| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:
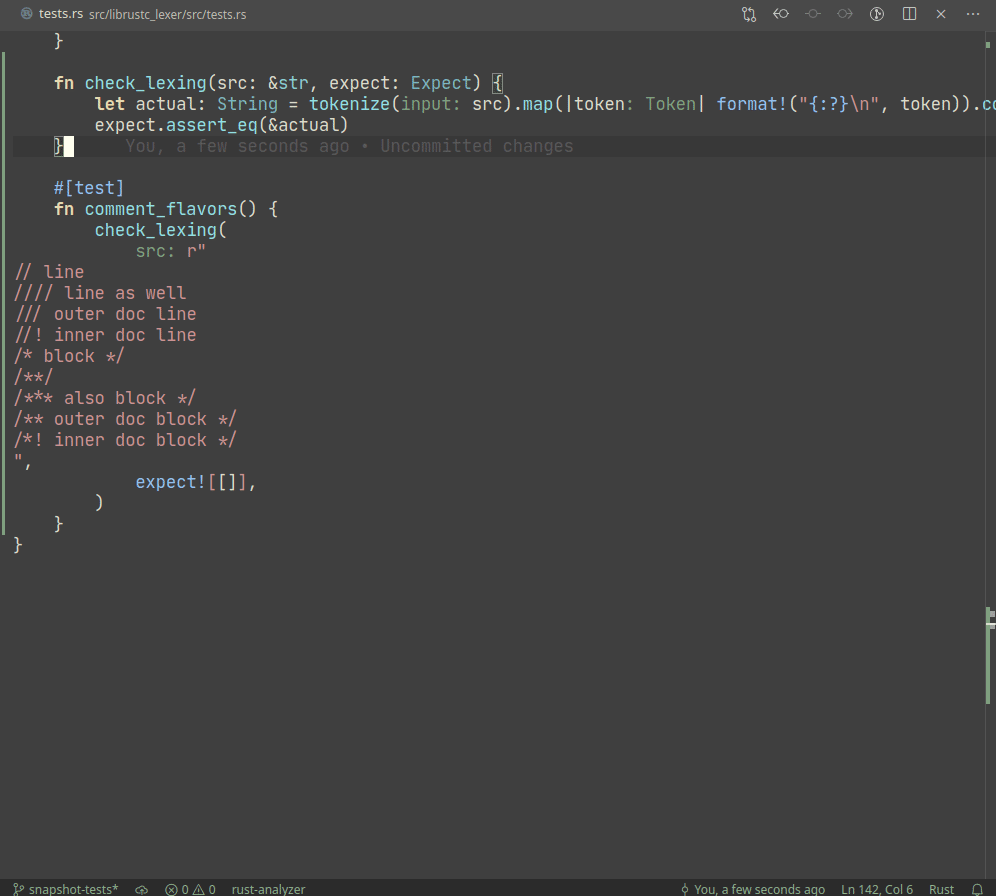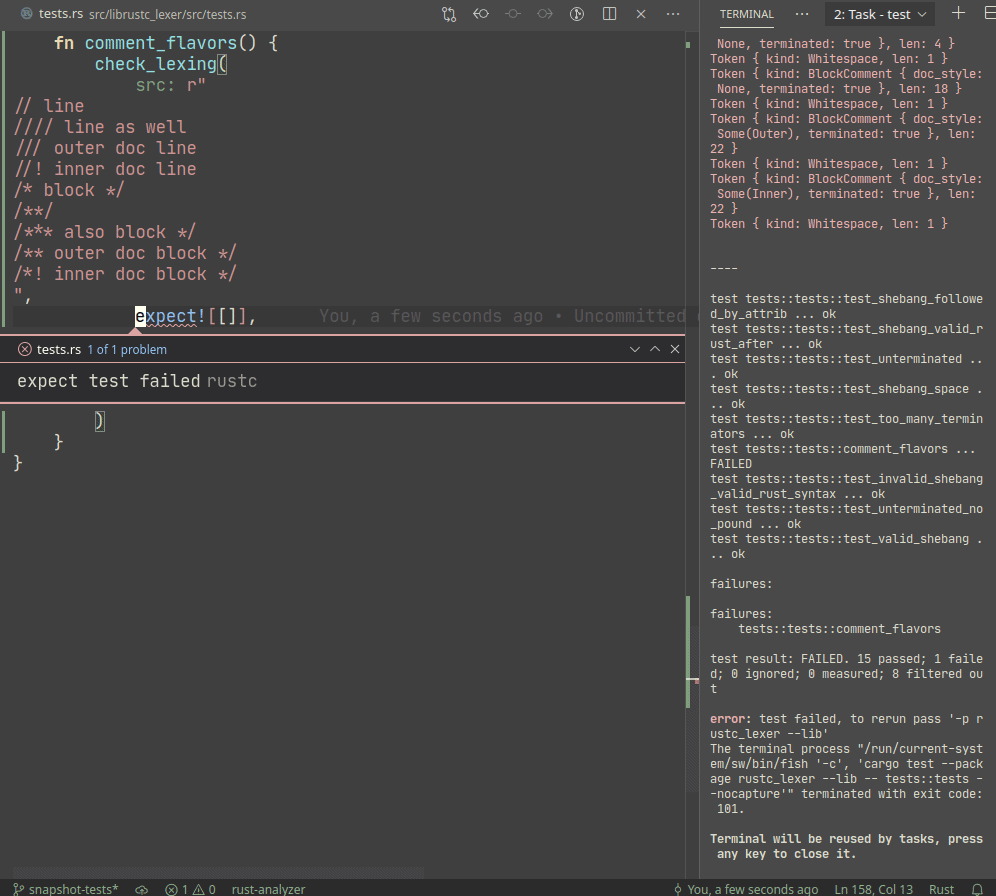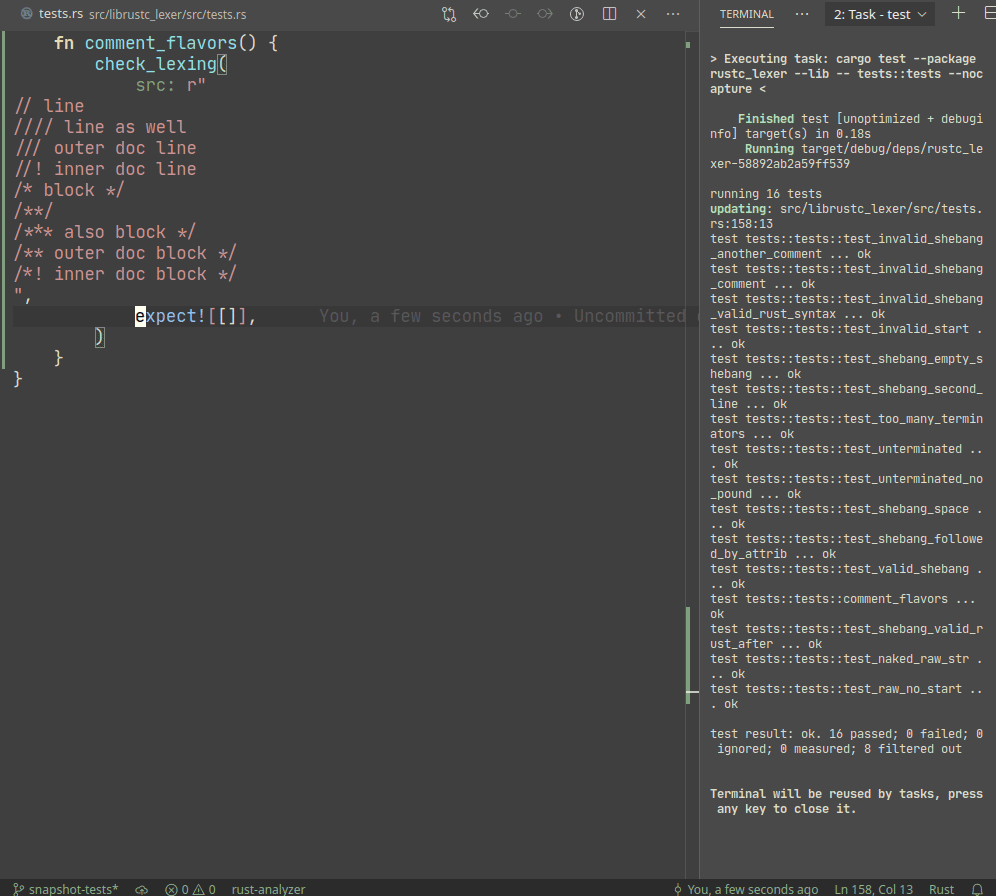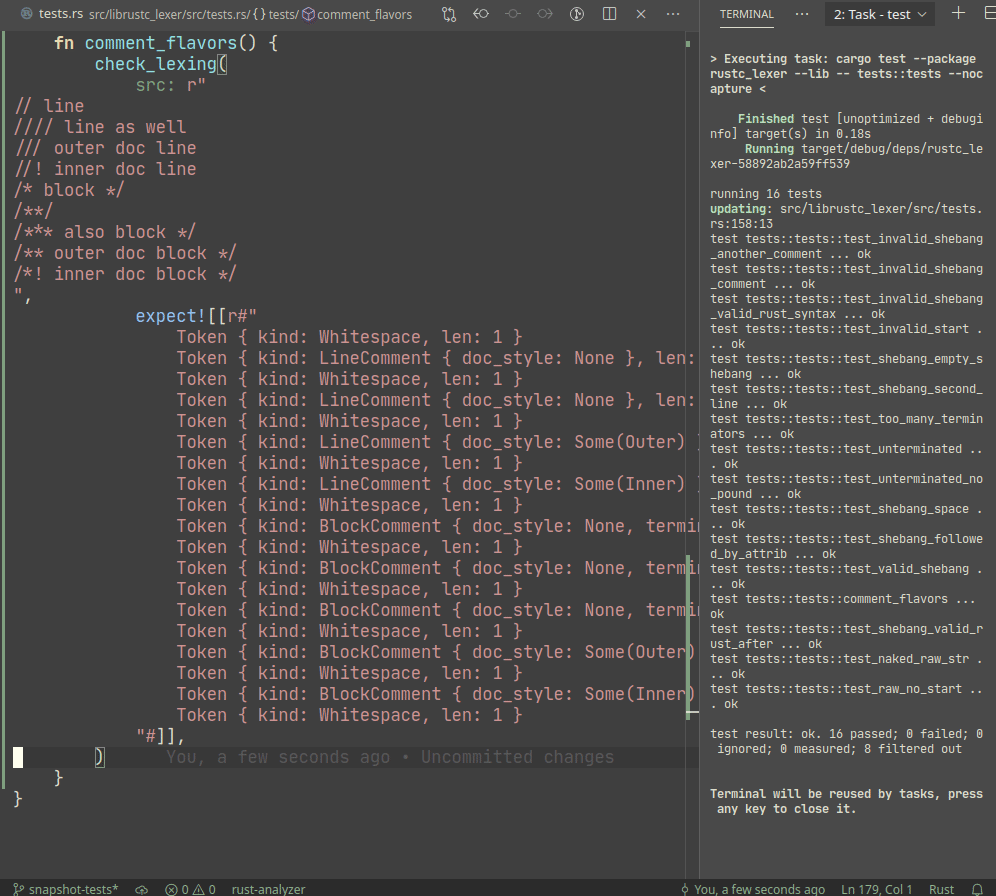
A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See https://github.com/rust-analyzer/rust-analyzer/pull/5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
|
|
|
|
Move doc comment parsing to rustc_lexer
Plain comments are trivia, while doc comments are not, so it feels
like this belongs to the rustc_lexer.
The specific reason to do this is the desire to use rustc_lexer in
rustdoc for syntax highlighting, without duplicating "is this a doc
comment?" logic there.
r? @ghost
|
|
All other tokens are named by the punctuation they use, rather than
by semantics operation they stand for. `!` is the only exception to
the rule, let's fix it.
|
|
Plain comments are trivial, while doc comments are not, so it feels
like this belongs to the rustc_lexer.
The specific reason to do this is the desire to use rustc_lexer in
rustdoc for syntax highlighting, without duplicating "is this a doc
comment?" logic there.
|
|
|
|
Edit librustc_lexer top-level docs
Minor edit, and adds link to librustc_parse::lexer.
|
|
Add link to librustc_parse::lexer
|
|
Fix markdown rendering in librustc_lexer docs
Use back-ticks instead of quotation marks in docs for the block comment variant of TokenKind.
## [Before](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_lexer/enum.TokenKind.html#variant.BlockComment) and after
<img width="1103" alt="Screen Shot 2020-06-28 at 1 22 30 PM" src="https://user-images.githubusercontent.com/19642016/85957562-446a8380-b943-11ea-913a-442cf7744083.png">
<img width="1015" alt="Screen Shot 2020-06-28 at 1 28 29 PM" src="https://user-images.githubusercontent.com/19642016/85957566-4af8fb00-b943-11ea-8fef-a09c1d586772.png">
## Question
For visual consistency, should we use back-ticks throughout the docs for these enum variants?
|
|
Fix missing punctuation
|
|
Use back-ticks instead of quotation marks in docs for the block comment
variant of TokenKind.
|
|
|
|
Migrate to numeric associated consts
The deprecation PR is #72885
cc #68490
cc rust-lang/rfcs#2700
|
|
|
|
Fixes more of:
clippy::unused_unit
clippy::op_ref
clippy::useless_format
clippy::needless_return
clippy::useless_conversion
clippy::bind_instead_of_map
clippy::into_iter_on_ref
clippy::redundant_clone
clippy::nonminimal_bool
clippy::redundant_closure
clippy::option_as_ref_deref
clippy::len_zero
clippy::iter_cloned_collect
clippy::filter_next
|
|
This makes `UnvalidatedRawStr` and `ValidatedRawStr` unnecessary and removes 70 lines.
|
|
|
|
Shebang handling was too agressive in stripping out the first line in cases where it is actually _not_ a shebang, but instead, valid rust (#70528). This is a second attempt at resolving this issue (the first attempt was flawed, for, among other reasons, causing an ICE in certain cases (#71372, #71471).
The behavior is now codified by a number of UI tests, but simply:
For the first line to be a shebang, the following must all be true:
1. The line must start with `#!`
2. The line must contain a non whitespace character after `#!`
3. The next character in the file, ignoring comments & whitespace must not be `[`
I believe this is a strict superset of what we used to allow, so perhaps a crater run is unnecessary, but probably not a terrible idea.
|
|
|
|
into one method `unescape_literal` with a mode argument.
|
|
The phrasing is from the commit description of 395ee0b79f23b90593b01dd0a78451b8c93b0aa6 by @Matklad.
|
|
This reverts commit 46a8dcef5c9e4de0d412c6ac3c4765cb4aef4f7f, reversing
changes made to f28e3873c55eb4bdcfc496e1f300b97aeb0d189c.
|
|
|
|
|
|
|
|
|
|
The modified code to handle parsing raw strings didn't properly account for the case where there was no "#" on either end and erroneously reported this strings as complete. This lead to a panic trying to read off the end of the file.
|
|
|
|
|
|
|
|
This diff improves error messages around raw strings in a few ways:
- Catch extra trailing `#` in the parser. This can't be handled in the lexer because we could be in a macro that actually expects another # (see test)
- Refactor & unify error handling in the lexer between ByteStrings and RawByteStrings
- Detect potentially intended terminators (longest sequence of "#*" is suggested)
|
|
|
|
|
|
|
|
|
|
also move MACRO_ARGUMENTS -> librustc_parse
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Apply review suggestions
Apply review suggestions
|
|
We publish this to crates.io, so having non-empty meta is useful
|
|
On the call site, `rustc_lexer::is_whitespace` reads much better than
`character_properties::is_whitespace`.
|
|
They are only used by rustc_lexer, and are not needed elsewhere.
So we move the relevant definitions into rustc_lexer (while the actual
unicode data comes from the unicode-xid crate) and make the rest of
the compiler use it.
|
