| Age | Commit message (Collapse) | Author | Lines |
|---|
|
rustdoc-search: stringdex update with more packing
Before:
18M build/x86_64-unknown-linux-gnu/doc/search.index/
57M build/x86_64-unknown-linux-gnu/compiler-doc/search.index/
After:
16M build/x86_64-unknown-linux-gnu/doc/search.index/
49M build/x86_64-unknown-linux-gnu/compiler-doc/search.index/
CC rust-lang/rust#146063
|
|
|
|
Before:
18M build/x86_64-unknown-linux-gnu/doc/search.index/
57M build/x86_64-unknown-linux-gnu/compiler-doc/search.index/
After:
16M build/x86_64-unknown-linux-gnu/doc/search.index/
49M build/x86_64-unknown-linux-gnu/compiler-doc/search.index/
|
|
This one's uses a different tactic. It shouldn't significantly
increase the amount of downloaded index data, but still reduces
the amount of disk usage.
This one works by changing the suffix-only node representation
to omit some data that's needed for checking. Since those nodes
make up the bulk of the tree, it reduces the data they store,
but also requires validating the match by fetching the name
itself (but the names list is pretty small, and when I tried
it with wordnet "indexing" it was about the same).
|
|
|
|
|
|
|
|
Follow up https://github.com/rust-lang/rust/pull/127127
|
|
|
|
|
|
|
|
|
|
Update minifier version to `0.3.4`
It fixes a bug where a whitespace would get removed in `a [attribute]` (you're not forced to add a tag before an attribute selector).
r? ````@notriddle````
|
|
|
|
This way, adding a bunch of comments to the JS files won't make
rustdoc slower.
|
|
|
|
Since sha256 is slow enough to show up on small benchmarks,
we can save time by embedding the hash in the executable.
|
|
|
|
|
|
|
|
This is an alternative to ee6459d6521cf6a4c2e08b6e13ce3c6ce5d55ed0.
That is, it fixes the issue that affects the very long type names
in https://docs.rs/async-stripe/0.31.0/stripe/index.html#structs.
This is, necessarily, a pile of nasty heuristics.
We need to balance a few issues:
- Sometimes, there's no real word break.
For example, `BTreeMap` should be `BTree<wbr>Map`,
not `B<wbr>Tree<wbr>Map`.
- Sometimes, there's a legit word break,
but the name is tiny and the HTML overhead isn't worth it.
For example, if we're typesetting `TyCtx`,
writing `Ty<wbr>Ctx` would have an HTML overhead of 50%.
Line breaking inside it makes no sense.
|
|
|
|
|
|
The functionality of all three crates is now available in the standard library.
|
|
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
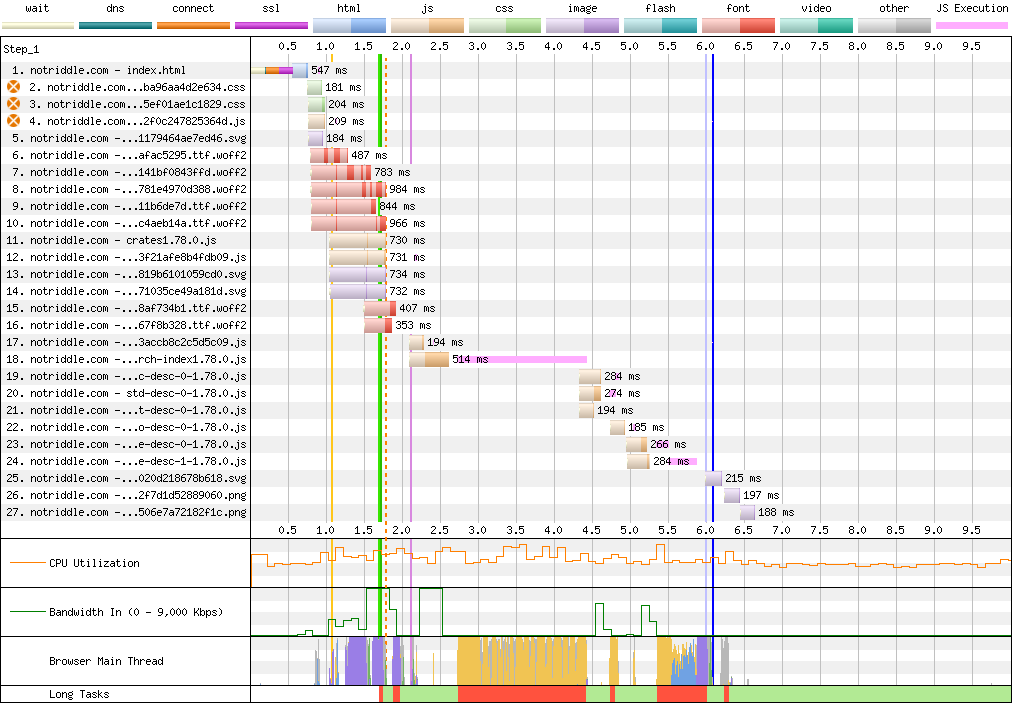
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
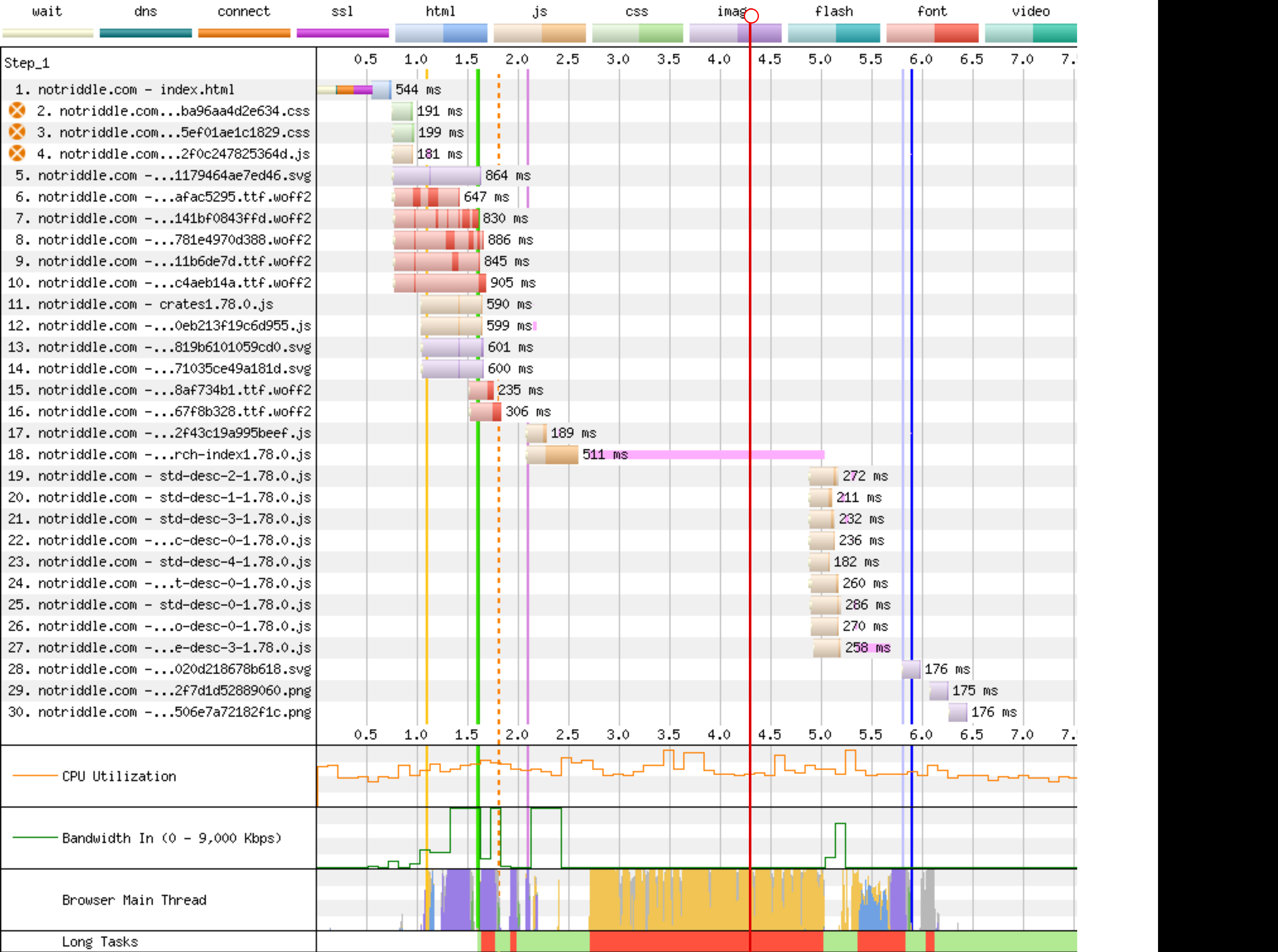
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
|
|
Only change is https://github.com/davidbarsky/tracing-tree/pull/76
dedupes tracing-log
dupes nu-ansi-term
|
|
This adds a bit more data than "pure sharding" by
including information about which items have no description
at all. This way, it can sort the results, then truncate,
then finally download the description.
With the "e" bitmap: 2380KiB
Without the "e" bitmap: 2364KiB
|
|
still depend on 0.11:
* clippy
* rustfmt, sigh
|
|
Because the API for `with_position` improved in 0.11 and I want to use
it.
|
|
|
|
This is an attempt to balance three problems, each of which would
be violated by a simpler implementation:
- A type alias should show all the `impl` blocks for the target
type, and vice versa, if they're applicable. If nothing was
done, and rustdoc continues to match them up in HIR, this
would not work.
- Copying the target type's docs into its aliases' HTML pages
directly causes far too much redundant HTML text to be generated
when a crate has large numbers of methods and large numbers
of type aliases.
- Using JavaScript exclusively for type alias impl docs would
be a functional regression, and could make some docs very hard
to find for non-JS readers.
- Making sure that only applicable docs are show in the
resulting page requires a type checkers. Do not reimplement
the type checker in JavaScript.
So, to make it work, rustdoc stashes these type-alias-inlined docs
in a JSONP "database-lite". The file is generated in `write_shared.rs`,
included in a `<script>` tag added in `print_item.rs`, and `main.js`
takes care of patching the additional docs into the DOM.
The format of `trait.impl` and `type.impl` JS files are superficially
similar. Each line, except the JSONP wrapper itself, belongs to a crate,
and they are otherwise separate (rustdoc should be idempotent). The
"meat" of the file is HTML strings, so the frontend code is very simple.
Links are relative to the doc root, though, so the frontend needs to fix
that up, and inlined docs can reuse these files.
However, there are a few differences, caused by the sophisticated
features that type aliases have. Consider this crate graph:
```text
---------------------------------
| crate A: struct Foo<T> |
| type Bar = Foo<i32> |
| impl X for Foo<i8> |
| impl Y for Foo<i32> |
---------------------------------
|
----------------------------------
| crate B: type Baz = A::Foo<i8> |
| type Xyy = A::Foo<i8> |
| impl Z for Xyy |
----------------------------------
```
The type.impl/A/struct.Foo.js JS file has a structure kinda like this:
```js
JSONP({
"A": [["impl Y for Foo<i32>", "Y", "A::Bar"]],
"B": [["impl X for Foo<i8>", "X", "B::Baz", "B::Xyy"], ["impl Z for Xyy", "Z", "B::Baz"]],
});
```
When the type.impl file is loaded, only the current crate's docs are
actually used. The main reason to bundle them together is that there's
enough duplication in them for DEFLATE to remove the redundancy.
The contents of a crate are a list of impl blocks, themselves
represented as lists. The first item in the sublist is the HTML block,
the second item is the name of the trait (which goes in the sidebar),
and all others are the names of type aliases that successfully match.
This way:
- There's no need to generate these files for types that have no aliases
in the current crate. If a dependent crate makes a type alias, it'll
take care of generating its own docs.
- There's no need to reimplement parts of the type checker in
JavaScript. The Rust backend does the checking, and includes its
results in the file.
- Docs defined directly on the type alias are dropped directly in the
HTML by `render_assoc_items`, and are accessible without JavaScript.
The JSONP file will not list impl items that are known to be part
of the main HTML file already.
[JSONP]: https://en.wikipedia.org/wiki/JSONP
|
|
|
|
|
|
|
|
This commit changes the sequence parsers to produce `ThinVec`, which
triggers numerous conversions.
|
|
Because 0.2.10 added supports for `ThinVec::splice`, and 0.2.12 is the
latest release.
|
|
This commit implements MCP https://github.com/rust-lang/compiler-team/issues/584
It also removes code that is no longer used, and that includes code cloning resolver, so issue #83761 is fixed.
|
|
|
|
Use `IsTerminal` in place of `atty`
In any crate that can use nightly features, use `IsTerminal` rather than
`atty`:
- Use `IsTerminal` in `rustc_errors`
- Use `IsTerminal` in `rustc_driver`
- Use `IsTerminal` in `rustc_log`
- Use `IsTerminal` in `librustdoc`
|
|
|
|
|
|
`rustc_data_structures::thin_vec::ThinVec` looks like this:
```
pub struct ThinVec<T>(Option<Box<Vec<T>>>);
```
It's just a zero word if the vector is empty, but requires two
allocations if it is non-empty. So it's only usable in cases where the
vector is empty most of the time.
This commit removes it in favour of `thin_vec::ThinVec`, which is also
word-sized, but stores the length and capacity in the same allocation as
the elements. It's good in a wider variety of situation, e.g. in enum
variants where the vector is usually/always non-empty.
The commit also:
- Sorts some `Cargo.toml` dependency lists, to make additions easier.
- Sorts some `use` item lists, to make additions easier.
- Changes `clean_trait_ref_with_bindings` to take a
`ThinVec<TypeBinding>` rather than a `&[TypeBinding]`, because this
avoid some unnecessary allocations.
|
|
|
|
|
|
This pulls in https://github.com/servo/rust-smallvec/pull/282, which
gives some small wins for rustc.
|
|
|
|
|
|
|
|
|
|
|
