| Age | Commit message (Collapse) | Author | Lines |
|---|
|
Actually use the inferred `ClosureKind` from signature inference in coroutine-closures
A follow-up to https://github.com/rust-lang/rust/pull/123349, which fixes another subtle bug: We were not taking into account the async closure kind we infer during closure signature inference.
When I pass a closure directly to an arg like `fn(x: impl async FnOnce())`, that should have the side-effect of artificially restricting the kind of the async closure to `ClosureKind::FnOnce`. We weren't doing this -- that's a quick fix; however, it uncovers a second, more subtle bug with the way that `move`, async closures, and `FnOnce` interact.
Specifically, when we have an async closure like:
```
let x = Struct;
let c = infer_as_fnonce(async move || {
println!("{x:?}");
}
```
The outer closure captures `x` by move, but the inner coroutine still immutably borrows `x` from the outer closure. Since we've forced the closure to by `async FnOnce()`, we can't actually *do* a self borrow, since the signature of `AsyncFnOnce::call_once` doesn't have a borrowed lifetime. This means that all `async move` closures that are constrained to `FnOnce` will fail borrowck.
We can fix that by detecting this case specifically, and making the *inner* async closure `move` as well. This is always beneficial to closure analysis, since if we have an `async FnOnce()` that's `move`, there's no reason to ever borrow anything, so `move` isn't artificially restrictive.
|
|
r=Mark-Simulacrum
Port argument-non-c-like-enum to Rust
Part of #121876.
|
|
Vendor rustc_codegen_gcc
I used https://github.com/rust-lang/rust/pull/115274 as base for this update.
r? `@bjorn3`
|
|
remove miri jobserver workaround
This PR removes workaround, added in #113730, since jobserver is kept after [rust-lang/cargo#12776](https://github.com/rust-lang/cargo/pull/12776)
|
|
Rollup of 9 pull requests
Successful merges:
- #123206 (Require Pointee::Metadata to be Freeze)
- #123363 (change `NormalizesTo` to fully structurally normalize)
- #123407 (Default to light theme if JS is enabled but not working)
- #123417 (Add Description for cargo in rustdoc documentation)
- #123437 (Manually run `clang-format` on `CoverageMappingWrapper.cpp`)
- #123454 (hir: Use `ItemLocalId::ZERO` in a couple more places)
- #123464 (Cleanup: Rename `HAS_PROJECTIONS` to `HAS_ALIASES` etc.)
- #123477 (do not ICE in `fn forced_ambiguity` if we get an error)
- #123478 (CFI: Add test for `call_once` addr taken)
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
Add Description for cargo in rustdoc documentation
As most people use cargo now, I prioritised the description for cargo in rustdoc documentation.
I also added how to open the generated doc with cargo.
Btw, may I ask how to use `./x tidy`? It says `warning: `tidy` is not installed;`
|
|
Default to light theme if JS is enabled but not working
It doesn't [fix] #123399 but it allows to reduce the problem:
* if JS is completely disabled, then `noscript.css` will be applied
* if JS failed for any reason, then the light theme will be applied (because `noscript.css` won't be applied)
r? `@notriddle`
|
|
Clippy subtree update
r? `@Manishearth`
|
|
also `move`
|
|
coroutine-closures
|
|
|
|
|
|
|
|
clippy-subtree-update
|
|
some smaller DefiningOpaqueTypes::No -> Yes switches
r? `@compiler-errors`
These are some easy cases, so let's get them out of the way first.
I added tests exercising the specialization code paths that I believe weren't tested so far.
follow-up to https://github.com/rust-lang/rust/pull/117348
|
|
|
|
Port hir-tree run-make test to ui test
As part of #121876
cc `@jieyouxu`
|
|
|
|
Since we have a `DefiningAnchor::Error`, we will reject registering hidden types already
|
|
instantiate higher ranked goals outside of candidate selection
This PR modifies `evaluate` to more eagerly instantiate higher-ranked goals, preventing the `leak_check` during candidate selection from detecting placeholder errors involving that binder.
For a general background regarding higher-ranked region solving and the leak check, see https://hackmd.io/qd9Wp03cQVy06yOLnro2Kg.
> The first is something called the **leak check**. You can think of it as a "quick and dirty" approximation for the region check, which will come later. The leak check detects some kinds of errors early, essentially deciding between "this set of outlives constraints are guaranteed to result in an error eventually" or "this set of outlives constraints may be solvable".
## The ideal future
We would like to end up with the following idealized design to handle universal binders:
```rust
fn enter_forall<'tcx, T, R>(
forall: Binder<'tcx, T>,
f: impl FnOnce(T) -> R,
) -> R {
let new_universe = infcx.increment_universe_index();
let value = instantiate_binder_with_placeholders_in(new_universe, forall);
let result = f(value);
eagerly_handle_higher_ranked_region_constraints_in(new_universe);
infcx.decrement_universe_index();
assert!(!result.has_placeholders_in_or_above(new_universe));
result
}
```
That is, when universally instantiating a binder, anything using the placeholders has to happen inside of a limited scope (the closure `f`). After this closure has completed, all constraints involving placeholders are known.
We then handle any *external constraints* which name these placeholders. We destructure `TypeOutlives` constraints involving placeholders and eagerly handle any region constraints involving these placeholders. We do not return anything mentioning the placeholders created inside of this function to the caller.
Being able to eagerly handle *all* region constraints involving placeholders will be difficult due to complex `TypeOutlives` constraints, involving inference variables or alias types, and higher ranked implied bounds. The exact issues and possible solutions are out of scope of this FCP.
#### How does the leak check fit into this
The `leak_check` is an underapproximation of `eagerly_handle_higher_ranked_region_constraints_in`. It detects some kinds of errors involving placeholders from `new_universe`, but not all of them.
It only looks at region outlives constraints, ignoring `TypeOutlives`, and checks whether one of the following two conditions are met for **placeholders in or above `new_universe`**, in which case it results in an error:
- `'!p1: '!p2` a placeholder `'!p2` outlives a different placeholder `'!p1`
- `'!p1: '?2` an inference variable `'?2` outlives a placeholder `'!p1` *which it cannot name*
It does not handle all higher ranked region constraints, so we still return constraints involving placeholders from `new_universe` which are then (re)checked by `lexical_region_resolve` or MIR borrowck.
As we check higher ranked constraints in the full regionck anyways, the `leak_check` is not soundness critical. It's current only purpose is to move some higher ranked region errors earlier, enabling it to guide type inference and trait solving. Adding additional uses of the `leak_check` in the future would only strengthen inference and is therefore not breaking.
## Where do we use currently use the leak check
The `leak_check` is currently used in two places:
Coherence does not use a proper regionck, only relying on the `leak_check` called [at the end of the implicit negative overlap check](https://github.com/rust-lang/rust/blob/8b94152af68a0ed6d6af0b5ba57491e40481008e/compiler/rustc_trait_selection/src/traits/coherence.rs#L235-L238). During coherence all parameters are instantiated with inference variables, so the only possible region errors are higher-ranked. We currently also sometimes make guesses when destructuring `TypeOutlives` constraints which can theoretically result in incorrect errors. This could result in overlapping impls.
We also use the `leak_check` [at the end of `fn evaluation_probe`](https://github.com/rust-lang/rust/blob/8b94152af68a0ed6d6af0b5ba57491e40481008e/compiler/rustc_trait_selection/src/traits/select/mod.rs#L607-L610). This function is used during candidate assembly for `Trait` goals. Most notably we use [inside of `evaluate_candidate` during winnowing](https://github.com/rust-lang/rust/blob/0e4243538b9119654c22dce688f8a63c81864de9/compiler/rustc_trait_selection/src/traits/select/mod.rs#L491-L502). Conceptionally, it is as if we compute each candidate in a separate `enter_forall`.
## The current use in `fn evaluation_probe` is undesirable
Because we only instantiate a higher-ranked goal once inside of `fn evaluation_probe`, errors involving placeholders from that binder can impact selection. This results in inconsistent behavior ([playground](
*[playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=dac60ebdd517201788899ffa77364831)*)):
```rust
trait Leak<'a> {}
impl Leak<'_> for Box<u32> {}
impl Leak<'static> for Box<u16> {}
fn impls_leak<T: for<'a> Leak<'a>>() {}
trait IndirectLeak<'a> {}
impl<'a, T: Leak<'a>> IndirectLeak<'a> for T {}
fn impls_indirect_leak<T: for<'a> IndirectLeak<'a>>() {}
fn main() {
// ok
//
// The `Box<u16>` impls fails the leak check,
// meaning that we apply the `Box<u32>` impl.
impls_leak::<Box<_>>();
// error: type annotations needed
//
// While the `Box<u16>` impl would fail the leak check
// we have already instantiated the binder while applying
// the generic `IndirectLeak` impl, so during candidate
// selection of `Leak` we do not detect the placeholder error.
// Evaluation of `Box<_>: Leak<'!a>` is therefore ambiguous,
// resulting in `for<'a> Box<_>: Leak<'a>` also being ambiguous.
impls_indirect_leak::<Box<_>>();
}
```
We generally prefer `where`-bounds over implementations during candidate selection, both for [trait goals](https://github.com/rust-lang/rust/blob/11f32b73e0dc9287e305b5b9980d24aecdc8c17f/compiler/rustc_trait_selection/src/traits/select/mod.rs#L1863-L1887) and during [normalization](https://github.com/rust-lang/rust/blob/11f32b73e0dc9287e305b5b9980d24aecdc8c17f/compiler/rustc_trait_selection/src/traits/project.rs#L184-L198). However, we currently **do not** use the `leak_check` during candidate assembly in normalizing. This can result in inconsistent behavior:
```rust
trait Trait<'a> {
type Assoc;
}
impl<'a, T> Trait<'a> for T {
type Assoc = usize;
}
fn trait_bound<T: for<'a> Trait<'a>>() {}
fn projection_bound<T: for<'a> Trait<'a, Assoc = usize>>() {}
// A function with a trivial where-bound which is more
// restrictive than the impl.
fn function<T: Trait<'static, Assoc = usize>>() {
// ok
//
// Proving `for<'a> T: Trait<'a>` using the where-bound results
// in a leak check failure, so we use the more general impl,
// causing this to succeed.
trait_bound::<T>();
// error
//
// Proving the `Projection` goal `for<'a> T: Trait<'a, Assoc = usize>`
// does not use the leak check when trying the where-bound, causing us
// to prefer it over the impl, resulting in a placeholder error.
projection_bound::<T>();
// error
//
// Trying to normalize the type `for<'a> fn(<T as Trait<'a>>::Assoc)`
// only gets to `<T as Trait<'a>>::Assoc` once `'a` has been already
// instantiated, causing us to prefer the where-bound over the impl
// resulting in a placeholder error. Even if were were to also use the
// leak check during candidate selection for normalization, this
// case would still not compile.
let _higher_ranked_norm: for<'a> fn(<T as Trait<'a>>::Assoc) = |_| ();
}
```
This is also likely to be more performant. It enables more caching in the new trait solver by simply [recursively calling the canonical query][new solver] after instantiating the higher-ranked goal.
It is also unclear how to add the leak check to normalization in the new solver. To handle https://github.com/rust-lang/trait-system-refactor-initiative/issues/1 `Projection` goals are implemented via `AliasRelate`. This again means that we instantiate the binder before ever normalizing any alias. Even if we were to avoid this, we lose the ability to [cache normalization by itself, ignoring the expected `term`](https://github.com/rust-lang/rust/blob/5bd5d214effd494f4bafb29b3a7a2f6c2070ca5c/compiler/rustc_trait_selection/src/solve/normalizes_to/mod.rs#L34-L49). We cannot replace the `term` with an inference variable before instantiating the binder, as otherwise `for<'a> T: Trait<Assoc<'a> = &'a ()>` breaks. If we only replace the term after instantiating the binder, we cannot easily evaluate the goal in a separate context, as [we'd then lose the information necessary for the leak check](https://github.com/rust-lang/rust/blob/11f32b73e0dc9287e305b5b9980d24aecdc8c17f/compiler/rustc_next_trait_solver/src/canonicalizer.rs#L230-L232). Adding this information to the canonical input also seems non-trivial.
## Proposed solution
I propose to instantiate the binder outside of candidate assembly, causing placeholders from higher-ranked goals to get ignored while selecting their candidate. This mostly[^1] matches the [current behavior of the new solver][new solver]. The impact of this change is therefore as follows:
```rust
trait Leak<'a> {}
impl Leak<'_> for Box<u32> {}
impl Leak<'static> for Box<u16> {}
fn impls_leak<T: for<'a> Leak<'a>>() {}
trait IndirectLeak<'a> {}
impl<'a, T: Leak<'a>> IndirectLeak<'a> for T {}
fn impls_indirect_leak<T: for<'a> IndirectLeak<'a>>() {}
fn guide_selection() {
// ok -> ambiguous
impls_leak::<Box<_>>();
// ambiguous
impls_indirect_leak::<Box<_>>();
}
trait Trait<'a> {
type Assoc;
}
impl<'a, T> Trait<'a> for T {
type Assoc = usize;
}
fn trait_bound<T: for<'a> Trait<'a>>() {}
fn projection_bound<T: for<'a> Trait<'a, Assoc = usize>>() {}
// A function which a trivial where-bound which is more
// restrictive than the impl.
fn function<T: Trait<'static, Assoc = usize>>() {
// ok -> error
trait_bound::<T>();
// error
projection_bound::<T>();
// error
let _higher_ranked_norm: for<'a> fn(<T as Trait<'a>>::Assoc) = |_| ();
}
```
This does not change the behavior if candidates have higher ranked nested goals, as in this case the `leak_check` causes the nested goal to result in an error ([playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=a74c25300b23db9022226de99d8a2fa6)):
```rust
trait LeakCheckFailure<'a> {}
impl LeakCheckFailure<'static> for () {}
trait Trait<T> {}
impl Trait<u32> for () where for<'a> (): LeakCheckFailure<'a> {}
impl Trait<u16> for () {}
fn impls_trait<T: Trait<U>, U>() {}
fn main() {
// ok
//
// It does not matter whether candidate assembly
// considers the placeholders from higher-ranked goal.
//
// Either `for<'a> (): LeakCheckFailure<'a>` has no
// applicable candidate or it has a single applicable candidate
// when then later results in an error. This allows us to
// infer `U` to `u16`.
impls_trait::<(), _>()
}
```
## Impact on existing crates
This is a **breaking change**. [A crater run](https://github.com/rust-lang/rust/pull/119820#issuecomment-1926862174) found 17 regressed crates with 7 root causes.
For a full analysis of all affected crates, see https://gist.github.com/lcnr/7c1c652f30567048ea240554a36ed95c.
---
I believe this breakage to be acceptable and would merge this change. I am confident that the new position of the leak check matches our idealized future and cannot envision any other consistent alternative. Where possible, I intend to open PRs fixing/avoiding the regressions before landing this PR.
I originally intended to remove the `coherence_leak_check` lint in the same PR. However, while I am confident in the *position* of the leak check, deciding on its exact behavior is left as future work, cc #112999. This PR therefore only moves the leak check while keeping the lint when relying on it in coherence.
[new solver]: https://github.com/rust-lang/rust/blob/master/compiler/rustc_trait_selection/src/solve/eval_ctxt/mod.rs#L479-L484
[^1]: the new solver has a separate cause of inconsistent behavior rn https://github.com/rust-lang/trait-system-refactor-initiative/issues/53#issuecomment-1914310171
r? `@nikomatsakis`
|
|
|
|
Fix target name in NetBSD platform-support doc
NetBSD platform-support doc currently mentions `amd64-unknown-netbsd`, but it is not a valid target name (the correct name is `x86_64-unknown-netbsd`).
https://github.com/rust-lang/rust/blob/ceab6128fa48a616bfd3e3adf4bc80133b8ee223/src/doc/rustc/src/platform-support/netbsd.md?plain=1#L16
```console
$ rustc --print target-list | grep netbsd
aarch64-unknown-netbsd
aarch64_be-unknown-netbsd
armv6-unknown-netbsd-eabihf
armv7-unknown-netbsd-eabihf
i586-unknown-netbsd
i686-unknown-netbsd
mipsel-unknown-netbsd
powerpc-unknown-netbsd
riscv64gc-unknown-netbsd
sparc64-unknown-netbsd
x86_64-unknown-netbsd
```
|
|
Move some tests
r? `@petrochenkov`
|
|
Rename `expose_addr` to `expose_provenance`
`expose_addr` is a bad name, an address is just a number and cannot be exposed. The operation is actually about the provenance of the pointer.
This PR thus changes the name of the method to `expose_provenance` without changing its return type. There is sufficient precedence for returning a useful value from an operation that does something else without the name indicating such, e.g. [`Option::insert`](https://doc.rust-lang.org/nightly/std/option/enum.Option.html#method.insert) and [`MaybeUninit::write`](https://doc.rust-lang.org/nightly/std/mem/union.MaybeUninit.html#method.write).
Returning the address is merely convenient, not a fundamental part of the operation. This is implied by the fact that integers do not have provenance since
```rust
let addr = ptr.addr();
ptr.expose_provenance();
let new = ptr::with_exposed_provenance(addr);
```
must behave exactly like
```rust
let addr = ptr.expose_provenance();
let new = ptr::with_exposed_provenance(addr);
```
as the result of `ptr.expose_provenance()` and `ptr.addr()` is the same integer. Therefore, this PR removes the `#[must_use]` annotation on the function and updates the documentation to reflect the important part.
~~An alternative name would be `expose_provenance`. I'm not at all opposed to that, but it makes a stronger implication than we might want that the provenance of the pointer returned by `ptr::with_exposed_provenance`[^1] is the same as that what was exposed, which is not yet specified as such IIUC. IMHO `expose` does not make that connection.~~
A previous version of this PR suggested `expose` as name, libs-api [decided on](https://github.com/rust-lang/rust/pull/122964#issuecomment-2033194319) `expose_provenance` to keep the symmetry with `with_exposed_provenance`.
CC `@RalfJung`
r? libs-api
[^1]: I'm using the new name for `from_exposed_addr` suggested by #122935 here.
|
|
|
|
Output URLs of CI artifacts to GitHub summary
I often want to download CI artifacts published from our workflows (I suspect others might do the same), but it's a bit annoying to extract their links from the CI logs currently. This PR also outputs URLs to them to the GitHub Actions summaries.
r? `@Mark-Simulacrum`
|
|
Set `CARGO` instead of `PATH` for Rust Clippy
Resolves #123227
Previously, clippy was using `cargo` from `PATH`, but since [PR](https://github.com/rust-lang/rust-clippy/pull/11944), it now prioritises checking `CARGO` first.
|
|
x.py test: remove no-op --skip flag
None of the test commands seems to do anything with this flag, so we might as well remove it.
|
|
Add section to sanitizer doc for `-Zexternal-clangrt`
After spending a week looking for answers to how to do the very thing this flag lets me do, it felt appropriate to document it where I would've expected it to be.
|
|
|
|
|
|
|
|
|
|
Resolves #123227
|
|
Fix capture analysis for by-move closure bodies
The check we were doing to figure out if a coroutine was borrowing from its parent coroutine-closure was flat-out wrong -- a misunderstanding of mine of the way that `tcx.closure_captures` represents its captures.
Fixes #123251 (the miri/ui test I added should more than cover that issue)
r? `@oli-obk` -- I recognize that this PR may be underdocumented, so please ask me what I should explain further.
|
|
Update cargo
8 commits in a59aba136aab5510c16b0750a36cbd9916f91796..0637083df5bbdcc951845f0d2eff6999cdb6d30a
2024-03-28 21:21:41 +0000 to 2024-04-02 23:55:05 +0000
- chore(deps): update compatible (rust-lang/cargo#13674)
- Maintain sorting of dependency features (rust-lang/cargo#13682)
- Update `der` crate (rust-lang/cargo#13692)
- fix: bash completion fallback in `nounset` mode (rust-lang/cargo#13686)
- CI: Update macos images to macos-13 (rust-lang/cargo#13685)
- chore(deps): update rust crate opener to 0.7.0 (rust-lang/cargo#13679)
- Remove useless parameters (rust-lang/cargo#13678)
- chore(deps): update rust crate supports-unicode to v3 (rust-lang/cargo#13680)
r? ghost
|
|
|
|
After spending a week looking for answers to how to do the very thing
this flag lets me do, it felt appropriate to document it where I would've
expected it to be.
|
|
Improve bootstrap comments
Rewrote a comment I found hard to understand, added some more.
|
|
rename ptr::from_exposed_addr -> ptr::with_exposed_provenance
As discussed on [Zulip](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/To.20expose.20or.20not.20to.20expose/near/427757066).
The old name, `from_exposed_addr`, makes little sense as it's not the address that is exposed, it's the provenance. (`ptr.expose_addr()` stays unchanged as we haven't found a better option yet. The intended interpretation is "expose the provenance and return the address".)
The new name nicely matches `ptr::without_provenance`.
|
|
|
|
|
|
rustdoc: synthetic auto trait impls: accept unresolved region vars for now
https://github.com/rust-lang/rust/pull/123348#issuecomment-2032494255:
> Right, [in #123340] I've intentionally changed a `vid_map.get(vid).unwrap_or(r)` to a `vid_map[vid]` making rustdoc panic if `rustc::AutoTraitFinder` returns a region inference variable that cannot be resolved because that is really fishy. I can change it back with a `FIXME: investigate` […]. [O]nce I [fully] understand [the arcane] `rustc::AutoTraitFinder` [I] can fix the underlying issue if there's one.
>
> `rustc::AutoTraitFinder` can also return placeholder regions `RePlaceholder` which doesn't seem right either and which makes rustdoc ICE, too (we have a GitHub issue for that already[, namely #120606]).
Fixes #123370.
Fixes #112242.
r? ``@GuillaumeGomez``
|
|
Rewrote a comment I found hard to understand, added some more.
|
|
|
|
Update to new browser-ui-test version
This new version brings a lot of new internal improvements (mostly around validating the commands input).
It also improved some command names and arguments.
r? `@notriddle`
|
|
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
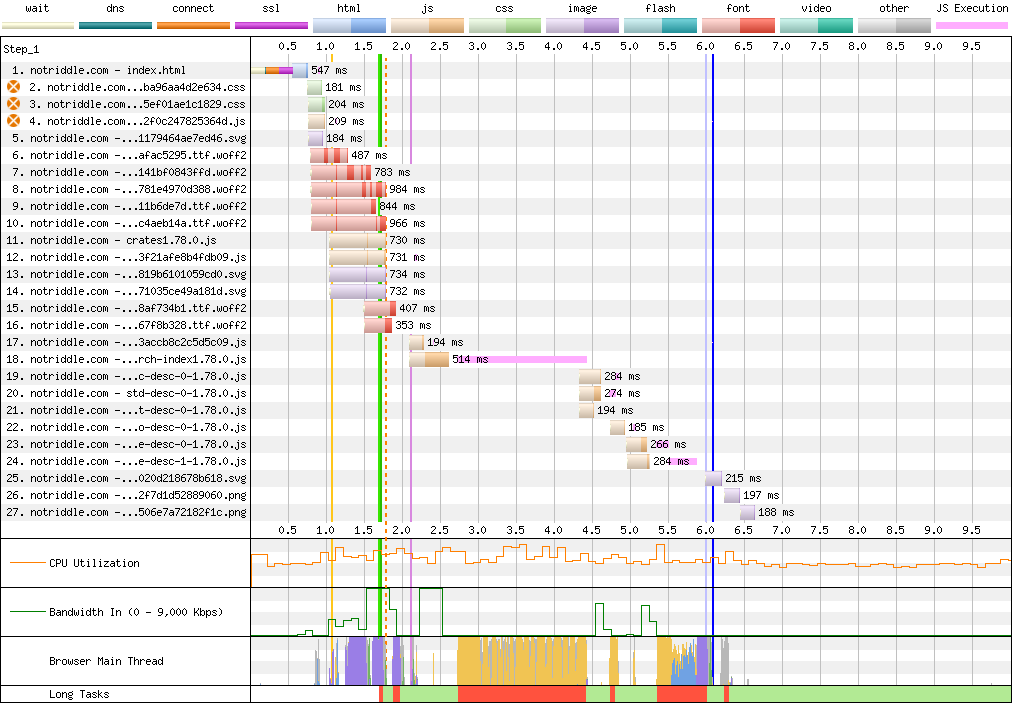
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
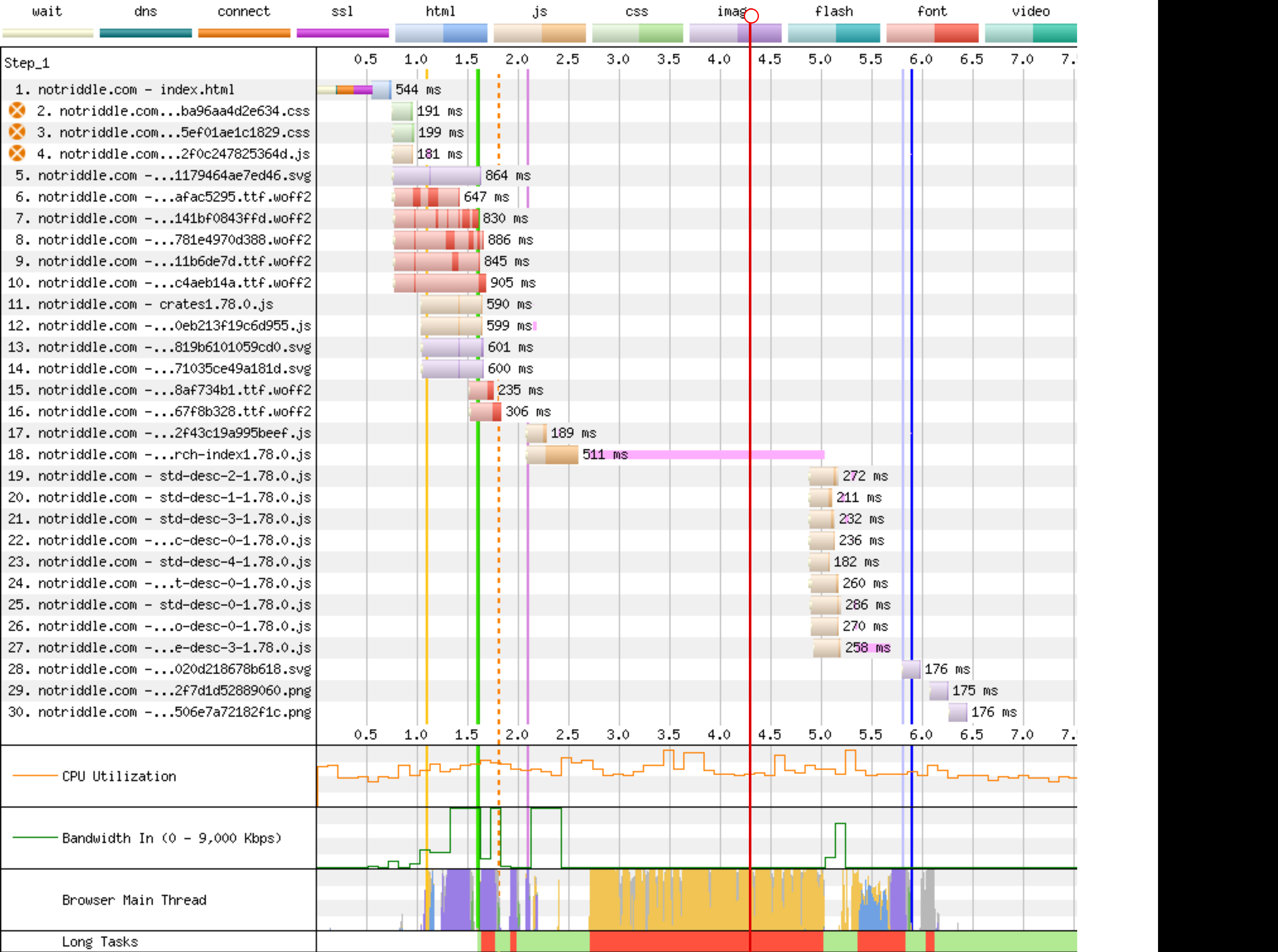
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
|
|
Co-authored-by: Guillaume Gomez <guillaume1.gomez@gmail.com>
|
|
r=GuillaumeGomez
rustdoc: heavily simplify the synthesis of auto trait impls
`gd --numstat HEAD~2 HEAD src/librustdoc/clean/auto_trait.rs`
**+315 -705** 🟩🟥🟥🟥⬛
---
As outlined in issue #113015, there are currently 3[^1] large separate routines that “clean” `rustc_middle::ty` data types related to generics & predicates to rustdoc data types. Every single one has their own kinds of bugs. While I've patched a lot of bugs in each of the routines in the past, it's about time to unify them. This PR is only the first in a series. It completely **yanks** the custom “bounds cleaning” of mod `auto_trait` and reuses the routines found in mod `simplify`. As alluded to, `simplify` is also flawed but it's still more complete than `auto_trait`'s routines. [See also my review comment over at `tests/rustdoc/synthetic_auto/bounds.rs`](https://github.com/rust-lang/rust/pull/123340#discussion_r1546900539).
This is preparatory work for rewriting “bounds cleaning” from scratch in follow-up PRs in order to finally [fix] #113015.
Apart from that, I've eliminated all potential sources of *instability* in the rendered output.
See also #119597. I'm pretty sure this fixes #119597.
This PR does not attempt to fix [any other issues related to synthetic auto trait impls](https://github.com/rust-lang/rust/issues?q=is%3Aissue+is%3Aopen+label%3AA-synthetic-impls%20label%3AA-auto-traits).
However, it's definitely meant to be a *stepping stone* by making `auto_trait` more contributor-friendly.
---
* Replace `FxHash{Map,Set}` with `FxIndex{Map,Set}` to guarantee a stable iteration order
* Or as a perf opt, `UnordSet` (a thin wrapper around `FxHashSet`) in cases where we never iterate over the set.
* Yes, we do make use of `swap_remove` but that shouldn't matter since all the callers are deterministic. It does make the output less “predictable” but it's still better than before. Ofc, I rely on `rustc_infer` being deterministic. I hope that holds.
* Utilizing `clean::simplify` over the custom “bounds cleaning” routines wipes out the last reference to `collect_referenced_late_bound_regions` in rustdoc (`simplify` uses `bound_vars`) which was a source of instability / unpredictability (cc #116388)
* Remove the types `RegionTarget` and `RegionDeps` from `librustdoc`. They were duplicates of the identical types found in `rustc`. Just import them from `rustc`. For some reason, they were duplicated when splitting `auto_trait` in two in #49711.
* Get rid of the useless “type namespace” `AutoTraitFinder` in `librustdoc`
* The struct only held a `DocContext`, it was over-engineered
* Turn the associated functions into free ones
* Eliminates rightward drift; increases legibility
* `rustc` also contains a useless `AutoTraitFinder` struct but I plan on removing that in a follow-up PR
* Rename a bunch of methods to be way more descriptive
* Eliminate `use super::*;`
* Lead to `clean/mod.rs` accumulating a lot of unnecessary imports
* Made `auto_traits` less modular
* Eliminate a custom `TypeFolder`: We can just use the rustc helper `fold_regions` which does that for us
I plan on adding extensive documentation to `librustdoc`'s `auto_trait` in follow-up PRs.
I don't want to do that in this PR because further refactoring & bug fix PRs may alter the overall structure of `librustdoc`'s & `rustc`'s `auto_trait` modules to a great degree. I'm slowly digging into the dark details of `rustc`'s `auto_trait` module again and once I have the full picture I will be able to provide proper docs.
---
While this PR does indeed touch `rustc`'s `auto_trait` — mostly tiny refactorings — I argue this PR doesn't need any compiler reviewers next to rustdoc ones since that module falls under the purview of rustdoc — it used to be part of `librustdoc` after all (#49711).
Sorry for not having split this into more commits. If you'd like me to I can try to split it into more atomic commits retroactively. However, I don't know if that would actually make reviewing easier. I think the best way to review this might just be to place the master version of `auto_trait` on the left of your screen and the patched one on the right, not joking.
r? `@GuillaumeGomez`
[^1]: Or even 4 depending on the way you're counting.
|
|
Note impact of `-Cstrip` on backtraces
It is not always clear to people what the impact of `-Cstrip` options are. They are a common question on sites like StackOverflow, and sometimes people even report bugs with "no backtrace" after deliberately mangling the symbol table. We cannot exhaustively document every permutation, but we should warn people about common effects.
|
