| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
Derive common traits for panic::Location.
Now that `#[track_caller]` is on track to stabilize, one of the roughest edges of working with it is the fact that you can't do much with `Location` except turn it back into a `(&str, u32, u32)`. Which makes sense because the type was defined around the panic machinery originally passing around that tuple (it has the same layout as Location even).
This PR derives common traits for the type in accordance with the [API guidelines](https://rust-lang.github.io/api-guidelines/interoperability.html#types-eagerly-implement-common-traits-c-common-traits) (those apply to core, right?).
There's a risk here, e.g. if we ever change the representation of `Location` in a way that makes it harder to implement `Ord`, we might not be able to make that change in a backwards-compatible way. I don't think there's any other compatibility hazard here, as the only changes we currently imagine for the type are to add end fields.
cc @rust-lang/libs
|
|
Make more primitive integer methods const
Now that #72437 has been merged and `const_if_match` is stable, these methods can be stabilized const. The methods are grouped in commits according to feature names:
* `const_nonzero_int_methods`
- `NonZero*::new`
* some `const_checked_int_methods`
- `{i*,u*}::checked_add`
- `{i*,u*}::checked_sub`
- `{i*,u*}::checked_mul`
- `{i*,u*}::checked_neg`
- `{i*,u*}::checked_shl`
- `{i*,u*}::checked_shr`
- `i*::checked_abs`
* `const_saturating_int_methods`
- `{i*,u*}::saturating_add`
- `{i*,u*}::saturating_sub`
- `{i*,u*}::saturating_mul`
- `i*::saturating_neg`
- `i*::saturating_abs`
* `const_int_sign`
- `i*::signum`
* `const_ascii_ctype_on_intrinsics`
- `{char,u8}::is_ascii_alphabetic`
- `{char,u8}::is_ascii_uppercase`
- `{char,u8}::is_ascii_lowercase`
- `{char,u8}::is_ascii_alphanumeric`
- `{char,u8}::is_ascii_digit`
- `{char,u8}::is_ascii_hexdigit`
- `{char,u8}::is_ascii_punctuation`
- `{char,u8}::is_ascii_graphic`
- `{char,u8}::is_ascii_whitespace`
- `{char,u8}::is_ascii_control`
|
|
|
|
Remove trait LengthAtMost32
This is a continuation of https://github.com/rust-lang/rust/pull/74026 preserving the original burrbull's commit.
I talked to @burrbull, he suggested me to finish his PR.
|
|
r=hanna-kruppe
Fix panic message when `RangeFrom` index is out of bounds
Before, the `Range` method was called with `end = slice.len()`. Unfortunately, because `Range::index` first checks the order of the indices (start has to be smaller than end), an out of bounds index leads to `core::slice::slice_index_order_fail` being called. This prints the message 'slice index starts at 27 but ends at 10', which is worse than 'index 27 out of range for slice of length 10'. This is not only useful to normal users reading panic messages, but also for people inspecting assembly and being confused by `slice_index_order_fail` calls.
You can see the produced assembly [here](https://rust.godbolt.org/z/GzMGWf) and try on Playground [here](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=aada5996b2f3848075a6d02cf4055743). (By the way. this is only about which panic function is called; I'm pretty sure it does not improve anything about performance).
|
|
re-add Layout::for_value_raw
Tracking issue: #69835
This was accidentally removed in #70362 56cbf2f22aeb6448acd7eb49e9b2554c80bdbf79.
Originally added in #69079.
|
|
Miri: use extern fn to expose interpreter operations to program; fix leak checker on Windows
This PR realizes an idea that @oli-obk has been suggesting for a while: to use Miri-specific `extern` functions to provide some extra capabilities to the program. Initially, we have two of these methods, which libstd itself needs:
* `miri_start_panic`, which replaces the intrinsic of the same name (mostly for consistency, to avoid having multiple mechanisms for Miri-specific functionality).
* `miri_static_root`, which adds an allocation to a list of static "roots" that Miri considers as not having leaked (including all memory reachable through them). This is needed for https://github.com/rust-lang/miri/issues/1302.
We use `extern` functions instead of intrinsics for this so that user code can more easily call these Miri hoolks -- e.g. `miri_static_root` should be useful for https://github.com/rust-lang/miri/issues/1318.
The Miri side of this is at https://github.com/rust-lang/miri/pull/1485.
r? @oli-obk
|
|
Rearrange the pipeline of `pow` to gain efficiency
The check of the `exp` parameter seems useless if we execute the while-loop more than once.
The original implementation of `pow` function using one more comparison if the `exp==0` and may break the pipeline of the cpu, which may generate a slower code.
The performance gap between the old and the new implementation may be small, but IMO, at least the newer one looks more beautiful.
---
bench prog:
```
#![feature(test)]
extern crate test;
#[macro_export]macro_rules! timing{
($a:expr)=>{let time=std::time::Instant::now();{$a;}print!("{:?} ",time.elapsed())};
($a:expr,$b:literal)=>{let time=std::time::Instant::now();let mut a=0;for _ in 0..$b{a^=$a;}print!("{:?} {} ",time.elapsed(),a)}
}
#[inline]
pub fn pow_rust(x:i64, mut exp: u32) -> i64 {
let mut base = x;
let mut acc = 1;
while exp > 1 {
if (exp & 1) == 1 {
acc = acc * base;
}
exp /= 2;
base = base * base;
}
if exp == 1 {
acc = acc * base;
}
acc
}
#[inline]
pub fn pow_new(x:i64, mut exp: u32) -> i64 {
if exp==0{
1
}else{
let mut base = x;
let mut acc = 1;
while exp > 1 {
if (exp & 1) == 1 {
acc = acc * base;
}
exp >>= 1;
base = base * base;
}
acc * base
}
}
fn main(){
let a=2i64;
let b=1_u32;
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
}
```
bench in my laptop:
```
neutron@Neutron:/me/rust$ rc commit.rs
rustc commit.rs && ./commit
3.978419716s 0 4.079765171s 0 3.964630622s 0
3.997127013s 0 4.260304804s 0 3.997638211s 0
3.963195544s 0 4.11657718s 0 4.176054164s 0
3.830128579s 0 3.980396122s 0 3.937258567s 0
3.986055948s 0 4.127804162s 0 4.018943411s 0
4.185568857s 0 4.217512517s 0 3.98313603s 0
3.863018225s 0 4.030447988s 0 3.694878237s 0
4.206987927s 0 4.137608047s 0 4.115564664s 0
neutron@Neutron:/me/rust$ rc commit.rs -O
rustc commit.rs -O && ./commit
162.111993ms 0 165.107125ms 0 166.26924ms 0
175.20479ms 0 205.062565ms 0 176.278791ms 0
174.408975ms 0 166.526899ms 0 201.857604ms 0
146.190062ms 0 168.592821ms 0 154.61411ms 0
199.678912ms 0 168.411598ms 0 162.129996ms 0
147.420765ms 0 209.759326ms 0 154.807907ms 0
165.507134ms 0 188.476239ms 0 157.351524ms 0
121.320123ms 0 126.401229ms 0 114.86428ms 0
```
|
|
Add missing backticks in diagnostics note
|
|
Fix typo
|
|
|
|
|
|
|
|
libstd/libcore: fix various typos
|
|
The check of the `exp` parameter seems useless if we execute the while-loop more than once.
The original implementation of `pow` function using one more comparison if the `exp==0` and may break the pipeline of the cpu, which may generate a slower code.
The performance gap between the old and the new implementation may be small, but IMO, at least the newer one looks more beautiful.
---
bench prog:
```
extern crate test;
($a:expr)=>{let time=std::time::Instant::now();{$a;}print!("{:?} ",time.elapsed())};
($a:expr,$b:literal)=>{let time=std::time::Instant::now();let mut a=0;for _ in 0..$b{a^=$a;}print!("{:?} {} ",time.elapsed(),a)}
}
pub fn pow_rust(x:i64, mut exp: u32) -> i64 {
let mut base = x;
let mut acc = 1;
while exp > 1 {
if (exp & 1) == 1 {
acc = acc * base;
}
exp /= 2;
base = base * base;
}
if exp == 1 {
acc = acc * base;
}
acc
}
pub fn pow_new(x:i64, mut exp: u32) -> i64 {
if exp==0{
1
}else{
let mut base = x;
let mut acc = 1;
while exp > 1 {
if (exp & 1) == 1 {
acc = acc * base;
}
exp >>= 1;
base = base * base;
}
acc * base
}
}
fn main(){
let a=2i64;
let b=1_u32;
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
timing!(test::black_box(a).pow(test::black_box(b)),100000000);
timing!(pow_new(test::black_box(a),test::black_box(b)),100000000);
timing!(pow_rust(test::black_box(a),test::black_box(b)),100000000);
println!();
}
```
bench in my laptop:
```
neutron@Neutron:/me/rust$ rc commit.rs
rustc commit.rs && ./commit
3.978419716s 0 4.079765171s 0 3.964630622s 0
3.997127013s 0 4.260304804s 0 3.997638211s 0
3.963195544s 0 4.11657718s 0 4.176054164s 0
3.830128579s 0 3.980396122s 0 3.937258567s 0
3.986055948s 0 4.127804162s 0 4.018943411s 0
4.185568857s 0 4.217512517s 0 3.98313603s 0
3.863018225s 0 4.030447988s 0 3.694878237s 0
4.206987927s 0 4.137608047s 0 4.115564664s 0
neutron@Neutron:/me/rust$ rc commit.rs -O
rustc commit.rs -O && ./commit
162.111993ms 0 165.107125ms 0 166.26924ms 0
175.20479ms 0 205.062565ms 0 176.278791ms 0
174.408975ms 0 166.526899ms 0 201.857604ms 0
146.190062ms 0 168.592821ms 0 154.61411ms 0
199.678912ms 0 168.411598ms 0 162.129996ms 0
147.420765ms 0 209.759326ms 0 154.807907ms 0
165.507134ms 0 188.476239ms 0 157.351524ms 0
121.320123ms 0 126.401229ms 0 114.86428ms 0
```
delete an unnecessary semicolon...
Sorry for the typo.
delete trailing whitespace
Sorry, too..
Sorry for the missing...
I checked all the implementations, and finally found that there is one function that does not check whether `exp == 0`
add extra tests
add extra tests.
finished adding the extra tests to prevent further typo
add pow(2) to negative exp
add whitespace.
add whitespace
add whitespace
delete extra line
|
|
Apply #66379 to `*mut T` `as_ref`
#66379 changed the documentation of `as_ref` on the type `*const T` and `as_mut` on the type `*mut T`, but it missed making that same change for `as_ref` on the type `*mut T`.
|
|
|
|
Stabilize TAU constant.
Closes #66770.
|
|
Impl Default for ranges
Couldn't find an issue about it.
`Range` and friends probably can implement `Default` if `Idx: Default`. For example, the following would be possible:
```rust
#[derive(Default)]
struct Foo(core::ops::RangeToInclusive<u64>);
let _ = [1, 2, 3].get(core::ops::Range::default());
core::ops::RangeFrom::<u8>::default().take(20).for_each(|x| { dbg!(x); });
fn stuff<T: Default>() { let instance = T::default(); ... more stuff }
stuff::<core::ops::RangeTo<f32>>();
```
Maybe there are some concerns about safety or misunderstandings?
|
|
|
|
Closes #66770.
|
|
Use italics for O notation
In documentation, I think it makes sense to italicize O notation (*O(n)*) as opposed to using back-ticks (`O(n)`). Visually, back-ticks focus the reader on the literal characters being used, making them ideal for representing code. Using italics, as far I can tell, more closely follows typographic conventions in mathematics and computer science.
Just a suggestion, of course! 😇
|
|
Co-authored-by: Guillaume Gomez <guillaume1.gomez@gmail.com>
|
|
Improve documentation for `core::fmt` internals
The public interface of `core::fmt` is well-documented, but the internals have very minimal documentation.
|
|
|
|
Co-authored-by: Simon Sapin <simon.sapin@exyr.org>
|
|
|
|
Before, the `Range` method was called with `end = slice.len()`.
Unfortunately, because `Range::index` first checks the order of the
indices (start has to be smaller than end), an out of bounds index
leads to `core::slice::slice_index_order_fail` being called. This
prints the message 'slice index starts at 27 but ends at 10', which is
worse than 'index 27 out of range for slice of length 10'. This is not
only useful to normal users reading panic messages, but also for people
inspecting assembly and being confused by `slice_index_order_fail`
calls.
|
|
More intra-doc links, add explicit exception list to linkchecker
Fixes the broken links behind #32553
Progress on #32130 and #32129 except for a small number of links. Instead of whitelisting entire files, I've changed the code to whitelist specific links in specific files, and added a comment requesting people explain the reasons they add exceptions. I'm not sure if we should close those issues in favor of the already filed intra-doc link issues.
|
|
Generating the coverage map
@tmandry @wesleywiser
rustc now generates the coverage map and can support (limited)
coverage report generation, at the function level.
Example commands to generate a coverage report:
```shell
$ BUILD=$HOME/rust/build/x86_64-unknown-linux-gnu
$ $BUILD/stage1/bin/rustc -Zinstrument-coverage \
$HOME/rust/src/test/run-make-fulldeps/instrument-coverage/main.rs
$ LLVM_PROFILE_FILE="main.profraw" ./main
called
$ $BUILD/llvm/bin/llvm-profdata merge -sparse main.profraw -o main.profdata
$ $BUILD/llvm/bin/llvm-cov show --instr-profile=main.profdata main
```
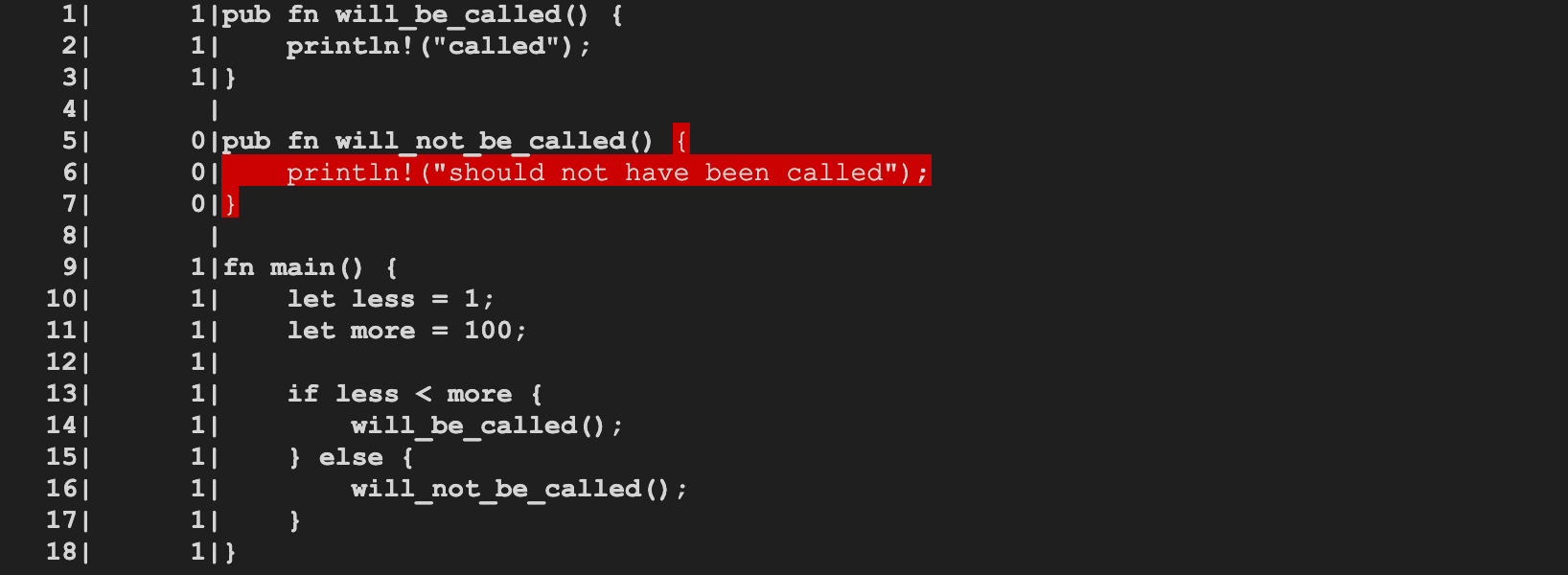
r? @wesleywiser
Rust compiler MCP rust-lang/compiler-team#278
Relevant issue: #34701 - Implement support for LLVMs code coverage instrumentation
|
|
Make unreachable_unchecked a const fn
This PR makes `std::hint::unreachable_unchecked` a const fn so we can use it inside a const function.
r? @RalfJung
Fixes #53188.
|
|
Add core::task::ready! macro
This PR adds `ready!` as a top-level macro to `libcore` following the implementation of `futures_core::ready`, tracking issue https://github.com/rust-lang/rust/issues/70922. This macro is commonly used when implementing `Future`, `AsyncRead`, `AsyncWrite` and `Stream`. And being only 5 lines, it seems like a useful and straight forward addition to std.
## Example
```rust
use core::task::{Context, Poll};
use core::future::Future;
use core::pin::Pin;
async fn get_num() -> usize {
42
}
pub fn do_poll(cx: &mut Context<'_>) -> Poll<()> {
let mut f = get_num();
let f = unsafe { Pin::new_unchecked(&mut f) };
let num = ready!(f.poll(cx));
// ... use num
Poll::Ready(())
}
```
## Naming
In `async-std` we chose to nest the macro under the `task` module instead of having the macro at the top-level. This is a pattern that currently does not occur in std, mostly due to this not being possible prior to Rust 2018.
This PR proposes to add the `ready` macro as `core::ready`. But another option would be to introduce it as `core::task::ready` since it's really only useful when used in conjunction with `task::{Context, Poll}`.
## Implementation questions
I tried rendering the documentation locally but the macro didn't show up under `core`. I'm not sure if I quite got this right. I used the [`todo!` macro PR](https://github.com/rust-lang/rust/pull/56348/files) as a reference, and our approaches look similar.
## References
- [`futures::ready`](https://docs.rs/futures/0.3.4/futures/macro.ready.html)
- [`async_std::task::ready`](https://docs.rs/async-std/1.5.0/async_std/task/index.html)
- [`futures_core::ready`](https://docs.rs/futures-core/0.3.4/futures_core/macro.ready.html)
|
|
This was accidentally removed in rust-lang/rust#70362
56cbf2f22aeb6448acd7eb49e9b2554c80bdbf79
|
|
|
|
Use intra-doc links in `str` and `BTreeSet`
Fixes #32129, fixes #32130
A _slight_ degradation in quality is that the `#method.foo` links would previously link to the same page on `String`'s documentation, and now they will navigate to `str`. Not a big deal IMO, and we can also try to improve that.
|
|
Fix `Safety` docs for `from_raw_parts_mut`
This aligns the wording more with the documentation of e.g. `drop_in_place`, `replace`, `swap` and `swap_nonoverlapping` from `core::ptr`.
Also if the pointer were really only valid for writes, it would be trivial to introduce UB from safe code, after calling `core::slice::from_raw_parts_mut`.
|
|
Add lazy initialization primitives to std
Follow-up to #68198
Current RFC: https://github.com/rust-lang/rfcs/pull/2788
Rebased and fixed up a few of the dangling comments. Some notes carried over from the previous PR:
- [ ] Naming. I'm ok to just roll with the `Sync` prefix like `SyncLazy` for now, but [have a personal preference for `Atomic`](https://github.com/rust-lang/rfcs/pull/2788#issuecomment-574466983) like `AtomicLazy`.
- [x] [Poisoning](https://github.com/rust-lang/rfcs/pull/2788#discussion_r366725768). It seems like there's [some regret around poisoning in other `std::sync` types that we might want to just avoid upfront for `std::lazy`, especially if that would align with a future `std::mutex` that doesn't poison](https://rust-lang.zulipchat.com/#narrow/stream/219381-t-libs/topic/parking_lot.3A.3AMutex.20in.20std/near/190331199). Personally, if we're adding these types to `std::lazy` instead of `std::sync`, I'd be on-board with not worrying about poisoning in `std::lazy`, and potentially deprecating `std::sync::Once` and `lazy_static` in favour of `std::lazy` down the track if it's possible, rather than attempting to replicate their behavior. cc @Amanieu @sfackler.
- [ ] [Consider making`SyncOnceCell::get` blocking](https://github.com/matklad/once_cell/pull/92). There doesn't seem to be consensus in the linked PR on whether or not that's strictly better than the non-blocking variant.
In general, none of these seem to be really blocking an initial unstable merge, so we could possibly kick off a FCP if y'all are happy?
cc @matklad @pitdicker have I missed anything, or were there any other considerations that have come up since we last looked at this?
|
|
|
|
|
|
docs: better demonstrate that None values are skipped as many times a…
…s needed
|
|
Use intra-doc links in core::iter module
This will make core::iter doc depend less on std doc.
|
|
r=Amanieu
Add Arguments::as_str().
There exist quite a few macros in the Rust ecosystem which use `format_args!()` for formatting, but special case the one-argument case for optimization:
```rust
#[macro_export]
macro_rules! some_macro {
($s:expr) => { /* print &str directly, no formatting, no buffers */ };
($s:expr, $($tt:tt)*) => { /* use format_args to write to a buffer first */ }
}
```
E.g. [here](https://github.com/rust-embedded/cortex-m-semihosting/blob/7a961f0fbe6eb1b29a7ebde4bad4b9cf5f842b31/src/macros.rs#L48-L58), [here](https://github.com/rust-lang-nursery/failure/blob/20f9a9e223b7cd71aed541d050cc73a747fc00c4/src/macros.rs#L9-L17), and [here](https://github.com/fusion-engineering/px4-rust/blob/7b679cd6da9ffd95f36f6526d88345f8b36121da/px4/src/logging.rs#L45-L52).
The problem with these is that a forgotten argument such as in `some_macro!("{}")` will not be diagnosed, but just prints `"{}"`.
With this PR, it is possible to handle the no-arguments case separately *after* `format_args!()`, while simplifying the macro. Then these macros can give the proper error about a missing argument, just like `print!("{}")` does, while still using the same optimized implementation as before.
This is even more important with [RFC 2795](https://github.com/rust-lang/rfcs/pull/2795), to make sure `some_macro!("{some_variable}")` works as expected.
|
|
Make some Option methods const
Tracking issue: #67441
Constantify the following methods of `Option`:
- `as_ref`
- `is_some`
- `is_none`
- `iter` (not sure about this one, but it is possible, and will be useful when const traits are a thing)
cc @rust-lang/wg-const-eval @rust-lang/libs
|
|
|
|
rustc now generates the coverage map and can support (limited)
coverage report generation, at the function level.
Example:
$ BUILD=$HOME/rust/build/x86_64-unknown-linux-gnu
$ $BUILD/stage1/bin/rustc -Zinstrument-coverage \
$HOME/rust/src/test/run-make-fulldeps/instrument-coverage/main.rs
$ LLVM_PROFILE_FILE="main.profraw" ./main
called
$ $BUILD/llvm/bin/llvm-profdata merge -sparse main.profraw -o main.profdata
$ $BUILD/llvm/bin/llvm-cov show --instr-profile=main.profdata main
1| 1|pub fn will_be_called() {
2| 1| println!("called");
3| 1|}
4| |
5| 0|pub fn will_not_be_called() {
6| 0| println!("should not have been called");
7| 0|}
8| |
9| 1|fn main() {
10| 1| let less = 1;
11| 1| let more = 100;
12| 1|
13| 1| if less < more {
14| 1| will_be_called();
15| 1| } else {
16| 1| will_not_be_called();
17| 1| }
18| 1|}
|
|
|
|
|
|
|
|
|
