| Age | Commit message (Collapse) | Author | Lines |
|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(clippy::single_match)
Makes code more compact and reduces nestig.
|
|
|
|
|
|
|
|
|
|
Mark other variants as uninitialized after switch on discriminant
During drop elaboration, which builds the drop ladder that handles destruction during stack unwinding, we attempt to remove MIR `Drop` terminators that will never be reached in practice. This reduces the number of basic blocks that are passed to LLVM, which should improve performance. In #66753, a user pointed out that unreachable `Drop` terminators are common in functions like `Option::unwrap`, which move out of an `enum`. While discussing possible remedies for that issue, @eddyb suggested moving const-checking after drop elaboration. This would allow the former, which looks for `Drop` terminators and replicates a small amount of drop elaboration to determine whether a dropped local has been moved out, leverage the work done by the latter.
However, it turns out that drop elaboration is not as precise as it could be when it comes to eliminating useless drop terminators. For example, let's look at the code for `unwrap_or`.
```rust
fn unwrap_or<T>(opt: Option<T>, default: T) -> T {
match opt {
Some(inner) => inner,
None => default,
}
}
```
`opt` never needs to be dropped, since it is either moved out of (if it is `Some`) or has no drop glue (if it is `None`), and `default` only needs to be dropped if `opt` is `Some`. This is not reflected in the MIR we currently pass to codegen.
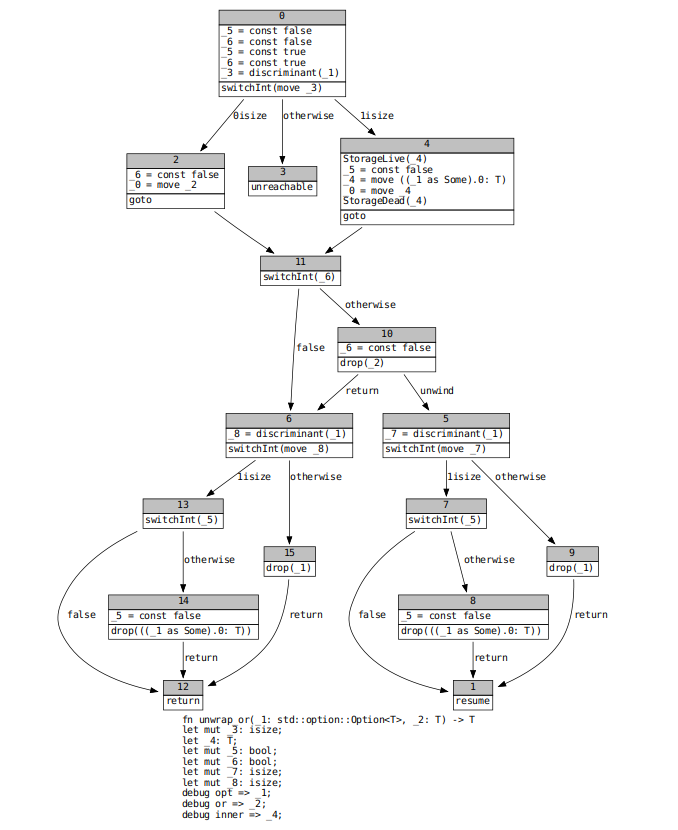
@eddyb also suggested the solution to this problem. When we switch on an enum discriminant, we should be marking all fields in other variants as definitely uninitialized. I implemented this on top of alongside a small optimization (split out into #68943) that suppresses drop terminators for enum variants with no fields (e.g. `Option::None`). This is the resulting MIR for `unwrap_or`.
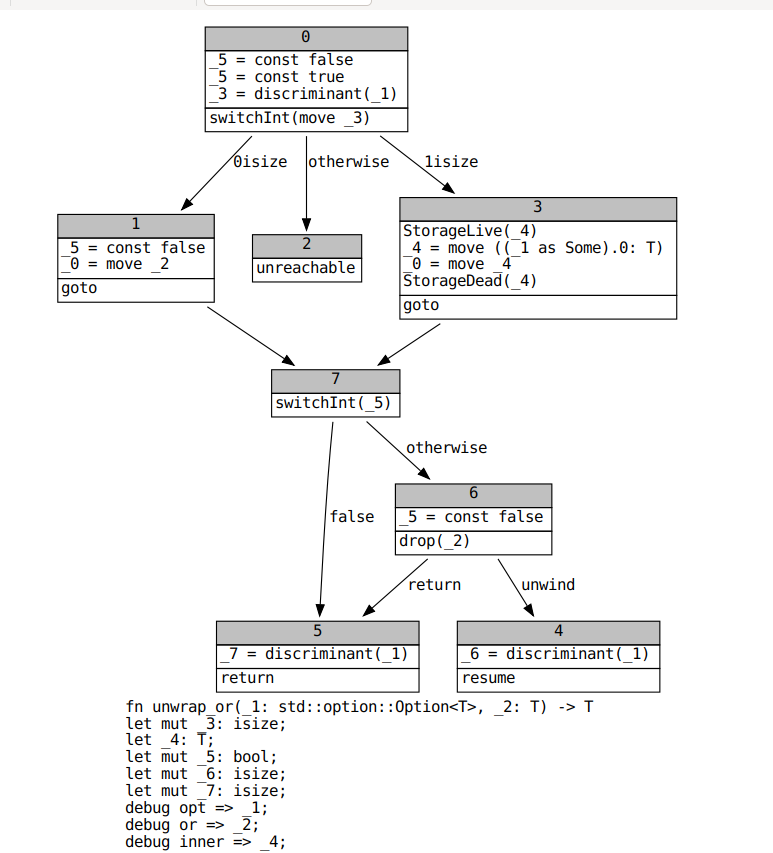
In concert with #68943, this change speeds up many [optimized and debug builds](https://perf.rust-lang.org/compare.html?start=d55f3e9f1da631c636b54a7c22c1caccbe4bf0db&end=0077a7aa11ebc2462851676f9f464d5221b17d6a). We need to carefully investigate whether I have introduced any miscompilations before merging this. Code that never drops anything would be very fast indeed until memory is exhausted.
|
|
|
|
`MaybeMutBorrowedLocals` serves the same purpose and has a better name.
|
|
|
|
|
|
rename all body_cache back to body
|
|
|
|
|
|
This adds a dataflow analysis that determines if a reference to a given
`Local` or part of a `Local` that would allow mutation exists before a
point in the CFG. If no such reference exists, we know for sure that
that `Local` cannot have been mutated via an indirect assignment or
function call.
|
|
|
|
|
|
Since the value of `InitialFlow` defines the semantics of the `join`
operation, there's no reason to have seperate traits for each. We can
add a default impl of `join` which branches based on `BOTTOM_VALUE`.
This should get optimized away.
|
|
This commit makes `sets.on_entry` inaccessible in
`{before_,}{statement,terminator}_effect`. This field was meant to allow
implementors of `BitDenotation` to access the initial state for each
block (optionally with the effect of all previous statements applied via
`accumulates_intrablock_state`) while defining transfer functions.
However, the ability to set the initial value for the entry set of each
basic block (except for START_BLOCK) no longer exists. As a result, this
functionality is mostly useless, and when it *was* used it was used
erroneously (see #62007).
Since `on_entry` is now useless, we can also remove `BlockSets`, which
held the `gen`, `kill`, and `on_entry` bitvectors and replace it with a
`GenKill` struct. Variables of this type are called `trans` since they
represent a transfer function. `GenKill`s are stored contiguously in
`AllSets`, which reduces the number of bounds checks and may improve
cache performance: one is almost never accessed without the other.
Replacing `BlockSets` with `GenKill` allows us to define some new helper
functions which streamline dataflow iteration and the
dataflow-at-location APIs. Notably, `state_for_location` used a subtle
side-effect of the `kill`/`kill_all` setters to apply the transfer
function, and could be incorrect if a transfer function depended on
effects of previous statements in the block on `gen_set`.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The commit should have changed comments as well.
At the time of writting, it passes the tidy and check tool.
Revisions asked by eddyb :
- Renamed of all the occurences of {visit/super}_mir
- Renamed test structures `CachedMir` to `Cached`
Fixing the missing import on `AggregateKind`
|
|
|
|
|
|
|
|
|
|
|
|
MIR borrowck doesn't accept the example of iterating and updating a mutable reference
Fixes #46589.
r? @pnkfelix or @nikomatsakis
|
|
This avoids all sorts of confusing issues with using both `dest_place`
and `self` in the `propagate_call_return` function in the
`BitDenotation` implementation for `Borrows`.
|
|
|
|
Currently, `BitSet` doesn't actually know its own domain size; it just
knows how many words it contains. To improve things, this commit makes
the following changes.
- It changes `BitSet` and `SparseBitSet` to store their own domain size,
and do more precise bounds and same-size checks with it. It also
changes the signature of `BitSet::to_string()` (and puts it within
`impl ToString`) now that the domain size need not be passed in from
outside.
- It uses `derive(RustcDecodable, RustcEncodable)` for `BitSet`. This
required adding code to handle `PhantomData` in `libserialize`.
- As a result, it removes the domain size from `HybridBitSet`, making a
lot of that code nicer.
- Both set_up_to() and clear_above() were overly general, working with
arbitrary sizes when they are only needed for the domain size. The
commit removes the former, degeneralizes the latter, and removes the
(overly general) tests.
- Changes `GrowableBitSet::grow()` to `ensure()`, fixing a bug where a
(1-based) domain size was confused with a (0-based) element index.
- Changes `BitMatrix` to store its row count, and do more precise bounds
checks with it.
- Changes `ty_params` in `select.rs` from a `BitSet` to a
`GrowableBitSet` because it repeatedly failed the new, more precise
bounds checks. (Changing the type was simpler than computing an
accurate domain size.)
- Various other minor improvements.
|
|
`BitwiseOperator` is an unnecessarily low-level thing. This commit
replaces it with `BitSetOperator`, which works on `BitSet`s instead of
words. Within `bit_set.rs`, the commit eliminates `Intersect`, `Union`,
and `Subtract` by instead passing a function to `bitwise()`.
|
|
Currently we have two files implementing bitsets (and 2D bit matrices).
This commit combines them into one, taking the best features from each.
This involves renaming a lot of things. The high level changes are as
follows.
- bitvec.rs --> bit_set.rs
- indexed_set.rs --> (removed)
- BitArray + IdxSet --> BitSet (merged, see below)
- BitVector --> GrowableBitSet
- {,Sparse,Hybrid}IdxSet --> {,Sparse,Hybrid}BitSet
- BitMatrix --> BitMatrix
- SparseBitMatrix --> SparseBitMatrix
The changes within the bitset types themselves are as follows.
```
OLD OLD NEW
BitArray<C> IdxSet<T> BitSet<T>
-------- ------ ------
grow - grow
new - (remove)
new_empty new_empty new_empty
new_filled new_filled new_filled
- to_hybrid to_hybrid
clear clear clear
set_up_to set_up_to set_up_to
clear_above - clear_above
count - count
contains(T) contains(&T) contains(T)
contains_all - superset
is_empty - is_empty
insert(T) add(&T) insert(T)
insert_all - insert_all()
remove(T) remove(&T) remove(T)
words words words
words_mut words_mut words_mut
- overwrite overwrite
merge union union
- subtract subtract
- intersect intersect
iter iter iter
```
In general, when choosing names I went with:
- names that are more obvious (e.g. `BitSet` over `IdxSet`).
- names that are more like the Rust libraries (e.g. `T` over `C`,
`insert` over `add`);
- names that are more set-like (e.g. `union` over `merge`, `superset`
over `contains_all`, `domain_size` over `num_bits`).
Also, using `T` for index arguments seems more sensible than `&T` --
even though the latter is standard in Rust collection types -- because
indices are always copyable. It also results in fewer `&` and `*`
sigils in practice.
|
|
This requires the following changes.
- It moves parts of bitslice.rs into bitvec.rs: `bitwise()`,
`BitwiseOperator`, `bits_to_string()`.
- It changes `IdxSet` to just be a wrapper around `BitArray`.
- It changes `BitArray` and `BitVec` to use `usize` words instead of
`u128` words. (`BitSlice` and `IdxSet` already use `usize`.) Local
profiling showed `usize` was better.
- It moves some operations from `IdxSet` into `BitArray`:
`new_filled()`, `clear()`, `set_up_to()`, `trim_to()` (renamed
`clear_above()`), `words()` and `words_mut()`, `encode()` and
`decode(). The `IdxSet` operations now just call the `BitArray`
operations.
- It replaces `BitArray`'s iterator implementation with `IdxSet`'s,
because the latter is more concise. It also removes the buggy
`size_hint` function from `BitArray`'s iterator, which counted the
number of *words* rather than the number of *bits*. `IdxSet`'s
iterator is now just a thin wrapper around `BitArray`'s iterator.
- It moves some unit tests from `indexed_set.rs` to `bitvec.rs`.
|
|
|
|
Currently `Word` is `usize`, and there are various places in the code
that assume this.
This patch mostly just changes `usize` occurrences to `Word`. Most of
the changes were found as compile errors when I changed `Word` to a type
other than `usize`, but there was one non-obvious case in
librustc_mir/dataflow/mod.rs that caused bounds check failures before I
fixed it.
|
|
|
