| Age | Commit message (Collapse) | Author | Lines |
|---|
|
Create a single source scope for promoteds
A promoted inherits all scopes from the parent body. At the same time,
almost all statements and terminators inside the promoted body so far
refer only to one of those scopes: the outermost one.
Instead of inheriting all scopes, inherit only a single scope
corresponding to the location of the promoted, making sure that there
are no references to other scopes.
|
|
Simplify doc-cfg rendering based on the current context
For sub-items on a page don't show cfg that has already been rendered on
a parent item. At its simplest this means not showing anything that is
shown in the portability message at the top of the page, but also for
things like fields of an enum variant if that variant itself is
cfg-gated then don't repeat those cfg on each field of the variant.
This does not touch trait implementation rendering, as that is more
complex and there are existing issues around how it deals with doc-cfg
that need to be fixed first.
### Screenshots, left is current, right is new:
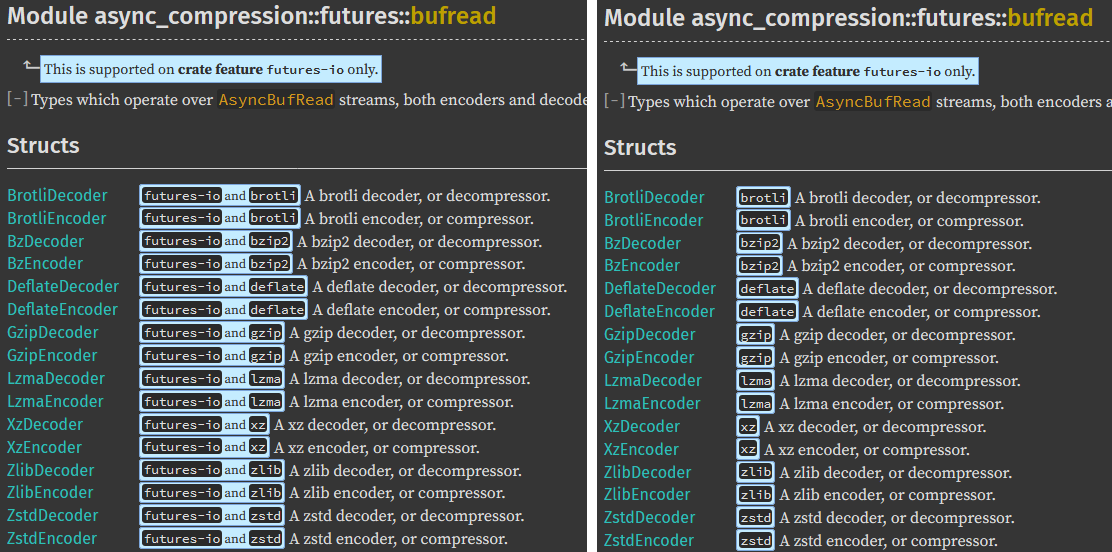



cc #43781
|
|
hosseind88:ICEs_should_always_print_the_top_of_the_query_stack, r=oli-obk
ICEs should always print the top of the query stack
see #76920
|
|
Stabilize move_ref_pattern
# Implementation
- Initially the rule was added in the run-up to 1.0. The AST-based borrow checker was having difficulty correctly enforcing match expressions that combined ref and move bindings, and so it was decided to simplify forbid the combination out right.
- The move to MIR-based borrow checking made it possible to enforce the rules in a finer-grained level, but we kept the rule in place in an effort to be conservative in our changes.
- In #68376, @Centril lifted the restriction but required a feature-gate.
- This PR removes the feature-gate.
Tracking issue: #68354.
# Description
This PR is to stabilize the feature `move_ref_pattern`, which allows patterns
containing both `by-ref` and `by-move` bindings at the same time.
For example: `Foo(ref x, y)`, where `x` is `by-ref`,
and `y` is `by-move`.
The rules of moving a variable also apply here when moving *part* of a variable,
such as it can't be referenced or moved before.
If this pattern is used, it would result in *partial move*, which means that
part of the variable is moved. The variable that was partially moved from
cannot be used as a whole in this case, only the parts that are still
not moved can be used.
## Documentation
- The reference (rust-lang/reference#881)
- Rust by example (rust-lang/rust-by-example#1377)
## Tests
There are many tests, but I think one of the comperhensive ones:
- [borrowck-move-ref-pattern-pass.rs](https://github.com/Centril/rust/blob/85fbf49ce0e2274d0acf798f6e703747674feec3/src/test/ui/pattern/move-ref-patterns/borrowck-move-ref-pattern-pass.rs)
- [borrowck-move-ref-pattern.rs](https://github.com/Centril/rust/blob/85fbf49ce0e2274d0acf798f6e703747674feec3/src/test/ui/pattern/move-ref-patterns/borrowck-move-ref-pattern.rs)
# Examples
```rust
#[derive(PartialEq, Eq)]
struct Finished {}
#[derive(PartialEq, Eq)]
struct Processing {
status: ProcessStatus,
}
#[derive(PartialEq, Eq)]
enum ProcessStatus {
One,
Two,
Three,
}
#[derive(PartialEq, Eq)]
enum Status {
Finished(Finished),
Processing(Processing),
}
fn check_result(_url: &str) -> Status {
// fetch status from some server
Status::Processing(Processing {
status: ProcessStatus::One,
})
}
fn wait_for_result(url: &str) -> Finished {
let mut previous_status = None;
loop {
match check_result(url) {
Status::Finished(f) => return f,
Status::Processing(p) => {
match (&mut previous_status, p.status) {
(None, status) => previous_status = Some(status), // first status
(Some(previous), status) if *previous == status => {} // no change, ignore
(Some(previous), status) => { // Now it can be used
// new status
*previous = status;
}
}
}
}
}
}
```
Before, we would have used:
```rust
match (&previous_status, p.status) {
(Some(previous), status) if *previous == status => {} // no change, ignore
(_, status) => {
// new status
previous_status = Some(status);
}
}
```
Demonstrating *partial move*
```rust
fn main() {
#[derive(Debug)]
struct Person {
name: String,
age: u8,
}
let person = Person {
name: String::from("Alice"),
age: 20,
};
// `name` is moved out of person, but `age` is referenced
let Person { name, ref age } = person;
println!("The person's age is {}", age);
println!("The person's name is {}", name);
// Error! borrow of partially moved value: `person` partial move occurs
//println!("The person struct is {:?}", person);
// `person` cannot be used but `person.age` can be used as it is not moved
println!("The person's age from person struct is {}", person.age);
}
```
|
|
Refactor io/buffered.rs into submodules
This pull request splits `BufWriter`, `BufReader`, `LineWriter`, and `LineWriterShim` (along with their associated tests) into separate submodules. It contains no functional changes. This change is being made in anticipation of adding another type of buffered writer which can be switched between line- and block-buffering mode.
Part of a series of pull requests resolving #60673.
|
|
mangling: mangle impl params w/ v0 scheme
This PR modifies v0 symbol mangling to include all generic parameters from impl blocks (not just those used in the self type) - an alternative fix to #75326.
```
original:
_RNCNvXCs4fqI2P2rA04_19impl_param_manglingINtB4_3FooppENtNtNtNtCsfnEnqCNU58Z_4core4iter6traits8iterator8Iterator4next0B4_
// |------------ B4_ ----------------|
// _R (N C (N v (X (C ((s 4fqI2p2rA04_) 19impl_param_mangling)) (I (N t B4_ 3Foo) pp E) (N t (N t (N t (N t (C ((s fnEnqCNU58Z_) 4core)) 4iter) 6traits) 8iterator) 8Iterator)) 4next) 0) B4_
modified:
_RNvXINICs4fqI2P2rA04_11issue_753260pppEINtB5_3FooppENtNtNtNtCsfnEnqCNU58Z_4core4iter6traits8iterator8Iterator4nextB5_
// _R (N v (X (I (N I (C ((s 4fqI2P2rA04_) 11issue_75326)) 0) ppp E) (I (N t B5_ 3Foo) pp E) (N t (N t (N t (N t (C ((s fnEnqCNU58Z_) 4core)) 4iter) 6traits) 8iterator) 8Iterator)) 4next) B5_
// | ^ |
// | | |
// | new impl namespace |
```
~~Submitted as a draft as after some discussion w/ @eddyb, I'm going to do some investigation into (yet more alternative) changes to polymorphization that might remove the necessity for this.~~
r? @eddyb
|
|
|
|
|
|
This commit modifies v0 symbol mangling to include all generic
parameters from impl blocks (not just those used in the self type).
Signed-off-by: David Wood <david@davidtw.co>
|
|
r=nikomatsakis
Replace tuple of infer vars for upvar_tys with single infer var
This commit allows us to decide the number of captures required after
completing capture ananysis, which is required as part of implementing
RFC-2229.
closes https://github.com/rust-lang/project-rfc-2229/issues/4
r? `@nikomatsakis`
|
|
Check html comments
Part of #67799.
cc @ollie27
r? @jyn514
|
|
Allow ascii whitespace char for doc aliases
Fixes issue from https://github.com/rust-lang/rust/issues/76705#issuecomment-703123847
cc @lopopolo @ollie27
r? @jyn514
|
|
|
|
Add some regression tests
They're fixed since nightly-2020-10-07:
Closes #52843
Closes #53448
Closes #54108
Closes #65581
Closes #65934
Closes #70292
Closes #71443
|
|
Rollup of 8 pull requests
Successful merges:
- #77765 (Add LLVM flags to limit DWARF version to 2 on BSD)
- #77788 (BTreeMap: fix gdb provider on BTreeMap with ZST keys or values)
- #77795 (Codegen backend interface refactor)
- #77808 (Moved the main `impl` for FnCtxt to its own file.)
- #77817 (Switch rustdoc from `clean::Stability` to `rustc_attr::Stability`)
- #77829 (bootstrap: only use compiler-builtins-c if they exist)
- #77870 (Use intra-doc links for links to module-level docs)
- #77897 (Move `Strip` into a separate rustdoc pass)
Failed merges:
- #77879 (Provide better documentation and help messages for x.py setup)
- #77902 (Include aarch64-pc-windows-msvc in the dist manifests)
r? `@ghost`
|
|
Codegen backend interface refactor
This moves several things away from the codegen backend to rustc_interface. There are a few behavioral changes where previously the incremental cache (incorrectly) wouldn't get finalized, but now it does. See the individual commit messages.
|
|
BTreeMap: fix gdb provider on BTreeMap with ZST keys or values
Avoid error when gdb is asked to inspect a BTreeMap or BTreeSet with a zero-sized type as key or value. And clean up.
r? @Mark-Simulacrum
|
|
Refactor AST pretty-printing to allow skipping insertion of extra parens
Fixes #75734
Makes progress towards #43081
Unblocks PR #76130
When pretty-printing an AST node, we may insert additional parenthesis
to ensure that precedence is properly preserved in code we output.
However, the proc macro implementation relies on comparing a
pretty-printed AST node to the captured `TokenStream`. Inserting extra
parenthesis changes the structure of the reparsed `TokenStream`, making
the comparison fail.
This PR refactors the AST pretty-printing code to allow skipping the
insertion of additional parenthesis. Several freestanding methods are
moved to trait methods on `PrintState`, which keep track of an internal
`insert_extra_parens` flag. This flag is normally `true`, but we expose
a public method which allows pretty-printing a nonterminal with
`insert_extra_parens = false`.
To avoid changing the public interface of `rustc_ast_pretty`, the
freestanding `_to_string` methods are changed to delegate to a
newly-crated `State`. The main pretty-printing code is moved to a new
`state` module to ensure that it does not accidentally call any of these
public helper functions (instead, the internal functions with the same
name should be used).
|
|
A promoted inherits all scopes from the parent body. At the same time,
almost all statements and terminators inside the promoted body so far
refer only to one of those scopes: the outermost one.
Instead of inheriting all scopes, inherit only a single scope
corresponding to the location of the promoted, making sure that there
are no references to other scopes.
|
|
Rollup of 14 pull requests
Successful merges:
- #77239 (Enable building Cargo for aarch64-apple-darwin)
- #77569 (BTreeMap: type-specific variants of node_as_mut and cast_unchecked)
- #77719 (Remove unnecessary rustc_const_stable attributes.)
- #77722 (Remove unsafety from sys/unsupported and add deny(unsafe_op_in_unsafe_fn).)
- #77725 (Add regression issue template)
- #77776 ( Give an error when running `x.py test --stage 0 src/test/ui`)
- #77786 (Mention rustdoc in `x.py setup`)
- #77825 (`min_const_generics` diagnostics improvements)
- #77868 (Include `llvm-dis`, `llc` and `opt` in `llvm-tools-preview` component)
- #77884 (Use Option::unwrap_or instead of open-coding it)
- #77886 (Replace trivial bool matches with the `matches!` macro)
- #77892 (Replace absolute paths with relative ones)
- #77895 (Include aarch64-apple-darwin in the dist manifests)
- #77909 (bootstrap: set correct path for the build-manifest binary)
Failed merges:
- #77902 (Include aarch64-pc-windows-msvc in the dist manifests)
r? `@ghost`
|
|
`min_const_generics` diagnostics improvements
As disscussed in [zulip/project-const-generics/non-trivial anonymous constant](https://rust-lang.zulipchat.com/#narrow/stream/260443-project-const-generics/topic/non-trivial.20anonymous.20constants).
This is my first PR on the compiler.
@lcnr is mentoring me on this PR.
Related to #60551.
|
|
|
|
|
|
|
|
|
|
rustdoc: skip #[allow(missing docs)] for docs in coverage report
During the document coverage reporting with:
```bash
rustdoc something.rs -Z unstable-options --show-coverage
```
the coverage report counts code that is marked with `#[allow(missing_docs)]` for the calculation, which outputs lower numbers in the coverage report even though these parts should be ignored for the calculation.
Right now I'm not sure how this can be tested (CI)? (I verified it by hand and ran the unit tests)
r? `@jyn514`
**Reference:** Fixes #76121
|
|
Pass tune-cpu to LLVM
I think this is how it should work...
See https://internals.rust-lang.org/t/expose-tune-cpu-from-llvm/13088 for the background. Or the documentation diff.
|
|
|
|
|
|
|
|
|
|
During the document coverage reporting with
```bash
rustdoc something.rs -Z unstable-options --show-coverage
```
the coverage report also includes parts of the code that are marked
with `#[allow(missing_docs)]`, which outputs lower numbers in the
coverage report even though these parts should be ignored for the
calculation.
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
|
|
Fix -Clinker-plugin-lto with opt-levels s and z
Pass s and z as `-plugin-opt=O2` to the linker. This is what `-Os` and `-Oz` correspond to, apparently.
Fixes https://github.com/rust-lang/rust/issues/75940
|
|
Show summary lines on cross-crate re-exports
See my write-up in https://github.com/rust-lang/rust/issues/77783#issuecomment-706551743 for what's going on here.
Fixes https://github.com/rust-lang/rust/issues/77783
r? `@ollie27`
|
|
This removes the unnecessary `DocFragmentKind::Divider` in favor of just
using the logic I actually want in `collapse_docs`.
|
|
|
|
|
|
Use llvm::computeLTOCacheKey to determine post-ThinLTO CGU reuse
During incremental ThinLTO compilation, we attempt to re-use the
optimized (post-ThinLTO) bitcode file for a module if it is 'safe' to do
so.
Up until now, 'safe' has meant that the set of modules that our current
modules imports from/exports to is unchanged from the previous
compilation session. See PR #67020 and PR #71131 for more details.
However, this turns out be insufficient to guarantee that it's safe
to reuse the post-LTO module (i.e. that optimizing the pre-LTO module
would produce the same result). When LLVM optimizes a module during
ThinLTO, it may look at other information from the 'module index', such
as whether a (non-imported!) global variable is used. If this
information changes between compilation runs, we may end up re-using an
optimized module that (for example) had dead-code elimination run on a
function that is now used by another module.
Fortunately, LLVM implements its own ThinLTO module cache, which is used
when ThinLTO is performed by a linker plugin (e.g. when clang is used to
compile a C proect). Using this cache directly would require extensive
refactoring of our code - but fortunately for us, LLVM provides a
function that does exactly what we need.
The function `llvm::computeLTOCacheKey` is used to compute a SHA-1 hash
from all data that might influence the result of ThinLTO on a module.
In addition to the module imports/exports that we manually track, it
also hashes information about global variables (e.g. their liveness)
which might be used during optimization. By using this function, we
shouldn't have to worry about new LLVM passes breaking our module re-use
behavior.
In LLVM, the output of this function forms part of the filename used to
store the post-ThinLTO module. To keep our current filename structure
intact, this PR just writes out the mapping 'CGU name -> Hash' to a
file. To determine if a post-LTO module should be reused, we compare
hashes from the previous session.
This should unblock PR #75199 - by sheer chance, it seems to have hit
this issue due to the particular CGU partitioning and optimization
decisions that end up getting made.
|
|
2
3
|
|
This extends the existing `ident_name_compatibility_hack` to handle the
`tuple_from_req` macro defined in `actix-web` (and its fork
`actori-web`).
|
|
Fixes #74616
Makes progress towards #43081
Unblocks PR #76130
When pretty-printing an AST node, we may insert additional parenthesis
to ensure that precedence is properly preserved in code we output.
However, the proc macro implementation relies on comparing a
pretty-printed AST node to the captured `TokenStream`. Inserting extra
parenthesis changes the structure of the reparsed `TokenStream`, making
the comparison fail.
This PR refactors the AST pretty-printing code to allow skipping the
insertion of additional parenthesis. Several freestanding methods are
moved to trait methods on `PrintState`, which keep track of an internal
`insert_extra_parens` flag. This flag is normally `true`, but we expose
a public method which allows pretty-printing a nonterminal with
`insert_extra_parens = false`.
To avoid changing the public interface of `rustc_ast_pretty`, the
freestanding `_to_string` methods are changed to delegate to a
newly-crated `State`. The main pretty-printing code is moved to a new
`state` module to ensure that it does not accidentally call any of these
public helper functions (instead, the internal functions with the same
name should be used).
|
|
Co-authored-by: Roxane Fruytier <roxane.fruytier@hotmail.com>
|
|
Depending on if upvar_tys inferred or not, we were returning either an
inference variable which later resolves to a tuple or else the upvar tys
themselves
Co-authored-by: Roxane Fruytier <roxane.fruytier@hotmail.com>
|
|
This commit allows us to decide the number of captures required after
completing capture ananysis, which is required as part of implementing
RFC-2229.
Co-authored-by: Aman Arora <me@aman-arora.com>
Co-authored-by: Jenny Wills <wills.jenniferg@gmail.com>
|
|
Replace run_compiler with RunCompiler builder pattern
Fixes #77286. Replaces rustc_driver:run_compiler with RunCompiler builder pattern.
|
|
Provide structured suggestions when finding structs when expecting a trait
When finding an ADT in a trait object definition provide some solutions. Fix #45817.
Given `<Param as Trait>::Assoc: Ty` suggest `Param: Trait<Assoc = Ty>`. Fix #75829.
|
|
Allow generic parameters in intra-doc links
Fixes #62834.
---
The contents of the generics will be mostly ignored (except for warning
if fully-qualified syntax is used, which is currently unsupported in
intra-doc links - see issue #74563).
* Allow links like `Vec<T>`, `Result<T, E>`, and `Option<Box<T>>`
* Allow links like `Vec::<T>::new()`
* Warn on
* Unbalanced angle brackets (e.g. `Vec<T` or `Vec<T>>`)
* Missing type to apply generics to (`<T>` or `<Box<T>>`)
* Use of fully-qualified syntax (`<Vec as IntoIterator>::into_iter`)
* Invalid path separator (`Vec:<T>:new`)
* Too many angle brackets (`Vec<<T>>`)
* Empty angle brackets (`Vec<>`)
Note that this implementation *does* allow some constructs that aren't
valid in the actual Rust syntax, for example `Box::<T>new()`. That may
not be supported in rustdoc in the future; it is an implementation
detail.
|
|
Add asm! support for mips64
- [x] Updated `src/doc/unstable-book/src/library-features/asm.md`.
- [ ] No vector type support. I don't know much about those types.
cc #76839
|
|
|
|
Revert "Assume slice len is bounded by allocation size"
https://github.com/rust-lang/rust/pull/77023#issuecomment-703987379
suggests that the original PR introduced a significant perf regression.
This reverts commit e44784b8750016a695361c990024750e037d8f9f / #77023.
cc `@HeroicKatora`
|
