| Age | Commit message (Collapse) | Author | Lines |
|---|
|
The old name wasn't very clear, while the new one makes it clear that
this is the code responsible for creating the search index.
|
|
|
|
Rationale:
* The name was confusing.
* It was only used in one place.
* That place didn't actually need all the functionality of `get_type`;
rather, removing `get_type` makes that code clearer.
|
|
At last! The new name is shorter, simpler, and consistent with
`hir::Ty`.
|
|
I would like to rename it to `Type::Path`, but then it can't be
re-exported since the name would conflict with the `Path` struct.
Usually enum variants are referred to using their qualified names in
Rust (and parts of rustdoc already do that with `clean::Type`), so this
is also more consistent with the language.
|
|
|
|
|
|
Remove unneeded FIXMEs comments in search index generation
Original comment:
> Instead of recreating a new `vec` for each arguments, we re-use the same. The impact on performance should be minor but worth a try.
After testing it, we reached the conclusion that the code readability drop wasn't worth the almost unnoticeable performance improvement.
r? `@camelid`
|
|
Rollup of 3 pull requests
Successful merges:
- #90771 (Fix trait object error code)
- #90840 (relate lifetime in `TypeOutlives` bounds on drop impls)
- #90853 (rustdoc: Use an empty Vec instead of Option<Vec>)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
|
|
rustdoc: use Type::def_id() instead of Type::def_id_no_primitives()
For: #90187
r? `@jyn514`
|
|
|
|
Add more comments to explain the code to generate the search index
Fixes #90766.
I tried to put comments when the code wasn't easy to understand at first sight and added more documentation on the recursive function. Please tell me if I misused the terminology or if comments can be improved or added into other places.
r? `@notriddle`
|
|
|
|
conclusion that the code readibility wasn't worth the almost unnoticeable perf improvement
|
|
|
|
Signed-off-by: Muhammad Falak R Wani <falakreyaz@gmail.com>
|
|
|
|
Signed-off-by: Muhammad Falak R Wani <falakreyaz@gmail.com>
|
|
rustdoc: Compute some fields of `clean::Crate` on-demand to reduce size
`clean::Crate` is frequently moved by-value -- for example, in `DocFolder`
implementations -- so reducing its size should improve performance.
This PR reduces the size of `clean::Crate` from 168 bytes to 104 bytes.
r? `@jyn514`
|
|
It is not as large as `Crate.src` was, but it's still 8 bytes, and
`clean::Crate` is moved by-value a lot.
|
|
|
|
rustdoc: Remove `GetDefId`
See the individual commit messages for details.
r? `@jyn514`
|
|
|
|
The old name was confusing because it's easy to assume that using
`def_id()` is fine, but in some situations it's incorrect. In general,
`def_id_full()` should be preferred, so `def_id_full()` should have a
shorter name. That will happen in the next commit.
|
|
Now that it's only implemented for `Type`, using inherent methods
instead means that imports are no longer necessary. Also, `GetDefId` is
only meant to be used with `Type`, so it shouldn't be a trait.
|
|
|
|
The change to `impl Clean<Path> for hir::TraitRef<'_>` was necessary to
fix a test failure for `src/test/rustdoc/trait-alias-mention.rs`.
Here's why:
The old code path was through `impl Clean<Type> for hir::TraitRef<'_>`,
which called `resolve_type`, which in turn called `register_res`. Now,
because `PolyTrait` uses a `Path` instead of a `Type`, the impl of
`Clean<Path>` was being run, which did not call `register_res`, causing
the trait alias to not be recorded in the `external_paths` cache.
|
|
|
|
(clippy::useless_conversion)
Example:
let _x: String = String::from("hello world").into();
|
|
This commit adds a test case for generics, re-adds generics data
to the search index, and tweaks function indexing to use less space in JSON.
This reverts commit 14ca89446c076bcf484d3d05bd991a4b7985a409.
|
|
Properly render HRTBs
```rust
pub fn test<T>()
where
for<'a> &'a T: Iterator,
{}
```
This will now render properly including the `for<'a>`

I do not know if this covers all cases, it only covers everything that I could think of that includes `for` and lifetimes in where bounds.
Also someone need to mentor me on how to add a proper rustdoc test for this.
Resolves #78482
|
|
Commit e629381653bb3579f0cea0b256e391edef5e8dbb removes the only place
these members variables are actually read.
|
|
objects
|
|
Before:

After:
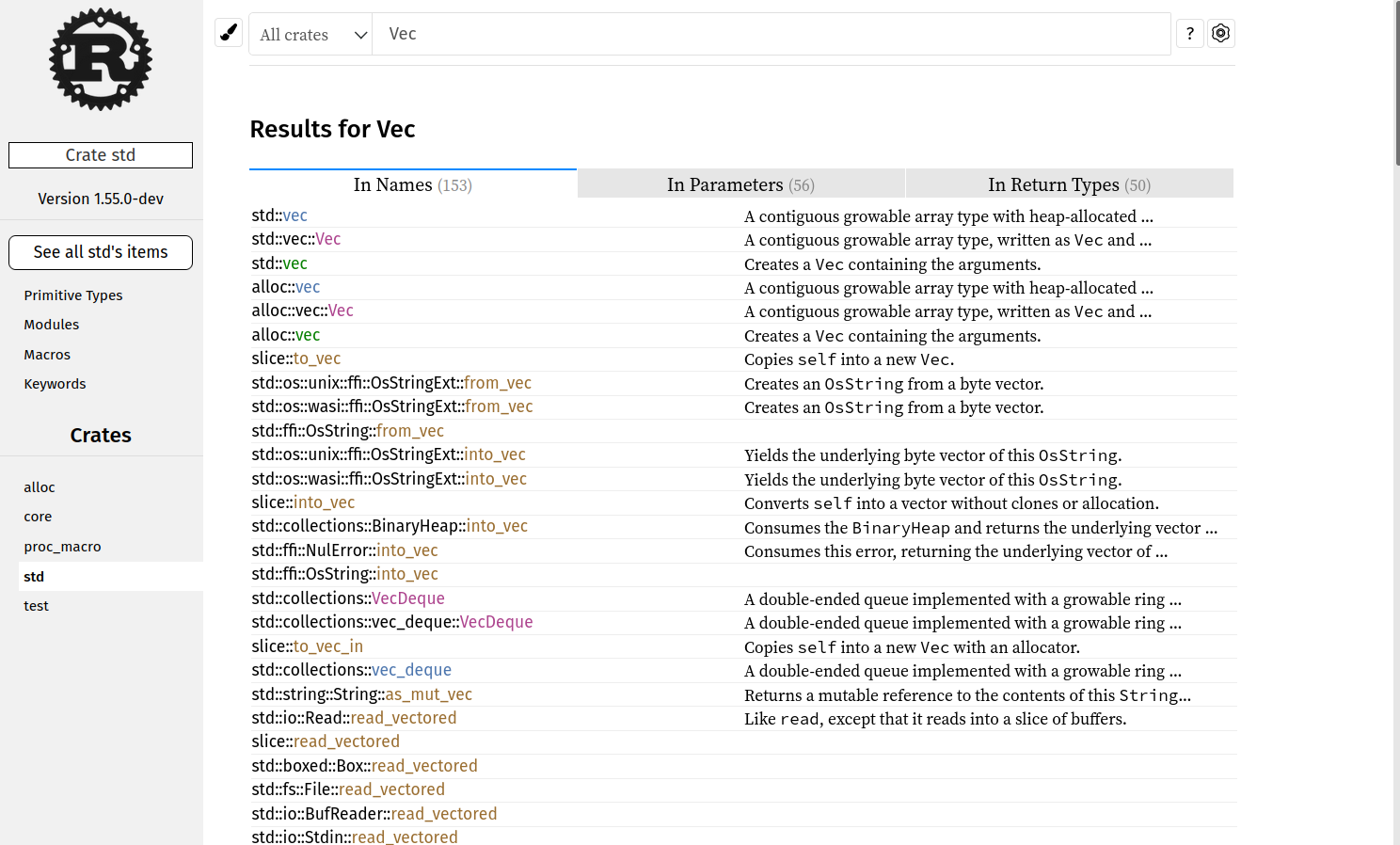
|
|
|
|
|
|
extern_location function
|
|
check item.is_fake() instead of self_id.is_some()
Remove empty branching in Attributes::from_ast
diverse small refacto after Josha review
cfg computation moved in merge_attrs
refacto use from_ast twice for coherence
take cfg out of Attributes and move it to Item
|
|
the fields in Attributes, as functions in AttributesExt.
refacto use from_def_id_and_attrs_and_parts instead of an old trick
most of josha suggestions + check if def_id is not fake before using it in a query
Removed usage of Attributes in FnDecl and ExternalCrate. Relocate part of the Attributes fields as functions in AttributesExt.
|
|
|
|
|
|
|
|
This should not affect the appearance of the docs pages themselves.
This makes the pre-compressed search index smaller, thanks to the
empty-string path duplication format, and also the gzipped version,
by giving the algorithm more structure to work with.
rust$ wc -c search-index-old.js search-index-new.js
2628334 search-index-old.js
2586181 search-index-new.js
5214515 total
rust$ gzip search-index-*
rust$ wc -c search-index-old.js.gz search-index-new.js.gz
239486 search-index-old.js.gz
237386 search-index-new.js.gz
476872 total
|
|
I'm wondering if it was originally there so that we could `take` the
module which enables `after_krate` to take an `&Crate`. However, the two
impls of `after_krate` only use `Crate.name`, so we can pass just the
name instead.
|
|
This essentially switches search-index.js from a "array of struct"
to a "struct of array" format, like this:
{
"doc": "Crate documentation",
"t": [ 1, 1, 2, 3, ... ],
"n": [ "Something", "SomethingElse", "whatever", "do_stuff", ... ],
"q": [ "a::b", "", "", "", ... ],
"d": [ "A Struct That Does Something", "Another Struct", "a function", "another function", ... ],
"i": [ 0, 0, 1, 1, ... ],
"f": [ null, null, [], [], ... ],
"p": ...,
"a": ...
}
So `{ty: 1, name: "Something", path: "a::b", desc: "A Struct That Does Something", parent_idx: 0, search_type: null}` is the first item.
This makes the uncompressed version smaller, but it really shows on the
compressed version:
notriddle:rust$ wc -c new-search-index1.52.0.js
2622427 new-search-index1.52.0.js
notriddle:rust$ wc -c old-search-index1.52.0.js
2725046 old-search-index1.52.0.js
notriddle:rust$ gzip new-search-index1.52.0.js
notriddle:rust$ gzip old-search-index1.52.0.js
notriddle:rust$ wc -c new-search-index1.52.0.js.gz
239385 new-search-index1.52.0.js.gz
notriddle:rust$ wc -c old-search-index1.52.0.js.gz
296328 old-search-index1.52.0.js.gz
notriddle:rust$
That's a 4% improvement on the uncompressed version (fewer `[]`),
and 20% improvement after gzipping it, thanks to putting like-typed
data next to each other. Any compression algorithm based on a sliding
window will probably show this kind of improvement.
|
|
|
|
|
|
|
|
|
|
r=poliorcetics,CraftSpider
Bind all clean::Type variants and remove FIXME
This is simply a little cleanup.
cc `@CraftSpider`
r? `@poliorcetics`
|
