method), we don't display it on the item.
This was something done on purpose as you can see [here](https://github.com/rust-lang/rust/blob/e9b7bf011478aa8c19ac49afc99853a66ba04319/src/librustdoc/html/render/mod.rs#L949-L955). It was implemented in https://github.com/rust-lang/rust/pull/30686.
I think we should change this because on pages with a lot of items, if someone arrives (through the search or a link) to an item far below the page, they won't know the stability version unless they scroll to the top, which isn't great.
You can see the result [here](https://rustdoc.crud.net/imperio/display-stability-version/std/pin/struct.Pin.html#method.new).
r? `@notriddle`
|
|
rustdoc-search: single result for items with multiple paths
Part of #15723
Preview: https://notriddle.com/rustdoc-html-demo-9/reexport-dup/std/index.html?search=hashmap
This change uses the same "exact" paths as trait implementors and type alias inlining to track items with multiple reachable paths. This way, if you search for `vec`, you get only the `std` exports of it, and not the one from `alloc`.
It still includes all the items in the search index so that you can search for them by all available paths. For example, try `core::option` and `std::option`, and notice that the results page doesn't show duplicates, but still shows all the items in their respective crates.
|
|
Simplify `static_assert_size`s.
We want to run them on all 64-bit platforms.
r? `@ghost`
|
|
We want to run them on all 64-bit platforms.
|
|
Because that's the way it should be done.
|
|
In some cases `DUMMY_SP` is already imported. In other cases this commit
adds the necessary import, in files where `DUMMY_SP` is used more than
once.
|
|
This cuts the HTML overhead for a page by about 1KiB,
significantly reducing the overall size of the docs bundle.
|
|
|
|
|
|
|
|
This change uses the same "exact" paths as trait implementors
and type alias inlining to track items with multiple
reachable paths. This way, if you search for `vec`, you get
only the `std` exports of it, and not the one from `alloc`.
It still includes all the items in the search index so that
you can search for them by all available paths. For example,
try `core::option` and `std::option`, and notice that the
results page doesn't show duplicates, but still shows all
the items in their respective crates.
|
|
|
|
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
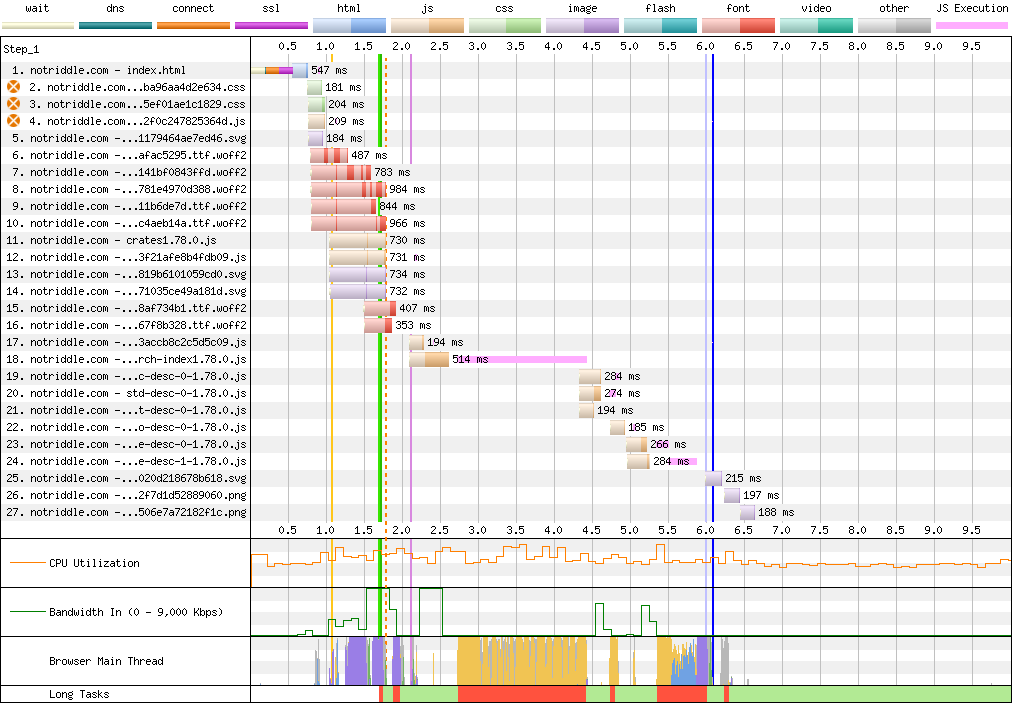
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
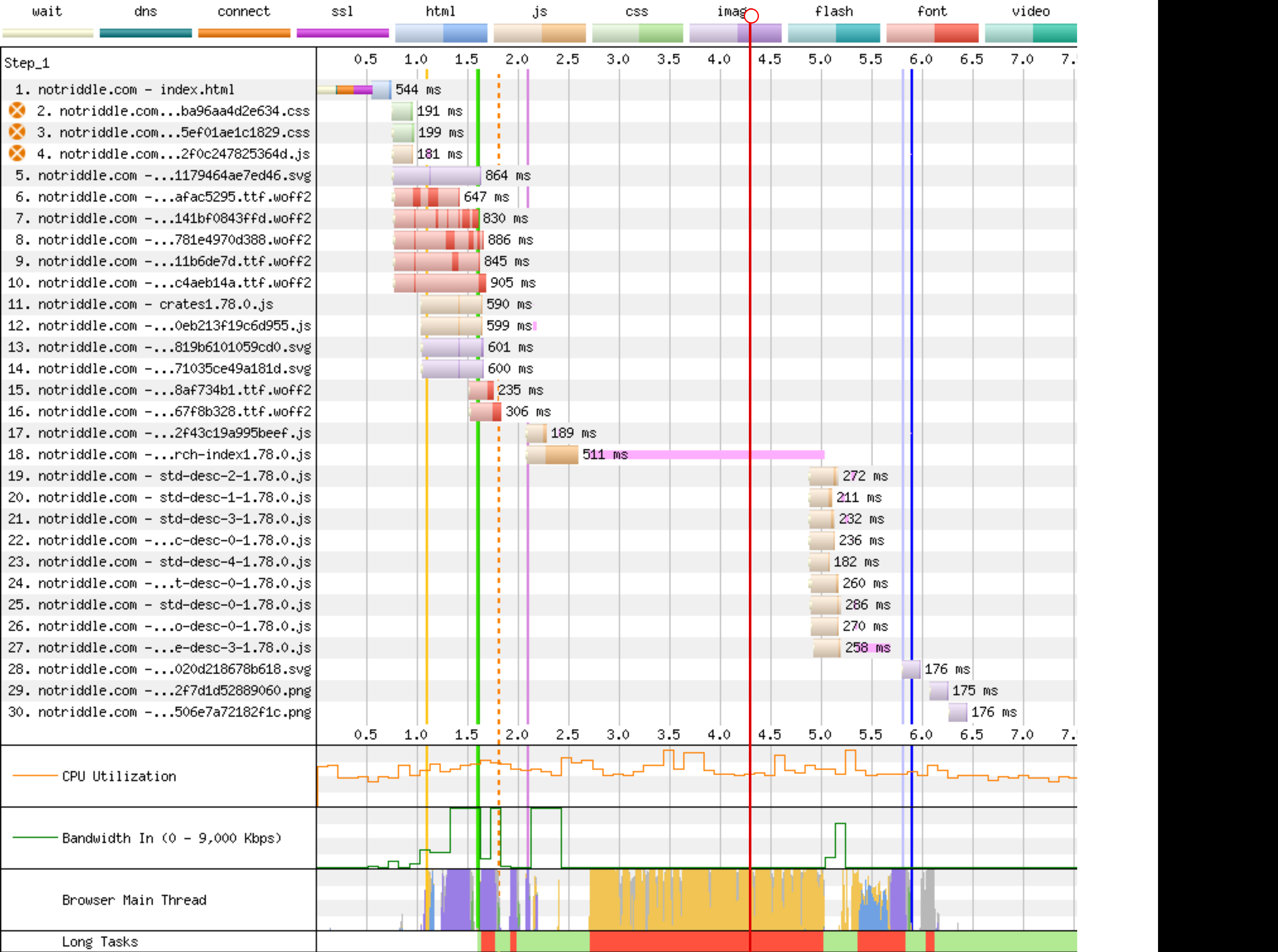
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
|
|
Co-authored-by: Guillaume Gomez <guillaume1.gomez@gmail.com>
|
|
so it can be remapped (or not) by callers
|
|
|
|
|
|
Previously, the documentation for a variant appeared after the documentation
for each of its fields. This was inconsistent with structs and unions, and made
little sense on its own; fields are subordinate to variants and should
therefore appear later in the documentation.
|
|
|
|
This adds a bit more data than "pure sharding" by
including information about which items have no description
at all. This way, it can sort the results, then truncate,
then finally download the description.
With the "e" bitmap: 2380KiB
Without the "e" bitmap: 2364KiB
|
|
|
|
The descriptions are, on almost all crates[^1], the majority
of the size of the search index, even though they aren't really
used for searching. This makes it relatively easy to separate
them into their own files.
This commit also bumps us to ES8. Out of the browsers we support,
all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted.
|
|
Visually mark 👻hidden👻 items with document-hidden-items
Fixes #122485
This adds a 👻 in the item list (much like the :lock: used for private items), and also shows `#[doc(hidden)]` in the code view, where `pub(crate)` etc gets shown for private items.
This does not do anything for enum variants, if people have ideas. I think we can just show the attribute.
|
|
less symbol interner locks
This reduces instructions under 1% (in rustdoc run), but essentially free.
|
|
|
|
|
|
|
|
|
|
|
|
Option::map, for example, looks like this:
option<t>, (t -> u) -> option<u>
This syntax searches all of the HOFs in Rust: traits Fn, FnOnce,
and FnMut, and bare fn primitives.
|
|
|
|
|
|
serialization order
|
|
[rustdoc] Allows links in headings
Reopening of https://github.com/rust-lang/rust/pull/94360.
# Explanations
Rustdoc currently doesn't follow the markdown spec on headings: we don't allow links in them. So instead of having headings linking to themselves, this PR generates an anchor on the left side like this:

<details>
<summary>previous version</summary>

</details>
Having the anchor always displayed allows for mobile devices users to be able to have a link to the anchor. The different color used for the anchor itself is the same as links so people notice when looking at it that they can click on it.
You can test it [here](https://rustdoc.crud.net/imperio/links-in-headings/std/index.html).
cc `@camelid`
r? `@notriddle`
|
|
- `struct_foo` + `emit` -> `foo`
- `create_foo` + `emit` -> `emit_foo`
I have made recent commits in other PRs that have removed some of these
shortcuts for combinations with few uses, e.g.
`struct_span_err_with_code`. But for the remaining combinations that
have high levels of use, we might as well use them wherever possible.
|
|
|
|
rustdoc: search for tuples and unit by type with `()`
This feature extends rustdoc to support the syntax that most users will naturally attempt to use to search for tuples. Part of https://github.com/rust-lang/rust/issues/60485
Function signature searches already support tuples and unit. The explicit name `primitive:tuple` and `primitive:unit` can be used to match a tuple or unit, while `()` will match either one. It also follows the direction set by the actual language for parens as a group, so `(u8,)` will only match a tuple, while `(u8)` will match a plain, unwrapped byte—thanks to loose search semantics, it will also match the tuple.
## Preview
* [`option<t>, option<u> -> (t, u)`](<https://notriddle.com/rustdoc-html-demo-5/tuple-unit/std/index.html?search=option%3Ct%3E%2C option%3Cu%3E -%3E (t%2C u)>)
* [`[t] -> (t,)`](<https://notriddle.com/rustdoc-html-demo-5/tuple-unit/std/index.html?search=[t] -%3E (t%2C)>)
* [`(ipaddr,) -> socketaddr`](<https://notriddle.com/rustdoc-html-demo-5/tuple-unit/std/index.html?search=(ipaddr%2C) -%3E socketaddr>)
## Motivation
When type-based search was first landed, it was directly [described as incomplete][a comment].
[a comment]: https://github.com/rust-lang/rust/pull/23289#issuecomment-79437386
Filling out the missing functionality is going to mean adding support for more of Rust's [type expression] syntax, such as tuples (in this PR), references, raw pointers, function pointers, and closures.
[type expression]: https://doc.rust-lang.org/reference/types.html#type-expressions
There does seem to be demand for this sort of thing, such as [this Discord message](https://discord.com/channels/442252698964721669/443150878111694848/1042145740065099796) expressing regret at rustdoc not supporting tuples in search queries.
## Reference description (from the Rustdoc book)
<table>
<thead>
<tr>
<th>Shorthand</th>
<th>Explicit names</th>
</tr>
</thead>
<tbody>
<tr><td colspan="2">Before this PR</td></tr>
<tr>
<td><code>[]</code></td>
<td><code>primitive:slice</code> and/or <code>primitive:array</code></td>
</tr>
<tr>
<td><code>[T]</code></td>
<td><code>primitive:slice<T></code> and/or <code>primitive:array<T></code></td>
</tr>
<tr>
<td><code>!</code></td>
<td><code>primitive:never</code></td>
</tr>
<tr><td colspan="2">After this PR</td></tr>
<tr>
<td><code>()</code></td>
<td><code>primitive:unit</code> and/or <code>primitive:tuple</code></td>
</tr>
<tr>
<td><code>(T)</code></td>
<td><code>T</code></td>
</tr>
<tr>
<td><code>(T,)</code></td>
<td><code>primitive:tuple<T></code></td>
</tr>
</tbody>
</table>
A single type expression wrapped in parens is the same as that type expression, since parens act as the grouping operator. If they're empty, though, they will match both `unit` and `tuple`, and if there's more than one type (or a trailing or leading comma) it is the same as `primitive:tuple<...>`.
However, since items can be left out of the query, `(T)` will still return results for types that match tuples, even though it also matches the type on its own. That is, `(u32)` matches `(u32,)` for the exact same reason that it also matches `Result<u32, Error>`.
## Future direction
The [type expression grammar](https://doc.rust-lang.org/reference/types.html#type-expressions) from the Reference is given below:
<pre><code>Syntax
Type :
TypeNoBounds
| <a href="https://doc.rust-lang.org/reference/types/impl-trait.html">ImplTraitType</a>
| <a href="https://doc.rust-lang.org/reference/types/trait-object.html">TraitObjectType</a>
<br>
TypeNoBounds :
<a href="https://doc.rust-lang.org/reference/types.html#parenthesized-types">ParenthesizedType</a>
| <a href="https://doc.rust-lang.org/reference/types/impl-trait.html">ImplTraitTypeOneBound</a>
| <a href="https://doc.rust-lang.org/reference/types/trait-object.html">TraitObjectTypeOneBound</a>
| <a href="https://doc.rust-lang.org/reference/paths.html#paths-in-types">TypePath</a>
| <a href="https://doc.rust-lang.org/reference/types/tuple.html#tuple-types">TupleType</a>
| <a href="https://doc.rust-lang.org/reference/types/never.html">NeverType</a>
| <a href="https://doc.rust-lang.org/reference/types/pointer.html#raw-pointers-const-and-mut">RawPointerType</a>
| <a href="https://doc.rust-lang.org/reference/types/pointer.html#shared-references-">ReferenceType</a>
| <a href="https://doc.rust-lang.org/reference/types/array.html">ArrayType</a>
| <a href="https://doc.rust-lang.org/reference/types/slice.html">SliceType</a>
| <a href="https://doc.rust-lang.org/reference/types/inferred.html">InferredType</a>
| <a href="https://doc.rust-lang.org/reference/paths.html#qualified-paths">QualifiedPathInType</a>
| <a href="https://doc.rust-lang.org/reference/types/function-pointer.html">BareFunctionType</a>
| <a href="https://doc.rust-lang.org/reference/macros.html#macro-invocation">MacroInvocation</a>
</code></pre>
ImplTraitType and TraitObjectType (and ImplTraitTypeOneBound and TraitObjectTypeOneBound) are not yet implemented. They would mostly desugar to `trait:`, similarly to how `!` desugars to `primitive:never`.
ParenthesizedType and TuplePath are added in this PR.
TypePath is already implemented (except const generics, which is not planned, and function-like trait syntax, which is planned as part of closure support).
NeverType is already implemented.
RawPointerType and ReferenceType require parsing and fixes to the search index to store this information, but otherwise their behavior seems simple enough. Just like tuples and slices, `&T` would be equivalent to `primitive:reference<T>`, `&mut T` would be equivalent to `primitive:reference<keyword:mut, T>`, `*T` would be equivalent to `primitive:pointer<T>`, `*mut T` would be equivalent to `primitive:pointer<keyword:mut, T>`, and `*const T` would be equivalent to `primitive:pointer<keyword:const, T>`. Lifetime generics support is not planned, because lifetime subtyping seems too complicated.
ArrayType is subsumed by SliceType right now. Implementing const generics is not planned, because it seems like it would require a lot of implementation complexity for not much gain.
InferredType isn't really covered right now. Its semantics in a search context are not obvious.
QualifiedPathInType is not implemented, and it is not planned. I would need a use case to justify it, and act as a guide for what the exact semantics should be.
BareFunctionType is not implemented. Along with function-like trait syntax, which is formally considered a TypePath, it's the biggest missing feature to be able to do structured searches over generic APIs like `Option`.
MacroInvocation is not parsed (macro names are, but they don't mean the same thing here at all). Those are gone by the time Rustdoc sees the source code.
|
|
rustdoc-search: tighter encoding for f index
Depends on https://github.com/rust-lang/rust/pull/119457
Two optimizations for the function signature search:
* Instead of using JSON arrays, like `[1,20]`, it uses VLQ
hex with no commas, like `[aAd]`.
* This also adds backrefs: if you have more than one function
with exactly the same signature, it'll not only store it once,
it'll *decode* it once, and store in the typeIdMap only once.
Based partially on discussions on zulip:
https://rust-lang.zulipchat.com/#narrow/stream/266220-t-rustdoc/topic/search.20index.20size
Performance
-----------
https://notriddle.com/rustdoc-html-demo-8/compression-perf-v2/index.html
### memory/time profiler output (for more details, consult the above link)
<table>
<thead><tr><th>benchmark<th>before<th>after</tr></thead>
<tbody>
<tr><th>arti<td>
```
user: 002.789 s
sys: 000.390 s
wall: 002.096 s
child_RSS_high: 440796 KiB
group_mem_high: 414924 KiB
```
</td><td>
```
user: 002.295 s
sys: 000.278 s
wall: 001.738 s
child_RSS_high: 314588 KiB
group_mem_high: 285220 KiB
```
</td></tr><tr><th>cortex-m<td>
```
user: 000.127 s
sys: 000.030 s
wall: 000.134 s
child_RSS_high: 60264 KiB
group_mem_high: 23824 KiB
```
</td><td>
```
user: 000.136 s
sys: 000.038 s
wall: 000.137 s
child_RSS_high: 59204 KiB
group_mem_high: 22712 KiB
```
</td></tr><tr><th>sqlx<td>
```
user: 000.887 s
sys: 000.118 s
wall: 000.592 s
child_RSS_high: 190408 KiB
group_mem_high: 157804 KiB
```
</td><td>
```
user: 000.798 s
sys: 000.101 s
wall: 000.525 s
child_RSS_high: 159292 KiB
group_mem_high: 126292 KiB
```
</td></tr><tr><th>stm32f4<td>
```
user: 013.884 s
sys: 005.399 s
wall: 013.149 s
child_RSS_high: 1942244 KiB
group_mem_high: 1954916 KiB
```
</td><td>
```
user: 006.128 s
sys: 003.297 s
wall: 007.994 s
child_RSS_high: 1038108 KiB
group_mem_high: 1023900 KiB
```
</td></tr><tr><th>ripgrep<td>
```
user: 000.441 s
sys: 000.063 s
wall: 000.264 s
child_RSS_high: 109180 KiB
group_mem_high: 74272 KiB
```
</td><td>
```
user: 000.408 s
sys: 000.044 s
wall: 000.238 s
child_RSS_high: 101488 KiB
group_mem_high: 66000 KiB
```
</td></tr></tbody></table>
Size change
-----------
standard library without gzip:
```console
$ du -bs search-index-old.js search-index-new.js
4976370 search-index-old.js
4404391 search-index-new.js
```
((4976370-4404391)/4404391)*100% = 12.9%
with gzip:
```console
$ du -hs search-index-old.js.gz search-index-new.js.gz
520K search-index-old.js.gz
504K search-index-new.js.gz
$ du -bs search-index-old.js.gz search-index-new.js.gz
522092 search-index-old.js.gz
507654 search-index-new.js.gz
```
((522092-507654)/507654)*100% = 2.8%
Benchmarks are similarly shrunk.
Without gzip:
```console
$ du -hs tmp/{arti,cortex-m,sqlx,stm32f4,ripgrep}/toolchain_{old,new}/doc/search-index.js
10555067 tmp/arti/toolchain_old/doc/search-index.js
8921236 tmp/arti/toolchain_new/doc/search-index.js
77018 tmp/cortex-m/toolchain_old/doc/search-index.js
66676 tmp/cortex-m/toolchain_new/doc/search-index.js
2876330 tmp/sqlx/toolchain_old/doc/search-index.js
2436812 tmp/sqlx/toolchain_new/doc/search-index.js
63632890 tmp/stm32f4/toolchain_old/doc/search-index.js
52337438 tmp/stm32f4/toolchain_new/doc/search-index.js
631150 tmp/ripgrep/toolchain_old/doc/search-index.js
541646 tmp/ripgrep/toolchain_new/doc/search-index.js
```
With gzip:
```console
$ du -bs tmp/{arti,cortex-m,sqlx,stm32f4,ripgrep}/toolchain_{old,new}/doc/search-index.js.gz
1618852 tmp/arti/toolchain_old/doc/search-index.js.gz
1582007 tmp/arti/toolchain_new/doc/search-index.js.gz
16109 tmp/cortex-m/toolchain_old/doc/search-index.js.gz
15831 tmp/cortex-m/toolchain_new/doc/search-index.js.gz
422257 tmp/sqlx/toolchain_old/doc/search-index.js.gz
411507 tmp/sqlx/toolchain_new/doc/search-index.js.gz
4454761 tmp/stm32f4/toolchain_old/doc/search-index.js.gz
4334924 tmp/stm32f4/toolchain_new/doc/search-index.js.gz
98312 tmp/ripgrep/toolchain_old/doc/search-index.js.gz
96864 tmp/ripgrep/toolchain_new/doc/search-index.js.gz
$ du -hs tmp/{arti,cortex-m,sqlx,stm32f4,ripgrep}/toolchain_{old,new}/doc/search-index.j
s.gz
1.6M tmp/arti/toolchain_old/doc/search-index.js.gz
1.6M tmp/arti/toolchain_new/doc/search-index.js.gz
24K tmp/cortex-m/toolchain_old/doc/search-index.js.gz
24K tmp/cortex-m/toolchain_new/doc/search-index.js.gz
424K tmp/sqlx/toolchain_old/doc/search-index.js.gz
412K tmp/sqlx/toolchain_new/doc/search-index.js.gz
4.3M tmp/stm32f4/toolchain_old/doc/search-index.js.gz
4.2M tmp/stm32f4/toolchain_new/doc/search-index.js.gz
108K tmp/ripgrep/toolchain_old/doc/search-index.js.gz
104K tmp/ripgrep/toolchain_new/doc/search-index.js.gz
```
|
|
|
|
[rustdoc] Fix invalid handling for static method calls in jump to definition feature
I realized when working on a clippy lint that static method calls on `Self` could not give me the method `Res`. For that, we need to use `typeck` and so that's what I did in here.
It fixes the linking to static method calls.
r? ````@notriddle````
|
|
|
|
|
|
Two optimizations for the function signature search:
* Instead of using JSON arrays, like `[1,20]`, it uses VLQ
hex with no commas, like `[aAd]`.
* This also adds backrefs: if you have more than one function
with exactly the same signature, it'll not only store it once,
it'll *decode* it once, and store in the typeIdMap only once.
Size change
-----------
standard library
```console
$ du -bs search-index-old.js search-index-new.js
4976370 search-index-old.js
4404391 search-index-new.js
```
((4976370-4404391)/4404391)*100% = 12.9%
Benchmarks are similarly shrunk:
```console
$ du -hs tmp/{arti,cortex-m,sqlx,stm32f4,ripgrep}/toolchain_{old,new}/doc/search-index.js
10555067 tmp/arti/toolchain_old/doc/search-index.js
8921236 tmp/arti/toolchain_new/doc/search-index.js
77018 tmp/cortex-m/toolchain_old/doc/search-index.js
66676 tmp/cortex-m/toolchain_new/doc/search-index.js
2876330 tmp/sqlx/toolchain_old/doc/search-index.js
2436812 tmp/sqlx/toolchain_new/doc/search-index.js
63632890 tmp/stm32f4/toolchain_old/doc/search-index.js
52337438 tmp/stm32f4/toolchain_new/doc/search-index.js
631150 tmp/ripgrep/toolchain_old/doc/search-index.js
541646 tmp/ripgrep/toolchain_new/doc/search-index.js
```
|
|
|
|
Also add some `dcx` methods to types that wrap `TyCtxt`, for easier
access.
|
|
|
|
Rollup of 4 pull requests
Successful merges:
- #113091 (Don't merge cfg and doc(cfg) attributes for re-exports)
- #115660 (rustdoc: allow resizing the sidebar / hiding the top bar)
- #118863 (rustc_mir_build: Enforce `rustc::potential_query_instability` lint)
- #118909 (Some cleanup and improvement for invalid ref casting impl)
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
Don't merge cfg and doc(cfg) attributes for re-exports
Fixes #112881.
## Explanations
When re-exporting things with different `cfg`s there are two things that can happen:
* The re-export uses a subset of `cfg`s, this subset is sufficient so that the item will appear exactly with the subset
* The re-export uses a non-subset of `cfg`s (e.g. like the example I posted just above where the re-export is ungated), if the non-subset `cfg`s are active (e.g. compiling that example on windows) then this will be a compile error as the item doesn't exist to re-export, if the subset `cfg`s are active it behaves like 1.
### Glob re-exports?
**This only applies to non-glob inlined re-exports.** For glob re-exports the item may or may not exist to be re-exported (potentially the `cfg`s on the path up until the glob can be removed, and only `cfg`s on the globbed item itself matter), for non-inlined re-exports see https://github.com/rust-lang/rust/issues/85043.
cc `@Nemo157`
r? `@notriddle`
|
|
`var` declare it in the global scope, and `const` does not.
It needs to be declared in global scope.
|
|
|
