| Age | Commit message (Collapse) | Author | Lines |
|---|
|
Make Stdio handle UnwindSafe
Closes #51863
This is my first compiler PR. Thanks Niko for the mentor help!
r? @nikomatsakis
|
|
Implement always-fallible TryFrom for usize/isize conversions that are infallible on some platforms
This reverts commit 837d6c70233715a0ae8e15c703d40e3046a2f36a "Remove TryFrom impls that might become conditionally-infallible with a portability lint".
This fixes #49415 by adding (restoring) missing `TryFrom` impls for integer conversions to or from `usize` or `isize`, by making them always fallible at the type system level (that is, with `Error=TryFromIntError`) even though they happen to be infallible on some platforms (for some values of `size_of::<usize>()`).
They had been removed to allow the possibility to conditionally having some of them be infallible `From` impls instead, depending on the platforms, and have the [portability lint](https://github.com/rust-lang/rfcs/pull/1868) warn when they are used in code that is not already opting into non-portability. For example `#[allow(some_lint)] usize::from(x: u64)` would be valid on code that only targets 64-bit platforms.
This PR gives up on this possiblity for two reasons:
* Based on discussion with @aturon, it seems that the portability lint is not happening any time soon. It’s better to have the conversions be available *at all* than keep blocking them for so long. Portability-lint-gated platform-specific APIs can always be added separately later.
* For code that is fine with fallibility, the alternative would force it to opt into "non-portability" even though there would be no real portability issue.
|
|
|
|
|
|
Signed-off-by: NODA, Kai <nodakai@gmail.com>
|
|
a portability lint"
This reverts commit 837d6c70233715a0ae8e15c703d40e3046a2f36a.
Fixes https://github.com/rust-lang/rust/issues/49415
|
|
Per FCP:
* https://github.com/rust-lang/rust/issues/27802#issuecomment-377537778
* https://github.com/rust-lang/rust/issues/33906#issuecomment-377534308
|
|
Fixes #42781
|
|
Add some performance guidance to std::fs and std::io docs
Adds more documentation about performance to various "read" functions in `fs` and `io`, and to `BufReader`/`BufWriter`, with the goal of helping developers choose the best option for a given task.
|
|
|
|
|
|
|
|
r=GuillaumeGomez
Remove hidden `foo` functions from doc examples; use `Termination` trait.
Fixes https://github.com/rust-lang/rust/issues/49233.
Easier to review with the white-space ignoring `?w=1` feature: https://github.com/rust-lang/rust/pull/49357/files?w=1
|
|
Fixes https://github.com/rust-lang/rust/issues/49233.
|
|
portability lint
https://github.com/rust-lang/rust/pull/49305#issuecomment-376293243
|
|
This subsumes the need for an explicit is_empty function, and provides
access to the buffered data itself which has been requested from time to
time.
|
|
|
|
|
|
|
|
|
|
fix more typos found by codespell.
|
|
|
|
Remove "empty buffer" doc in read_until
This appears copied from fill_buf, but the above paragraph already indicates that a lack of delimiter at the end is EOF.
|
|
This appears copied from fill_buf, but the above paragraph already indicates that a lack of delimiter at the end is EOF.
|
|
|
|
On MIPS, error number 98 is not EADDRINUSE (it is EPROTOTYPE). To fix the
resulting test failure this causes, use a more portable error number in
the example documentation. EINVAL shold be more reliable because it was
defined in the original Unix as 22 so hopefully most derivatives have
defined it the same way.
|
|
fix off-by-one error
Fixes https://github.com/rust-lang/rust/issues/47325.
|
|
Better Debug impl for io::Error.
This PR includes the below changes:
1. The former impl wrapped the entire thing in `Error { repr: ... }` which was unhelpful; this has been removed.
2. The `Os` variant of `io::Error` included the code and message, but not the kind; this has been fixed.
3. The `Custom` variant of `io::Error` included a `Custom(Custom { ... })`, which is now just `Custom { ... }`.
Example of previous impl:
```rust
Error {
repr: Custom(
Custom {
kind: InvalidData,
error: Error {
repr: Os {
code: 2,
message: "no such file or directory"
}
}
}
)
}
```
Example of new impl:
```rust
Custom {
kind: InvalidData,
error: Os {
code: 2,
kind: NotFound,
message: "no such file or directory"
}
}
```
|
|
BufRead: Only flush the internal buffer if seeking outside of it.
Fixes #31100
r? @dtolnay
|
|
|
|
|
|
|
|
|
|
Implement `Write` for `Cursor<&mut Vec<T>>`
Fixes #30132
r? @dtolnay (I'm just going through `feature-accepted` issues I swear 😛)
|
|
|
|
|
|
Fixes https://github.com/rust-lang/rust/issues/42468.
|
|
docs: do not call integer overflows as underflows
In the API docs, integer overflow is sometimes called underflow. Underflow is really when the magnitude of a floating-point number is too small so the number underflows to subnormal or zero. With integers it is always overflow, even if the expected result is less than the minimum number that can be represented.
|
|
|
|
|
|
|
|
|
|
The read_exact implementation for &[u8] is optimized and usually allows LLVM to reduce a read_exact call for small numbers of bytes to a bounds check and a register load instead of a generic memcpy. On a workload I have that decompresses, deserializes (via bincode), and processes some data, this leads to a 40% speedup by essentially eliminating the deserialization overhead entirely.
|
|
Remove invalid doc link
r? @rust-lang/docs
|
|
|
|
Optimize `read_to_end`.
This patch makes `read_to_end` use Vec's memory-growth pattern rather
than using a custom pattern.
This has some interesting effects:
- If memory is reserved up front, `read_to_end` can be faster, as it
starts reading at the buffer size, rather than always starting at 32
bytes. This speeds up file reading by 2x in one of my use cases.
- It can reduce the number of syscalls when reading large files.
Previously, `read_to_end` would settle into a sequence of 8192-byte
reads. With this patch, the read size follows Vec's allocation
pattern. For example, on a 16MiB file, it can do 21 read syscalls
instead of 2057. In simple benchmarks of large files though, overall
speed is still dominated by the actual I/O.
- A downside is that Read implementations that don't implement
`initializer()` may see increased memory zeroing overhead.
I benchmarked this on a variety of data sizes, with and without
preallocated buffers. Most benchmarks see no difference, but reading
a small/medium file with a pre-allocated buffer is faster.
|
|
r=GuillaumeGomez,QuietMisdreavus
show in docs whether the return type of a function impls Iterator/Read/Write
Closes #25928
This PR makes it so that when rustdoc documents a function, it checks the return type to see whether it implements a handful of specific traits. If so, it will print the impl and any associated types. Rather than doing this via a whitelist within rustdoc, i chose to do this by a new `#[doc]` attribute parameter, so things like `Future` could tap into this if desired.
### Known shortcomings
~~The printing of impls currently uses the `where` class over the whole thing to shrink the font size relative to the function definition itself. Naturally, when the impl has a where clause of its own, it gets shrunken even further:~~ (This is no longer a problem because the design changed and rendered this concern moot.)
The lookup currently just looks at the top-level type, not looking inside things like Result or Option, which renders the spotlights on Read/Write a little less useful:
<details><summary>`File::{open, create}` don't have spotlight info (pic of old design)</summary>
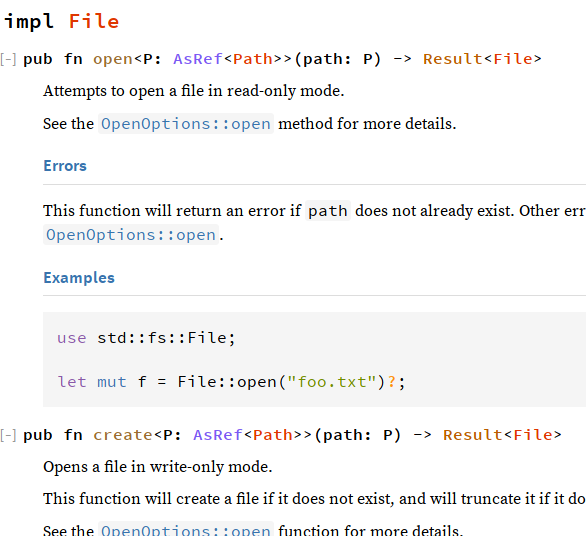
</details>
All three of the initially spotlighted traits are generically implemented on `&mut` references. Rustdoc currently treats a `&mut T` reference-to-a-generic as an impl on the reference primitive itself. `&mut Self` counts as a generic in the eyes of rustdoc. All this combines to create this lovely scene on `Iterator::by_ref`:
<details><summary>`Iterator::by_ref` spotlights Iterator, Read, and Write (pic of old design)</summary>
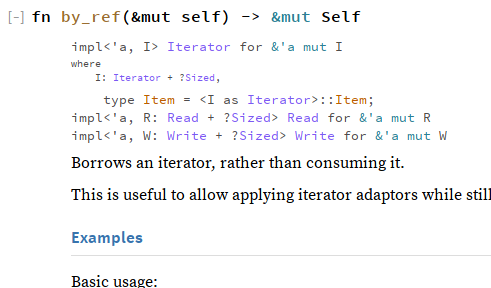
</details>
|
|
|
|
|
|
This patch makes `read_to_end` use Vec's memory-growth pattern rather
than using a custom pattern.
This has some interesting effects:
- If memory is reserved up front, `read_to_end` can be faster, as it
starts reading at the buffer size, rather than always starting at 32
bytes. This speeds up file reading by 2x in one of my use cases.
- It can reduce the number of syscalls when reading large files.
Previously, `read_to_end` would settle into a sequence of 8192-byte
reads. With this patch, the read size follows Vec's allocation
pattern. For example, on a 16MiB file, it can do 21 read syscalls
instead of 2057. In simple benchmarks of large files though, overall
speed is still dominated by the actual I/O.
- A downside is that Read implementations that don't implement
`initializer()` may see increased memory zeroing overhead.
I benchmarked this on a variety of data sizes, with and without
preallocated buffers. Most benchmarks see no difference, but reading
a small/medium file with a pre-allocated buffer is faster.
|
